商汤科技《AM-LFS AutoML for Loss Function Search》解读

回顾部分损失函数
一篇arXiv论文《AM-LFS: AutoML for Loss Function Search》,商汤科技揭示使用AutoML方法设计Loss函数,以一个新的视角对部分损失函数进行解释,同时用统一的表达公式对其进行了表达。基于统一的表达式构建搜索空间让已有的损失函数发挥更好的性能。
Softmax Loss
以上是标准Softmax的图解(它的特点就是优化类间的距离非常棒,但是优化类内距离时比较弱),以下是《AM-LFS AutoML for Loss Function Search》给出的Softmax表达式

是训练集的长度,
表示第
类(
取值范围从
,
是类别数)得分。
也是全连接层的激活函数,
可表示为下面表达(2)(内积),其为权重值和输入值的乘积,其中
是表示向量
和
之间的角度。
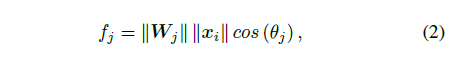
则最终传统的Softmax Loss可以表达为:
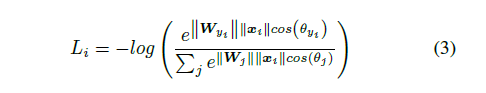
Margin-based Softmax Loss:
Margin-based Softmax Loss损失函数通过在原Softmax损失函数中,插入一个
函数,得到
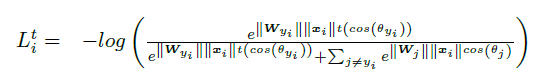
一般的
函数作者列句了常用的3种,
函数的引入其实就是为了更好的扩大类间距离的同时,让类内样本更加的紧凑(分类效果更好)
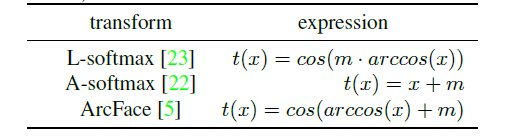
通用变体Loss
经过以上的Softmax损失函数的分析,作者抽象出了通用的变体函数。
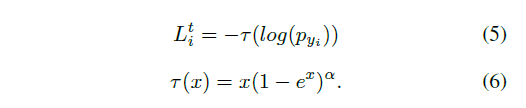
损失函数分析
类间距离函数
和输出结果概率值第
个
关系如下给出,其中定义
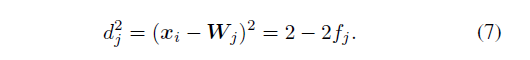
因此可以对损失函数在
和
的上的表现进行求导分析
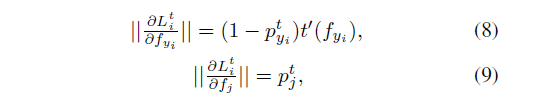
为了对类间距离和类内距离的相关评价,文章引入了
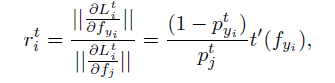
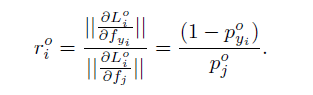
最终得到一个简单的表达式,因此可以得出一个非常重要的结论:“定义的损失函数表达式衍生函数
实际上是具有控制类内距离对于类间距离显著性的作用”
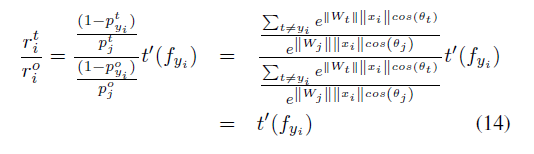
搜索空间
可以基于Softmax及其变种函数,作者提出下面通用表达公式
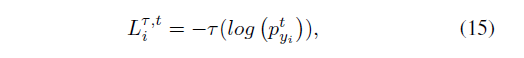
搜索空间通过
和
来进行定义,其又可以定义为
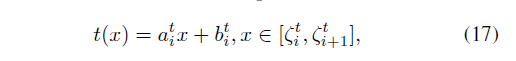
则可以定义参数集合
,
仅仅就由
定义,在整个训练阶段的超参数
是符合正态分布的。
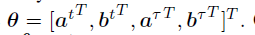
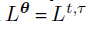
则我们的最终的搜索空间有:
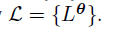
优化
AM-LFS中采用双层优化框架:
inner level:训练模型权值
让损失函数最低
outer level:寻找到一个好的损失函数超参数
,这个
能最大化奖励值

算法AM-LFS

在这里插入图片描述在模型进行训练之前,对超参数进行初始化,得到一个集合
。然后针对每一个epoch在训练过程中带入上面的超参数,经过
个epoch后,所有的
超参数都训练完成,并得到每个epoch下的
从中选择得分最高的
。最后进行
和
的更新。
【读这篇文章开荒了些知识,中间还有很多不是很明白的地方,希望以后再来进行补充,有什么需要更正的地方欢迎大家留言交流!】
【参考文献】
【1】【技术综述】一文道尽softmax loss及其变种
【2】论文地址:https://arxiv.org/pdf/1905.07375v1.pdf