一 爬虫介绍

近年来,随着网络应用逐渐扩展与深入,如何高效地获取网上数据成为了无数公司和个人的追求,在如今这大数据时代里,谁能掌握更多的数据,谁就可以获取更高的利益,而网络爬虫其中最为常用的一种手段就是从网上爬虫数据。
网络爬虫,即Web Spider,是一个很形象的名字,如果把互联网比喻成蜘蛛网,互联网中的数据比喻成蜘蛛网上的猎物,那么Spider就是在网上爬来爬去的蜘蛛。网络爬虫是通过网页的链接地址来寻找网页的,从网页的主页开始,读取网页的内容,找到在主页中的其他链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。如果把整个互联网当成一个网站,那么网上的蜘蛛就可以通过这个原理把互联网上所有的页面都抓取下来。
1、什么是互联网?
互联网其实是由一堆网络设备(比如: 网线、路由器、交换机、防火墙等等...)与一台台的计算机连接而成,就像一张蜘蛛网一样。
2、互联网建立的目的
互联网的核心价值: 数据是存放在一台台计算机中的,而互联网是把计算机互联到一起,也就是说把一台台计算机中的数据都捆绑到一起了,目的就是为了能够方便每台计算机彼此之间数据的传递与数据的共享,否则你只能拿到U盘或者是移动硬盘去别人的计算机上拷贝数据了。
3、什么是上网?
上网其实指的是有用户端(客户端)的计算机向目标计算机发送请求,将目标计算机的数据下载到客户端计算机的过程。
-
- 普通用户获取数据的方式:
浏览器提交请求 ---> 下载页面代码 ---> 解析/渲染成页面。 - 爬虫程序获取数据的方式:
模拟浏览器发送请求 ---> 下载页面代码 ---> 只提取有用的数据 ---> 存放于数据库中或文件中。 - 普通用户与爬虫程序的区别:
- 普通用户: 普通用户是通过打开浏览器访问网页,浏览器会接收所有的数据。
- 爬虫程序: 爬虫程序只提取网页代码中对我们有价值的数据。
- 普通用户: 普通用户是通过打开浏览器访问网页,浏览器会接收所有的数据。
- 普通用户获取数据的方式:
4、爬虫总结
-
- 爬虫的比喻:
如果我们把互联网比喻成一张大的蜘蛛网,那一台计算机上的数据就是蜘蛛网上的猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的猎物(数据)。 - 爬虫的定义:
伪装成浏览器向目标网站发送请求,获取响应资源后解析并提取有价值的数据的程序。 - 爬虫的价值:
互联网中最有价值的便是数据,例如: 天猫、淘宝、京东商品的商品信息,链家网的租房/房源信息,雪球网的证券投资信息等等...这些数据都代表了各个行业最有价值的东西,若谁掌握了行业内的第一手数据,那么谁就能成为这个行业的主宰。如果把互联网中的数据比喻成一座宝藏,那我们的爬虫课程就是教大家如何高效地挖掘这些宝藏,掌握了爬虫技能,你就能成为所有互联网信息公司的幕后老板,换言之,他们都是在免费为你提供有价值的数据。
- 爬虫的比喻:
5、 爬虫的应用

'''
1.通用爬虫: 通用爬虫是搜索引擎(Baidu、Google、Yahoo等)"抓取系统" 的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。
搜索引擎如何抓取互联网上的网站数据:
a) 目标网站主动向搜索引擎公司提供其网站的url。 b) 搜索引擎公司与DNS服务商合作,获取目标网站的url。 c) 目标网站主动挂靠在一些知名网站的友情链接中。 2.聚焦爬虫: 聚焦爬虫是根据指定的需求抓取网络上指定的数据。例如: 获取豆瓣上电影的名称和影评,而不是获取整张页面中所有的数据值。 3.数据分析的数据样本 4.机器学习的数据样本 '''
6、实现爬虫的编程语言
'''
1.python:
可以实现爬虫。python实现和处理爬虫语法简单,代码优美,支持的模块繁多,学习成本低,具有非常强大的框架(scrapy等)且一句难以言表的好!没有但是!
2.java:
可以实现爬虫。java可以非常好的处理和实现爬虫,是唯一可以与python并驾齐驱且是python的头号劲敌。但是java实现爬虫代码较为臃肿,重构成本较大。
3.c、c++:
可以实现爬虫。但是使用这种方式实现爬虫纯粹是是某些人(大佬们)能力的体现,却不是明智和合理的选择。
4.php:
可以实现爬虫。php被号称是全世界最优美的语言(当然是其自己号称的,就是王婆卖瓜的意思),但是php在实现爬虫中支持多线程和多进程方面做的不好。
'''

二 爬虫的基本流程
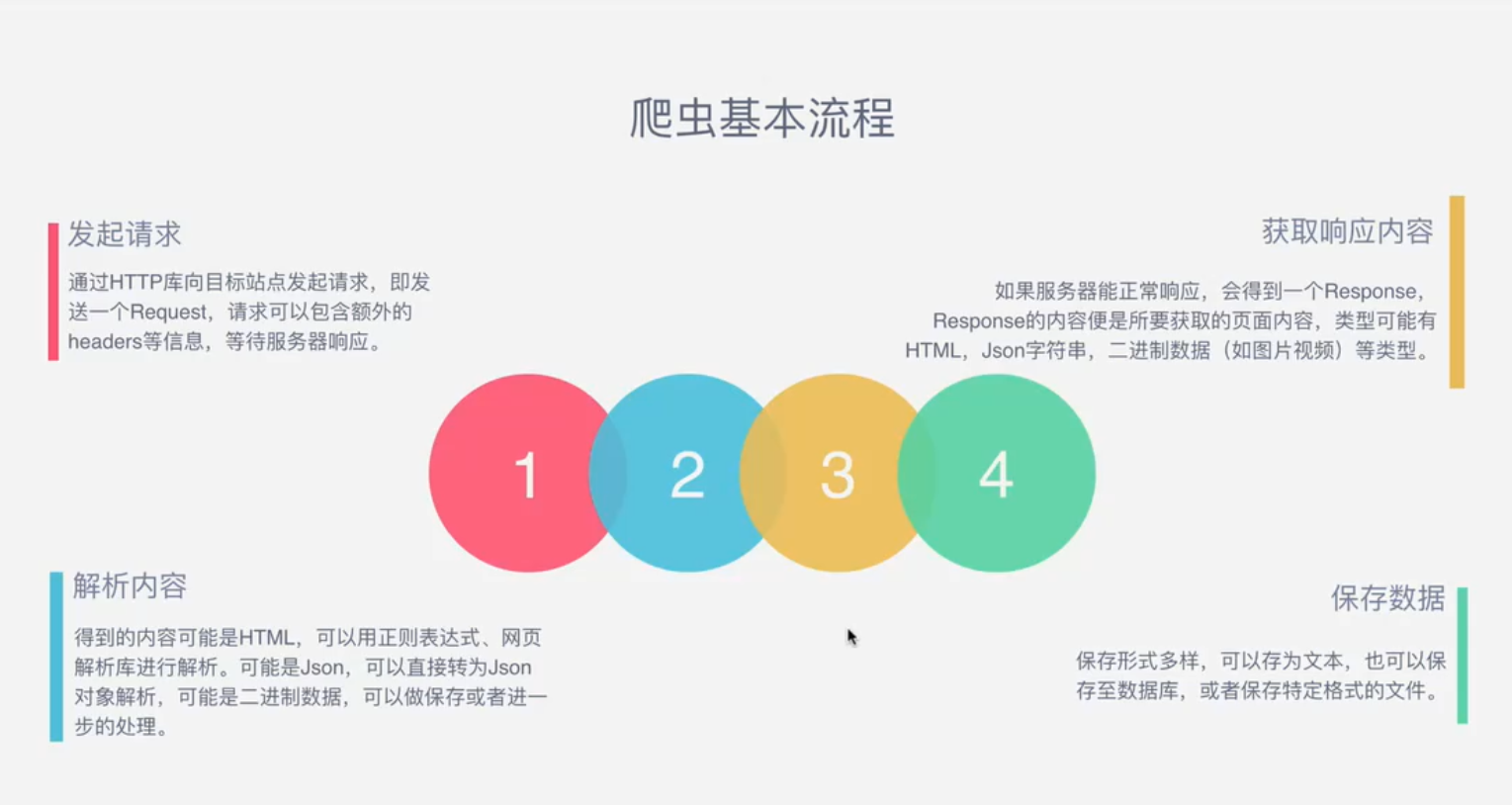
爬虫的基本流程其实就是模拟浏览器往目标站点发送请求,那浏览器发送的是http协议数据格式的请求,http协议的底层其实就是TCP协议数据格式。其实浏览器是一个套接字客户端,访问的目标站点是一个套接字服务端。那套接字客户端要与套接字服务端建立链接,得先拿到 ”客户端的ip和端口“ 与 ”服务端的ip和端口“ ,然后套接字客户端才向套接字服务端发送一次connection的请求,通过三次握手建立双向链接,此时形成了两条管道,一条是客户端往服务端发送数据的管道,另一条是服务端接收到请求后把数据返回给客户端的管道。那浏览器会沿着第一条管道往服务端发送的http协议的请求,服务端会把响应数据打包成http协议的数据格式,沿着第二条管道返回给客户端。这就是爬虫的基本流程。
'''
1.发起请求:
使用http库向目标站点发起请求,即发送一个Request
Request包含:请求头、请求体等...
2.获取响应内容
如果服务器能正常响应,则会得到一个Response
Response包含:html,json,图片,视频等...
3.解析内容
解析html数据:
正则表达式,第三方解析库如Beautifulsoup,pyquery等
解析json数据:
json模块
解析二进制数据:
以b的方式写入文件
4.保存数据
数据库
文件
'''
三 请求与响应

'''
URL:
即统一资源定位符,也就是我们说的网址,统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。
互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
URL的格式由三部分组成:
①第一部分是协议(或称为服务方式)。
②第二部分是存有该资源的主机IP地址(有时也包括端口号)。
③第三部分是主机资源的具体地址,如目录和文件名等
http协议:
https://www.cnblogs.com/kermitjam/p/10432198.html
robots协议:
https://www.cnblogs.com/kermitjam/articles/9692568.html
Request:
用户将自己的信息通过浏览器(socket client)发送给服务器(socket server)
Response:
服务器接收请求,分析用户发来的请求信息,然后返回数据(返回的数据中可能包含其他链接,如:图片,js,css等)
ps:
浏览器在接收Response后,会解析其内容来显示给用户,而爬虫程序在模拟浏览器发送请求然后接收Response后,是要提取其中的有用数据。
'''
四 Request
1、请求方式
'''
常用的请求方式:
GET,POST
其他请求方式:
HEAD,PUT,DELETE,OPTHONS
POST与GET请求最终都会拼接成这种形式:
k1=xxx&k2=yyy&k3=zzz
POST请求的参数放在请求体内:
可用浏览器查看,存放于form data内。而GET请求的参数直接放在url后。
示例:
演示登录与不登录获取的数据,以及请求方式。
'''
五.爬取示例
1.爬取梨视频
'''''' ''' 视频选项: 1.梨视频 ''' # import requests # # # 往视频源地址发送请求 # response = requests.get( # 'https://video.pearvideo.com/mp4/adshort/20190625/cont-1570302-14057031_adpkg-ad_hd.mp4') # # # 打印二进制流,比如图片、视频等数据 # print(response.content) # # # 保存视频到本地 # with open('视频.mp4', 'wb') as f: # f.write(response.content) ''' 1、先往梨视频主页发送请求 https://www.pearvideo.com/ 解析获取所有视频的id: video_1570302 re.findall() 2、获取视频详情页url: 惊险!男子抢上地铁滑倒,就脚进去了 https://www.pearvideo.com/video_1570302 揭秘坎儿井 https://www.pearvideo.com/video_1570107 ''' import requests import re # 正则,用于解析文本数据 # 1、先往梨视频主页发送请求 response = requests.get('https://www.pearvideo.com/') # print(response.text) # re正则匹配获取所有视频id # 参数1: 正则匹配规则 # 参数2: 解析文本 # 参数3: 匹配模式 res_list = re.findall('<a href="video_(.*?)"', response.text, re.S) # print(res_list) # 拼接每一个视频详情页url for v_id in res_list: detail_url = 'https://www.pearvideo.com/video_' + v_id # print(detail_url) # 对每一个视频详情页发送请求获取视 频源url response = requests.get(url=detail_url) # print(response.text) # 解析并提取详情页视频url # 视频url video_url = re.findall('srcUrl="(.*?)"', response.text, re.S)[0] print(video_url) # 视频名称 video_name = re.findall( '<h1 class="video-tt">(.*?)</h1>', response.text, re.S)[0] print(video_name) # 往视频url发送请求获取视频二进制流 v_response = requests.get(video_url) with open('%s.mp4' % video_name, 'wb') as f: f.write(v_response.content) print(video_name, '视频爬取完成')
2.爬取豆瓣网
'''''' ''' https://movie.douban.com/top250?start=0&filter= https://movie.douban.com/top250?start=25&filter= https://movie.douban.com/top250?start=50&filter= 1.发送请求 2.解析数据 3.保存数据 ''' import requests import re # 爬虫三部曲 # 1.发送请求 def get_page(base_url): response = requests.get(base_url) return response # 2.解析文本 def parse_index(text): res = re.findall('<div class="item">.*?<em class="">(.*?)</em>.*?<a href="(.*?)">.*?<span class="title">(.*?)</span>.*?导演:(.*?)</p>.*?<span class="rating_num".*?>(.*?)</span>.*?<span>(.*?)人评价</span>.*?<span class="inq">(.*?)</span>', text, re.S) # print(res) return res # 3.保存数据 def save_data(data): with open('douban.txt', 'a', encoding='utf-8') as f: f.write(data) # main + 回车键 if __name__ == '__main__': # num = 10 # base_url = 'https://movie.douban.com/top250?start={}&filter='.format(num) num = 0 for line in range(10): base_url = f'https://movie.douban.com/top250?start={num}&filter=' num += 25 print(base_url) # 1.发送请求,调用函数 response = get_page(base_url) # 2.解析文本 movie_list = parse_index(response.text) # 3.保存数据 # 数据的格式化 for movie in movie_list: # print(movie) # 解压赋值 # 电影排名、电影url、电影名称、导演 - 主演 - 类型、电影评分、评价人数、电影简介 v_top, v_url, v_name, v_daoyan, v_point, v_num, v_desc = movie # v_top = movie[0] # v_url = movie[1] moive_content = f''' 电影排名: {v_top} 电影url: {v_url} 电影名称: {v_name} 导演主演: {v_daoyan} 电影评分: {v_point} 评价人数: {v_num} 电影简介: {v_desc} \n ''' print(moive_content) # 保存数据 save_data(moive_content)