是什么?
数据结构和算法是一种思想,提高效率和性能,
面对新的问题,大概有一个思路,去哪个方向去解决
算法的概念
算法是计算机处理信息的本质,(简单的说,就是把解决问题的思路用程序实现)计算机程序本质上是一个算法来告诉计算机确切的步骤来执行一个指定的任务。
算法是独立存在的一种解决问题的方法和思想(语言并不重要,重要的思想)
五大特性
- 输入:有0~多个输入
- 输出: 至少一个或多个输出
- 有穷性:算法在有限的步骤会结束,而不是无线的步骤;并且每一个步骤就可以在接受的时间内完成
- 确定性: 算法的每一个步骤都有确定的含义,不会出现二义性
- 可行性: 算法的每一步都是可行的,每一步都能够执行有限的次数完成(可以实现的)
算法的效率衡量
执行时间反应算法效率?硬件设施? 存储空间?
时间复杂度 >反映的是一个趋势
O = n(规模)^基本运算数量
O = K*n^3+C- 最坏时间复杂度:最坏的计算步骤
- 最好时间复杂度:最理想的计算步骤
- 平均时间复杂度:平均的计算步骤
- 最坏时间复杂度提供了一种保障,一次主要关注他
- 计算时间复杂度
- 基本操作, 只有常数项,认为时间复杂度为O(1)
- 顺序结构,加法计算
- 循环结构,乘法计算
- 分支结构(if),取最大值
- 保留最高次项,其他次要项和常熟可以忽略
- 没有特殊说明,一般是最坏时间复杂度
常见时间复杂度 大O计算
注意:log2n 以2为底的对数
执行次数函数举例|阶|非正式术语
-|-|-
12|O(1)|常数阶
2n+3|O(n)|线性阶
3n^2+2n+1|O(n^2)|平方阶
5log2n+20|O(logn)|对数阶
2n+3nlog2n+19|O(nlogn)|nlogn阶
6n^3+2n^2+3n+4|O(n^3)|立方阶
2^n|O(2^N)|指数阶
所消耗时间从小到大排序
O(1)<O(logn)<O(n)<O(nlogn)<O(n^2)<O(n^3)<O(2^n)<O(n!)<O(n^n)- 空间复杂度
- 是对一个算法在运行过程中临时占用存储空间大小的一个量度,同样反映的是一个趋势
- 计算方法与 时间复杂度 类似
数据结构
数据是一个独立的概念,将其进行分类后的程序设计语言的基本类型(int,float),数据元素之间不是独立的,存在特定的关系,这些关系便是结构。
程序 = 算法 + 数据结构
抽象数据类型 ADT (Abstract Data Type)
把数据类型和数据类型的运算捆绑在一起
最常用的数据运算:
- 插入
- 删除
- 修改
- 查询
- 排序
线性表包括链表和顺序表
顺序表
按照顺序(连续)来存储
- 基本顺序布局
- 元素外置顺序表
顺序表需要完整的信息包括两部分,一:表头信息(容量和当前存储的个数)
实现方式
- 一体式
表头和数据区已连续的方式存储在一起
元素存储取替换(整体变迁) - 分离式
表头和数据区已 分开存储 通过连接来关联
元素存储取替换(表头和数据区链接地址更新)
元素存储区扩充策略:(动态顺序表)
- 每次扩充增加固定的存储位置,特点:节省空间,扩充操作频繁
- 每次扩充容量加倍的存储位置,特点:减少扩充操作次数,空间资源浪费
- 以空间换时间,推荐加倍的方式扩充
链表
0x11('数据区','0x34') 0x34('数据区','下一个节点的内存地址')
-单向循环链表
尾节点.next 重新指向头节点
在进行操作的时候,要注意头结点 和尾节点 的关联
- 双向链表
(前驱节点区 数据区 后继节点区)尾节点指向None - 双向循环链表
栈
是一种容器
只允许在一段进行操作,因而是一种 后进先出(LIFO)的原理运作
队列
是一种先进先出的的线性表
双端队列
头和尾 都可以存 和 取
排序算法
排序算法的稳定性 :稳定排序算法会让原本相等键值的记录维持相对的次序
冒泡排序
O(n**2)
def bubble_sort (alist):
for i in range(len(alist)-1,0,-1):
for j in range(i):
if alist[j] >alist[j+1]:
alist[j],alist[j+1] = alist[j+1],alist[j]
选择排序
O(n**2)
def bubble_sort(alist):
for i in range(len(alist)):
for j in range(i+1,len(alist)):
if alist[i] > alist[j]:
alist[i],alist[j] = alist[j],alist[i]
# [16,3,4,4,234,]插入排序
def insert_sort(alist):
for i range(1,len(alist)):
for j in range(0,i):
if alist[i] < alist[j]:
alist[i],alist[j] = alist[j],alist[i]希尔排序
基于插入排序实现的
def shell_sort(alist):
grap = int(len(alist)/2)
i = 1
while i>0:
if alist[i] < alist[i-grap]:
alist[i],alist[i=grap] = alist[i-grap],alist[i]
i-= grap
快速排序
时间复杂度 O(n**2)
def quick_short(alist,first,last):
if first >= last:
return
mid_value = alist[first]
low = first
high = last
while low < high:
while low < high and alist[high] >= mid_value:
high -= 1
alist[low] = alist[high]
while low < high and alist[low] < mid_value:
low += 1
alist[high] = alist[low]
alist[low] = mid_value
# 递归
# 对左边快速排序
quick_short(alist,first,low-1)
# 对右边快排
quick_short(alist,low+1 ,last) 注意递归思想的运用
归并排序
def marge_sort(alist):
mid = len(alist)//2
if len(alist) <= 1:
return alist
left = marge_sort(alist[:mid])
right = marge_sort(alist[mid:])
# 将两个 合并为一个新的
left_pointer,right_pointer = 0,0
result = []
while left_pointer < len(left) and right_pointer < len(right):
if left[left_pointer]<right[right_pointer]:
result.append(left[left_pointer])
left_pointer+=1
else:
result.append(right[right_pointer])
right_pointer +=1
result += left[left_pointer:]
result += right[right_pointer:]
return result
二分查找
非递归版本
def er_find(ley,alist):
min = 0
max = len(alist)-1
cen = (min+max)//2
if key in alist:
while True:
if alist[cen] > key:
cen-=1
elif alist[cen]<key:
cen+=1
elif alist[cen]==key:
return cen
else:
raise递归版本
def er_find(key,alist):
n = len(n)
if n >0:
mid = n//2
if alist[mid] == key:
return True
elif key < alist[mid]:
return er_find(alist[:mid],key)
else:
return er_find(alist[mid+1:])
return False
常见排序算法效率比较
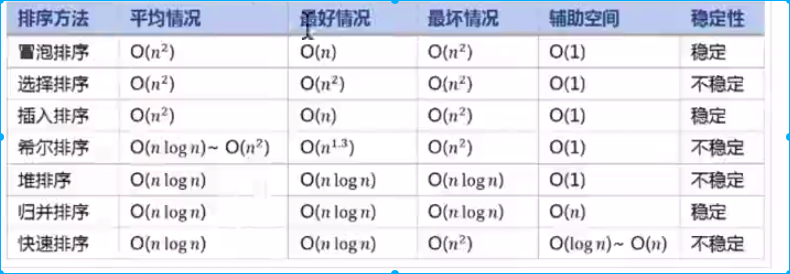
这个是自己看视频总结的。。如果有什么不对的地方,还请各位大佬不吝赐教。。。。