一爬虫原理
爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来。想抓取什么?这个由你来控制它咯。
比如它在抓取一个网页,在这个网中他发现了一条道路,其实就是指向网页的超链接,那么它就可以爬到另一张网上来获取数据。这样,整个连在一起的大网对这之蜘蛛来说触手可及,分分钟爬下来不是事儿。
1.什么是互联网?
指的是由一堆网络设备,把一台台的计算机互联网到一起称之为互联网。
2.互联网建立的目的?
互联网建立的目的是为了数据的传递以及数据的分享。
3.什么是数据?
..........
4.上网的过程
1.普通用户获取数据方式:
打开浏览器-->往目标站点发送请求-->获取响应数据-->渲染到浏览器中
2.爬虫程序:
模拟浏览器-->往目标站点发送请求-->获取响应数据-->提取有价值的数据-->持久化到数据中
5.浏览网页过程
http协议的请求。https=http+ssl
在用户浏览网页的过程中,我们可能会看到许多好看的图片,比如 http://image.baidu.com/ ,我们会看到几张的图片以及百度搜索框,这个过程其实就是用户输入网址之后,经过DNS服务器,找到服务器主机,向服务器发出一个请求,服务器经过解析之后,发送给用户的浏览器 HTML、JS、CSS 等文件,浏览器解析出来,用户便可以看到形形色色的图片了。
因此,用户看到的网页实质是由 HTML 代码构成的,爬虫爬来的便是这些内容,通过分析和过滤这些 HTML 代码,实现对图片、文字等资源的获取。
6.爬虫的全过程
— 发送请求 (需要请求库:Requests请求库、Selenium请求库、rullib)
— 获取响应数据 (只要往服务器发送请求,请求通过后会返回响应数据)
— 解析并提取数据 (需要解析库:re(正则)、BeautifulSoup4、Xpath)
— 保存到本地 (文件处理、数据库、MongoDB)
7.URL的含义
URL即统一资源定位符,也就是我们说的网址,统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
URL的格式由三部分组成:
-- 协议(或称为服务方式)
-- 存有该资源的主机IP地址(有时也包括端口号)
-- 主机资源的具体地址,如目录和文件名等
爬虫爬取数据时必须要有一个目标URL才可以获取数据,因此,它是爬虫获取数据的基本依据,准确理解它的含义对爬虫学习有很大帮助。
二 Requests请求库
1.什么是Requests
Requests 是用Python语言编写,基于urllib,采用Apache2 Licensed开源协议的 HTTP 库。它比urllib 更加方便,可以节约我们大量的工作,完全满足HTTP测试需求。
2.发送请求
1)各种请求方式
①GET:请求指定的页面信息,并返回实体主体,直接发送请求获取数据。
②POST:请求服务器接收所指定的文档作为对所标识的URI的新的从属实体
③HEAD: 只请求页面的首部。
④PUT: 从客户端向服务器传送的数据取代指定的文档的内容。
⑤DELETE: 请求服务器删除指定的页面。
使用方法:
import requests
requests.get('http://httpbin.org/post')
requests.post('http://httpbin.org/post')
requests.put('http://httpbin.org/put')
requests.delete('http://httpbin.org/delete')
requests.head('http://httpbin.org/get')
requests.options('http://httpbin.org/get')
2)属性方法

3)相应状态码
1xx:临时响应(表示临时响应并需要请求者继续执行操作的状态代码)。
2xx:成功响应(表示成功处理了请求的状态代码)。
3xx:重定向响应(表示要完成请求,需要进一步操作。通常,这些状态代码用来重定向).
4xx:请求错误(这些状态代码表示请求可能出错,妨碍了服务器的处理).
5xx:服务器错误(这些状态代码表示服务器在尝试处理请求时发生内部错误。这些错误可能是服务器本身的错误,而不是请求出错)。
常见的响应码:200 - 服务器成功返回网页,404 - 请求的网页不存在,503 - 服务不可用
4)get方法:requests.get(url,params=None,**kwargs)
url:必填,模拟获取页面的链接
params:url 中的额外参数,字典或字节流格式,无需对其编码,常用于发送 GET 请求时使用
**kwargs :12个控制访问的参数
data:字典类型,指定表单信息,常用于发送 POST 请求时使用
1 import requests 2 url = 'http://www.httpbin.org/post' 3 data = { 4 'users':'value1', 5 'key':'value2' 6 } 7 response = requests.post(url=url,data=data) 8 print(response.text)
headers:字典类型,指定请求头部
1 #传递一个 dict 给 headers 参数就可以,Requests 不会基于定制 header 的具体情况改变 2 #自己的行为。只不过在最后的请求中,所有的header信息都会被传递进去。 3 import requests 4 headers = { 5 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36', 6 } 7 response = requests.get("https://www.zhihu.com/expiore",headers=headers) 8 print(response.text)
代理设置proxies:字典类型,指定使用的代理
1 #设置 proxies 参数来配置代理,同时也可以设置代理密码认证,还可以使用 SOCKS 代理 2 import requests 3 proxies= { 4 "http":"http://127.0.0.1:9999", (代理地址,端口) 5 "https":"http://127.0.0.1:8888" 6 } 7 response = requests.get("https://www.baidu.com",proxies=proxies) 8 print(response.text) 9 ''' 10 proxies = {"http": "http://user:[email protected]:3128/",} 11 proxies = { 12 'http': 'socks5://user:pass@host:port', 13 'https': 'socks5://user:pass@host:port' 14 } 15 '''
cookies:字典类型,指定 Cookie,会话维持
1 #获取Cookie,用cookies参数来发送到服务器 2 import requests 3 response = requests.get("URL") 4 print(response.cookies) #获取cookie 5 #print(response.cookies['example_cookie_name']) 获取某个具体的cookie 6 for key,value in response.cookies.items():#获取所有cookie的两个属性 7 print(key + '=' + value) 8 cookies = {'cookies_are': 'working'} #设置cookie参数 9 request = requests.get('http://httpbin.org/cookies', cookies=cookies) 10 11 #会话保持 12 ''' 13 cookie的一个作用就是可以用于模拟登陆,做会话维持,使得模拟登陆时,始终在一个浏览器页面。 14 获取cookie,以cookie的内容进行网站登陆,所以如果向同一主机发送多个请求,底层的 TCP 连接将会被重用,从而带来显著的性能提升。 15 ''' 16 import requests 17 s = requests.Session() #Session()模拟服务器设置与登陆过程,在服务器中储存用户登陆信息。 18 s.get("http://httpbin.org/cookies/set/sessioncookie/123456") 19 response = s.get("http://httpbin.org/cookies") 20 print(response.text) 21 #会话可以用作前后文管理器,确保with区块退出后会话能被关闭,即使发生了异常也一样。 22 with requests.Session() as s: 23 s.get('http://httpbin.org/cookies/set/sessioncookie/123456789')
认证设置auth:元组类型,指定登陆时的账号和密码
1 import requests 2 url = 'http://www.httpbin.org/basic-auth/user/password' 3 auth = ('user','password') 4 response = requests.get(url=url,auth=auth) 5 print(response.text)
证书验证verify:布尔类型,指定请求网站时是否需要进行证书验证,默认为 True,不希望进行证书验证时,则需要设置为 False
1 ''如果你将 verify 设置为 False,Requests 也能忽略对 SSL 证书的验证,但是会产生警告''' 2 requests.get('https://kennethreitz.org', verify=False) 3 #1、忽略警告 4 #2、传入证书进行验证 5 import requests 6 from requests.packages import urllib3 7 urllib3.disable_warnings() 8 response = requests.get("https://www.12306.cn",verify=False) 9 print(response.status_code) 10 >>>200 11 requests.get('https://github.com', verify='/path/to/certfile')如果 verify #设为文件夹路径,文件夹必须通过 OpenSSL 提供的 c_rehash 工具处理。 12 #s = requests.Session() 或者将其保持在会话中 13 #s.verify = '/path/to/certfile'
files:文件上传
1 import requests #文件上传用post操作 2 3 files = {'files':open('favicon.ico','rb')} #用files(自由指定上传的文件名称)、open的方法吧文件读取出来 4 response = requests.post('http://httpbin.org/post',files=files) 5 print(response.text)
超时设置timeout:指定超时时间,若超过指定时间没有获得响应,则抛出异常
1 """告诉requests在经过以timeout参数设定的秒数时间之后停止等待响应,如果服务器在timeout 秒内没有应答,将会引发一个异常 """ 2 import requests 3 request = requests.get('http://www.google.com.hk', timeout=0.01) 4 print(request.url)
异常处理:Requests显式抛出的异常都继承自requests.exceptions.RequestExceptio
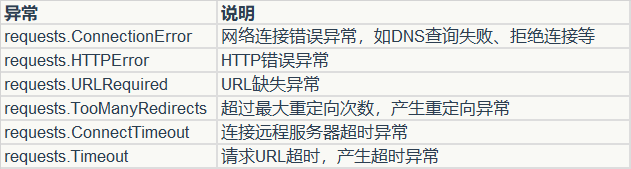
5)请求头信息
User-Agent:用户代理(证明是通过电脑设备及浏览器发送的请求)
Cookies:登录用户真实信息(证明你是目标网站的用户)
requests.Session()维持Cookies信息
Referer:上一次访问的url(证明你是从目标网站跳转过来的)
6)请求体
POST请求才会有请求体
Form Data{'user':'Berlin','pwd':'123'}