一、python数据类型与json数据类型转换
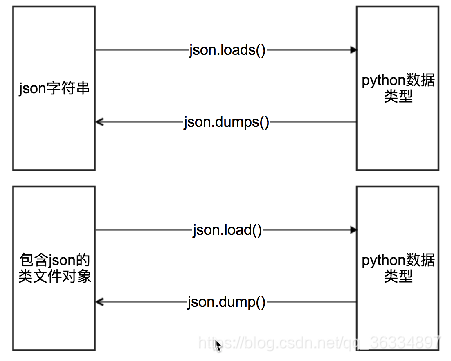
- json.loads(json字符串) 将json类型转换为字典类型
- json.dumps(python类型) 将python类型转换为json类型
- json.load(json字符串) 将j类文件对象转换为字典类型
- json.dump(python类型) 将json类型转换为类文件对象
注
具有read()或者write()方法的对象就是类文件对象
f = open(“a.txt”,”r”) f就是类文件对象
二、抓取豆瓣中每一页的美剧电视剧并保存
import requests
import json
class DouBan():
def __init__(self):
self.headers = {"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Mobile Safari/537.36"}
self.start_url = 'https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=电视剧&start={}&countries=美国'
def parse_url(self,url): # 获取第一页数据
'''获取响应数据'''
response = requests.get(url,headers=self.headers)
print(url)
return response.content.decode() # 返回字符串型
def get_data(self,html_str):
'''提取数据'''
html_dict = json.loads(html_str) # 返回字典类型
html_list = html_dict['data'] # html_list均是字典类型
return html_list
def save_html(self,html_str,html_list):
for temp_html in html_list: # html为字典类型
with open('douban.txt','a',encoding='utf-8') as f:
f.write(json.dumps(temp_html,ensure_ascii=False))
f.write('\n') # 每行存储一个信息
print('保存成功')
def run(self):
'''控制整体的运行'''
num = 0
while True:
# 1.创建url
url = self.start_url.format(num)
#2.发送请求,获取响应
html_str = self.parse_url(url)
#3.提取数据
html_list = self.get_data(html_str)
#4.保存数据
self.save_html(html_str,html_list)
if len(html_list) < 20:
break
#4.构造下一页url
num += 20
if __name__ == '__main__':
douban = DouBan()
douban.run()
