为什么要使用压缩
随着数据量越来越大,对数据如何处理使得我们提高数据处理效率,如何选择和使用压缩就显得尤为重要。
压缩的优点:
1)减少文件大小(reduce file size)
2)节省磁盘空间(svae disk space)
3)增加网络传输速度及效率(Increase tansfer speed at a given data rate)
压缩技术
压缩分为无损压缩(Lossless Compression)和有损压缩(Lossy Compression)。
无损压缩一般适用于用户行为数据这类不允许数据丢失的业务场景、
有损压缩一般适用于大文件的压缩,例如图片、视频的处理,优点是压缩率和压缩比都比较高,可以节省更多的空间。
以离线数据处理为例:
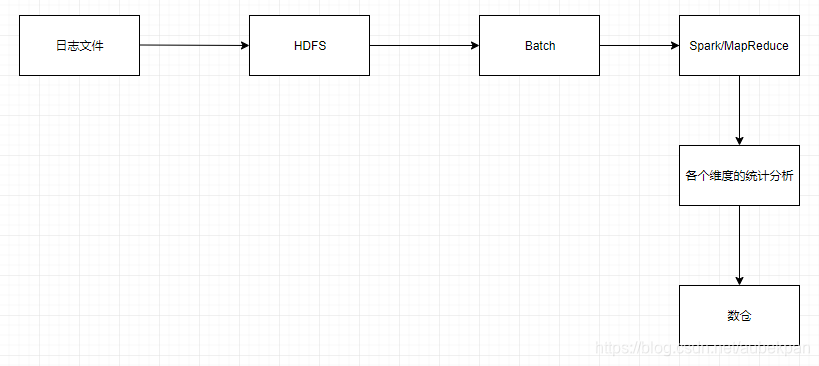
分为三个业务场景,输入、中间、输出。日志采集压缩输入HDFS,解压通过Spark/MapReduce计算,再压缩存入对应的数据源。
压缩对比
压缩可以带来入前文所说的好处,但是,在压缩的同时对CPU的消耗也相对较高,那么在压缩的时候就要做最优选择,做性价比最高的压缩处理。
| 压缩格式 | 压缩工具 | 算法 | 文件名扩展 | 是否支持分割 |
|---|---|---|---|---|
| gzip | gzip | default | .gz | × |
| bzip2 | bzip2 | bzip2 | .bz2 | √ |
| LZO | LZO | LZO | .lzo | √(Yes if indexed) |
| LZ4 | LZ4 | LZ4 | .lz4 | × |
| Snappy | N/A | Snappy | .snappy | × |
压缩大小比较如下:
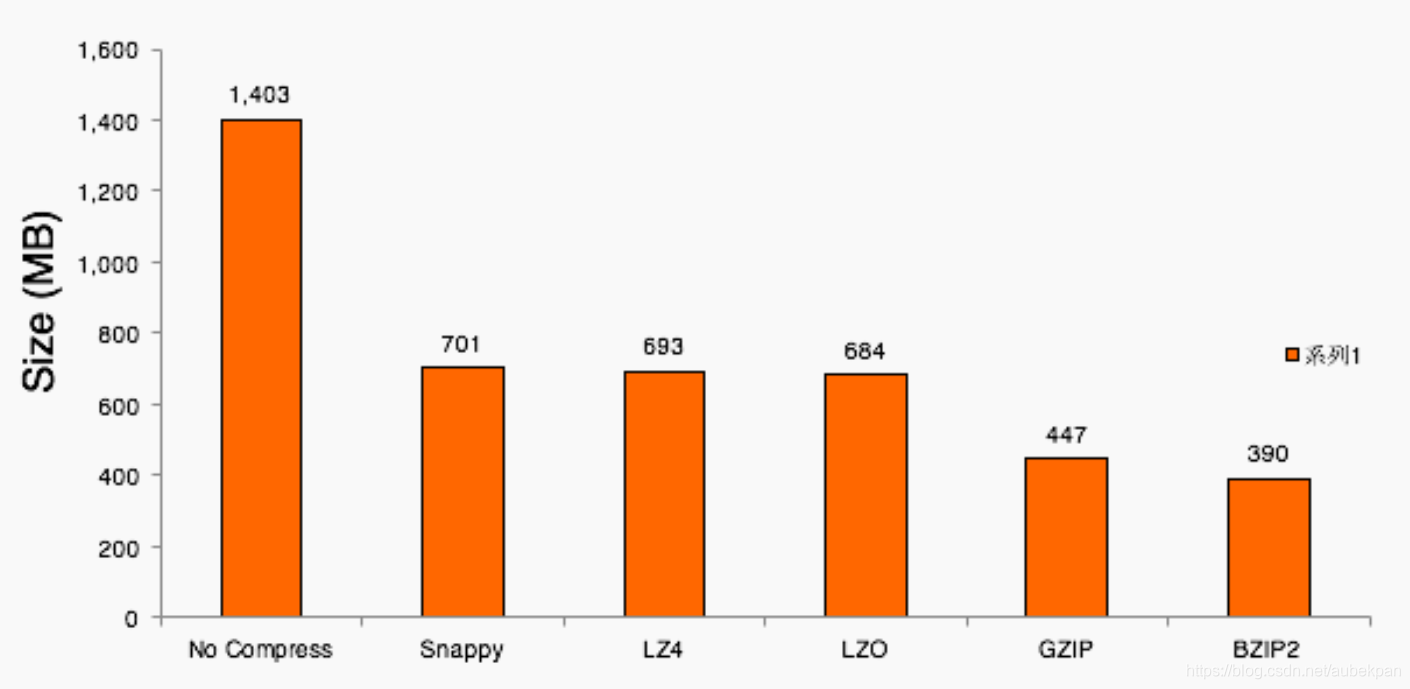
Compression Ratio: BZIP2 > GZIP > LZO
压缩时间对比如下:
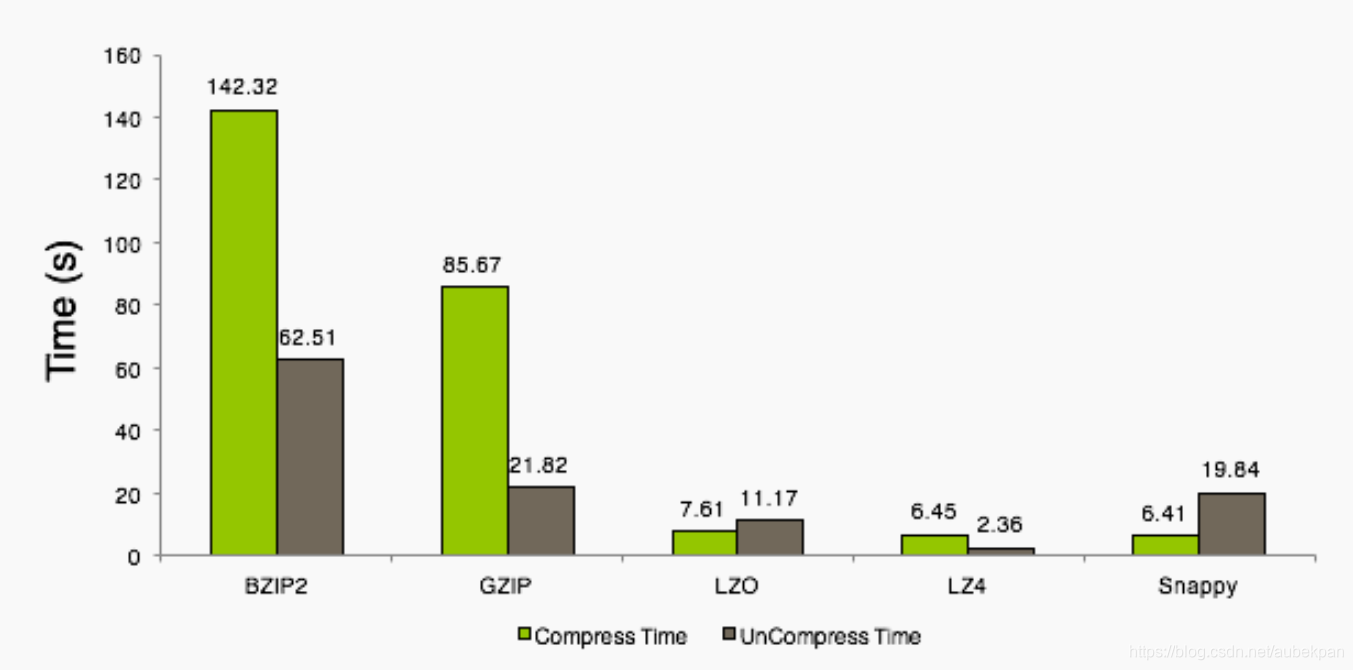
压缩比和压缩速度成反比(因为你的压缩比越高,那么你压缩过后的数据也就越少,这样压缩所需要耗费的时间也就越多)
比如:BZIP2压缩效果最好,但是压缩解压缩时间最慢
Compression Speed:LZO > GZIP > BZIP2
优缺点说明
gzip
优点:
压缩率比较高,
解压速度也比较快
hadoop本身支持,linux系统都自带gzip命令
缺点:
不支持split
bzip2
优点:
压缩比较高
支持split
Hadoop本身支持,但不支持native
缺点:
压缩/解压速度比较慢
LZO
优点:
压缩/解压速度也比较快,合理的压缩率
支持分片,是Hadoop中流行的压缩格式
支持Hadoop native库
缺点:
压缩率比gzip要低一些
Hadoop本身不支持,需要安装
snappy
优点:
高速压缩速度和合理的压缩率
支持hadoop native库
缺点:
不支持split
压缩率比gzip要低
hadoop本身不支持,需要安装
linux系统下没有对应的命令
常用Codec
| 压缩格式 | 类 |
|---|---|
| Zlib | org.apache.hadoop.io.compress.DefaultCodec |
| Gzip | org.apache.hadoop.io.compress.GzipCodec |
| Bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| Lzo | com.hadoop.compression.lzo.LzoCodec |
| LZ4 | org.apache.hadoop.io.compress.Lz4Codec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
压缩在Hadoop的配置
core-site.xml
此处为了方便阅读换行书写压缩类,生产上注意不要留有空格
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec
</value>
</property>
mapred-site.xml(只配了最终的输出,中间输出的自己去配)
<property>
<name>mapreduce.output.fileoutputformat.compress</name>
<value>true</value>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress.codec</name>
<value>org.apache.hadoop.io.compress.BZip2Codec</value>
</property>
注意: 该配置文件是reduce的 如果是map会是mapreduce.map.output