1.4 高可用Flum-NG配置案例failover
在完成单点的Flume NG搭建后,下面我们搭建一个高可用的Flume NG集群,架构图如下所示:
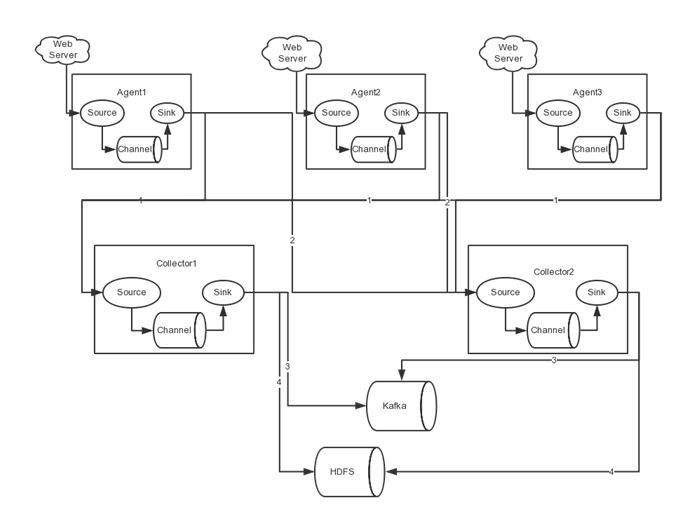
图中,我们可以看出,Flume的存储可以支持多种,这里只列举了HDFS和Kafka(如:存储最新的一周日志,并给Storm系统提供实时日志流)。
1.4.1、角色分配
Flume的Agent和Collector分布如下表所示:
| 名称 |
HOST |
角色 |
| Agent1 |
node01 |
Web Server |
| Collector1 |
node02 |
AgentMstr1 |
| Collector2 |
node03 |
AgentMstr2 |
图中所示,Agent1数据分别流入到Collector1和Collector2,Flume NG本身提供了Failover机制,可以自动切换和恢复。在上图中,有3个产生日志服务器分布在不同的机房,要把所有的日志都收集到一个集群中存储。下 面我们开发配置Flume NG集群
1.4.2、node01安装配置flume与拷贝文件脚本
将node03机器上面的flume安装包以及文件生产的两个目录拷贝到node01机器上面去
node03机器执行以下命令
cd /export/servers
scp -r apache-flume-1.6.0-cdh5.14.0-bin/ node01:$PWD
scp -r shells/ taillogs/ node01:$PWD
node01机器配置agent的配置文件
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/conf
vim agent.conf
#agent1 name
agent1.channels = c1
agent1.sources = r1
agent1.sinks = k1 k2
#
##set gruop
agent1.sinkgroups = g1
#
##set channel
agent1.channels.c1.type = memory
agent1.channels.c1.capacity = 1000
agent1.channels.c1.transactionCapacity = 100
#
agent1.sources.r1.channels = c1
agent1.sources.r1.type = exec
agent1.sources.r1.command = tail -F /export/servers/taillogs/access_log
#
agent1.sources.r1.interceptors = i1 i2
agent1.sources.r1.interceptors.i1.type = static
agent1.sources.r1.interceptors.i1.key = Type
agent1.sources.r1.interceptors.i1.value = LOGIN
agent1.sources.r1.interceptors.i2.type = timestamp
#
## set sink1
agent1.sinks.k1.channel = c1
agent1.sinks.k1.type = avro
agent1.sinks.k1.hostname = node02
agent1.sinks.k1.port = 52020
#
## set sink2
agent1.sinks.k2.channel = c1
agent1.sinks.k2.type = avro
agent1.sinks.k2.hostname = node03
agent1.sinks.k2.port = 52020
#
##set sink group
agent1.sinkgroups.g1.sinks = k1 k2
#
##set failover
agent1.sinkgroups.g1.processor.type = failover
agent1.sinkgroups.g1.processor.priority.k1 = 10
agent1.sinkgroups.g1.processor.priority.k2 = 1
agent1.sinkgroups.g1.processor.maxpenalty = 10000
#
1.4.3、node02与node03配置flumecollection
node02机器修改配置文件
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/conf
vim collector.conf
#set Agent name
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#
##set channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#
## other node,nna to nns
a1.sources.r1.type = avro
a1.sources.r1.bind = node02
a1.sources.r1.port = 52020
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = Collector
a1.sources.r1.interceptors.i1.value = node02
a1.sources.r1.channels = c1
#
##set sink to hdfs
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path= hdfs://node01:8020/flume/failover/
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.writeFormat=TEXT
a1.sinks.k1.hdfs.rollInterval=10
a1.sinks.k1.channel=c1
a1.sinks.k1.hdfs.filePrefix=%Y-%m-%d
#
node03机器修改配置文件
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/conf
vim collector.conf
#set Agent name
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#
##set channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#
## other node,nna to nns
a1.sources.r1.type = avro
a1.sources.r1.bind = node03
a1.sources.r1.port = 52020
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = Collector
a1.sources.r1.interceptors.i1.value = node03
a1.sources.r1.channels = c1
#
##set sink to hdfs
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path= hdfs://node01:8020/flume/failover/
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.writeFormat=TEXT
a1.sinks.k1.hdfs.rollInterval=10
a1.sinks.k1.channel=c1
a1.sinks.k1.hdfs.filePrefix=%Y-%m-%d
1.4.4、顺序启动命令
node03机器上面启动flume
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin
bin/flume-ng agent -n a1 -c conf -f conf/collector.conf -Dflume.root.logger=DEBUG,console
node02机器上面启动flume
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin
bin/flume-ng agent -n a1 -c conf -f conf/collector.conf -Dflume.root.logger=DEBUG,console
node01机器上面启动flume
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin
bin/flume-ng agent -n agent1 -c conf -f conf/agent.conf -Dflume.root.logger=DEBUG,console
node01机器启动文件产生脚本
cd /export/servers/shells
sh tail-file.sh
1.4.5、 FAILOVER测试
下面我们来测试下Flume NG集群的高可用(故障转移)。场景如下:我们在Agent1节点上传文件,由于我们配置Collector1的权重比Collector2大,所以 Collector1优先采集并上传到存储系统。然后我们kill掉Collector1,此时有Collector2负责日志的采集上传工作,之后,我 们手动恢复Collector1节点的Flume服务,再次在Agent1上次文件,发现Collector1恢复优先级别的采集工作。具体截图如下所 示:
Collector1优先上传
HDFS集群中上传的log内容预览
Collector1宕机,Collector2获取优先上传权限
重启Collector1服务,Collector1重新获得优先上传的权限