嗯,今天我们来谈一谈HashMap,也叫哈希表,最近看了看Java中HashMap的源码,粗略的有个了解,希望通过这片文章能给和我一样在面对源码一脸懵b的小伙伴一个方向。
哈希表(HashMap)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术核心就是在内存中维护着一张巨大的哈希表。而HashMap的实现原理也经常出现在各种面试题中,由此可见其重要性。
目录:
- 什么是哈希表
- HashMap实现原理
- 重写equals方法与重写hashCode方法
一、什么是哈希表
首先,我们先来简单回顾下基本数据结构在增删改查的基础性能。
数组:采用一段连续的储存单元来储存数据。对于指定下标的查找,时间复杂度为O(1),通过给定值进行查找,我们需要遍历数组,所以时间复杂度为O(n),对于一般的插入删除操作,因为数组元素要进行移动,所以时间复杂度也为O(n)。
线性链表:对于链表的新增,删除等操作,因为链表的特殊性,仅需处理节点引用,所以时间复杂度为O(1),而要进行查找操作需要遍历链表,复杂度为O(n)。
二叉树:对于一科相对平衡的有序二叉树,对其进行插入,查找,删除等操作平均复杂度为O(logn)。
哈希表:相比上述几种数据结构,在哈希表中进行添加,删除,查找等操作,性能非常高,在不考虑哈希冲突下,仅需一次定位就能完成,时间复杂度为O(1)。
众所周知,数据结构的物理储存结构只有两种:顺序储存结构和链式储存结构
顺序储存:在内存中按照顺序分配内存空间
链式储存:在内存中无序存放,但是一个Node中存储着下一个Node内存地址
而哈希表利用了这两种结构的特性,其主干为数组。
比如我们要新增或者查找某个元素的时候,我们通过函数映射将该关键字映射到数组的某个位置,通过该关键字即可实现一次定位,一次查找就可完成操作。
储存位置 = f(关键字)
其中函数“f”一般称为哈希函数,哈希函数设计的好坏直接影响哈希表性能的优劣。
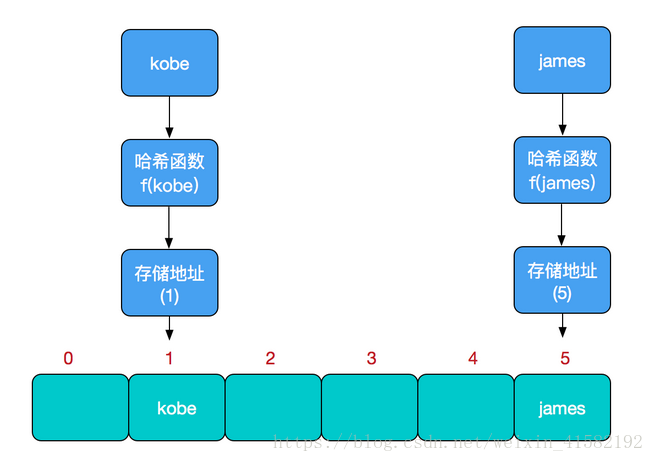
哈希冲突
当我们的关键字通过哈希函数计算后得到结果相同时,即发生了哈希冲突。我们不能保证哈希冲突一定不会发生,越是优秀的哈希函数,越能够计算简单并且散列地址均匀。而面对哈希冲突,有多种解决方案:开放定址法,再散列法,链地址法,而Java中的HashMap则使用的是链地址法。
二、实现原理
HashMap主干为一个Entry数组,而每个Entry存放着一个键值对和同时指向另一个Entry的引用,如果发生哈希冲突,该引用即指向另一个Entry。
下面我们用一段代码来显示内部结构。
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;//存储指向下一个Entry的引用,单链表结构
int hash;//对key的hashcode值进行hash运算后得到的值,存储在Entry,避免重复计算
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
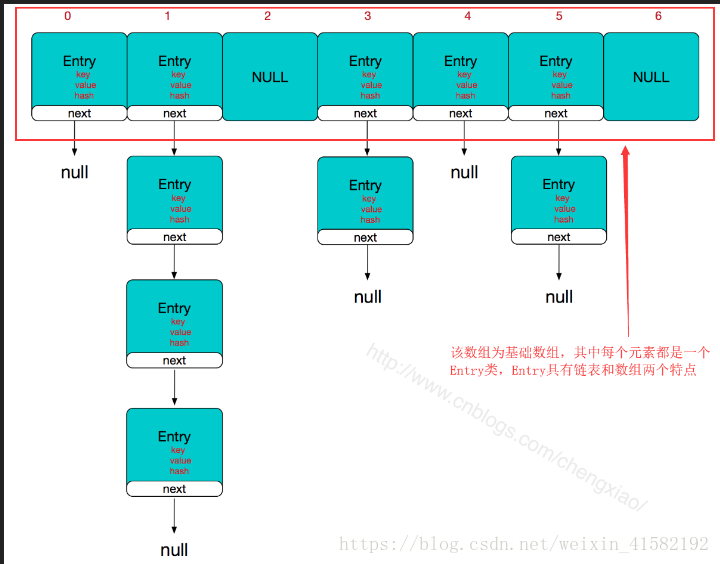
用图来表示整体结构如上图。(转自csdn,侵删)
有图可知,HashMap是由数组+链表结构组成,数组是HashMap主体,链表则是为了解决哈希冲突而存在,如果对于Entry不含链表的位置,对其操作的时间复杂度为O(1),如果定位到具有链表的位置,则时间复杂度为O(n)。
HashMap中重要字段
- transient int size 实际储存的KEY-VALUE对个数
- int threshold 阀值,当表为空的时候,该值初始容量为16,后期扩容使用
- final float loadFactor 负载因子,代表表的填充度,默认为0.75
- transient int modCount 用于快速失败,迭代时抛出异常
最终储存位置流程图

三、重写equals方法和hashCode方法
首先我们来说一下,原生的equals方法和hashCode方法代表什么。
原生的hashCode方法是通过对象地址经过哈希函数计算所得出的一个值。而equals方法是通过比较是否为同一个对象。
重写equals方法,尽量保证我们每个对象都能在table中均匀散列,能够有效提高HashMap的性能,而根据不同业务我们需要重写不同的hashCode。
举个例子,如果有一个新的对象A,一个旧的对象B,逻辑上我们希望他们是相同的,所以我们重写了euqals方法,此时就要求我们A .euqals(B)=true,如果不重写hashCode方法,则A.hashCode != B.hashCode,所以在散列的时候,会在Map中储存两个值一样的数据。
当向集合中插入对象时,如何判别在集合中是否已经存在该对象了?(注意:集合中不允许重复的元素存在)
大多数人都会想到调用equals方法来逐个进行比较,这个方法确实可行。但是如果集合中已经存在一万条数据或者更多的数据,如果采用equals方法去逐一比较,效率必然是一个问题。此时hashCode方法的作用就体现出来了,当集合要添加新的对象时,先调用这个对象的hashCode方法,得到对应的hashcode值,实际上在HashMap的具体实现中会用一个table保存已经存进去的对象的hashcode值,如果table中没有该hashcode值,它就可以直接存进去,不用再进行任何比较了;如果存在该hashcode值, 就调用它的equals方法与新元素进行比较,相同的话就不存了,不相同就散列其它的地址,所以这里存在一个冲突解决的问题,这样一来实际调用equals方法的次数就大大降低了,说通俗一点:Java中的hashCode方法就是根据一定的规则将与对象相关的信息(比如对象的存储地址,对象的字段等)映射成一个数值,这个数值称作为散列值。
可以直接根据hashcode值判断两个对象是否相等吗?肯定是不可以的,因为不同的对象可能会生成相同的hashcode值。虽然不能根据hashcode值判断两个对象是否相等,但是可以直接根据hashcode值判断两个对象不等,如果两个对象的hashcode值不等,则必定是两个不同的对象。如果要判断两个对象是否真正相等,必须通过equals方法。