流概述
重要的概念:
为什么建议使用字符流
字节流至字符流InputStreamReader设置编码格式 [txt gbk2321? utf-8? utf-16?]
较高效的Buffered流
BufferedReader的readLine()方法
BufferedWriter的newLine()方法流是一组有序的数据序列,根据操作的类型,可分为输入流和输出流两种
I/O流提供了一条通道程序,可以使用这条通道把源中的字节序列送到目的地
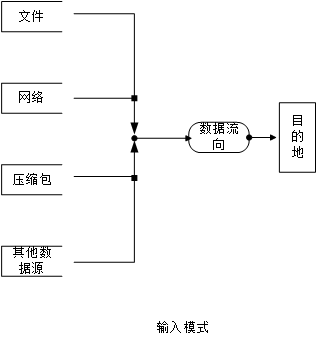
输入流 程序从源的输入流中读取源中的数据
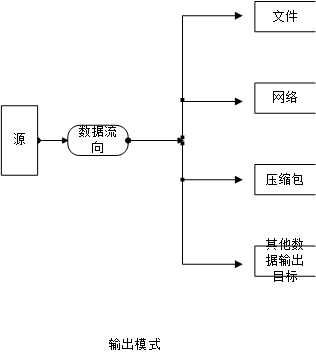
输出流 程序通过向输出流中写入数据把信息传递到目的地
Java流API
Java语言定义了许多类专门负责各种方式的输入/输出,这些类都放在java.io包中。其中,所有输入流都是抽象类InputStream(字节输入流)或者抽象类Reader(字符输入流)的子类;而所有的输出流都是抽象类OutputStream(字节输出流)或抽象类Writer(字符输出流)的子类。
Java中的字符是双字节的,InputStream是用来处理字节的,并不适合处理字符文本。Java为字符文本的输入专门提供了一套单独的类Reader,但Reader类并不是InputStream类的替换者,只是在处理字符串时简化了编程
查看类文档以及实现的子类说明和类方法
InputStream OutputStream Reader Writer1
下面介绍了这四个抽象类读写的方法,以它们为子类的对象都是围绕这些读写方法来进行读写的。
InputStream重要方法
abstract int |
**read**() 从输入流中读取数据的下一个字节。 |
|---|---|
int |
**read**(byte[] b) 从输入流中读取一定数量的字节,并将其存储在缓冲区数组 b 中。 |
int |
**read**(byte[] b, int off, int len) 将输入流中最多 len 个数据字节读入 byte 数组。 |
OutputStream重要方法
void |
**write**(byte[] b) 将 b.length 个字节从指定的 byte 数组写入此输出流。 |
|---|---|
void |
**write**(byte[] b, int off, int len) 将指定 byte 数组中从偏移量 off 开始的 len 个字节写入此输出流。 |
abstract void |
**write**(int b) 将指定的字节写入此输出流。 |
Reader与Writer和InputStream与OutputStream的读写方法还是比较类似的,差异主要体现在方法参数从字节编程字符,字节数组编程字符串,添加了一些字符缓冲区读取
Reader重要方法
int |
read() 读取单个字符。 |
|---|---|
int |
read(char[] cbuf) 将字符读入数组。 |
abstract int |
read(char[] cbuf, int off, int len) 将字符读入数组的某一部分。 |
int |
read(CharBuffer target) 试图将字符读入指定的字符缓冲区。 |
Writer重要方法
void |
**write**(char[] cbuf) 写入字符数组。 |
|---|---|
abstract void |
**write**(char[] cbuf, int off, int len) 写入字符数组的某一部分。 |
void |
**write**(int c) 写入单个字符。 |
void |
**write**(String str) 写入字符串。 |
void |
**write**(String str, int off, int len) |
FileInputStream与FileOutputStream
继承关系
|- java.io.InputStream
|- java.io.FileInputStream
常用构造方法
FileInputStream(String name)
FileInputStream(File file)
代码运用
/**
* 使用FileOutputStream类向文件Test.txt写入信息,通过FileInputStream
* 类将文件中的数据读取到控制台上
* @param filePath 文件路径
*/
public static void fileStreamOperate(String filePath){
File file = new File(filePath);
//判断
if (!file.exists()){
System.out.println("该路径下的文件不存在,在类路径下创建该文件");
try {
file.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
}
try {
//创建FileOutputStream对象
FileOutputStream out = new FileOutputStream(file);
//创建byte[]型数组
byte[] bytes_out = "打工是不可能打工的,这辈子都不可能打工的".getBytes();
out.write(bytes_out);
out.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e1){
e1.printStackTrace();
}
try{
//创建FileInputStream对象
FileInputStream in = new FileInputStream(file);
//创建byte数组
byte[] bytes_in = new byte[1024];
//创建byte数组
//必须一次把文件中信息读取出来
//或者把所有读取得字节有序存储,否则因为编码问题会出现乱码问题
//从文件中读取信息
int len = in.read(bytes_in);
//取消while ((len = in.read(bytes_in)) != -1){
//将文件中的信息输出
System.out.println("文件中的信息是:" + new String(bytes_in, 0, len));
in.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}- 字节和字符的相互转换
FileReader和FileWriter类
继承关系
|- Reader
|- InputStreamReader
|- FileReader
常用构造关系
FileReader(File file)
在给定从中读取数据的 File 的情况下创建一个新 FileReader。
FileReader(String fileName)
在给定从中读取数据的文件名的情况下创建一个新 FileReader。
为什么建议使用字符流 ?
使用FileInputStream类向文件中写入数据与使用FileOutputStream类从文件中将内容读出来,都存在不足,即这两个类都只提供了对字节或字节数组的读取方法。由于汉字在文件中占用两个字节,如果使用字节流,读取不好可能会出现乱码,此时采用字符流Reader和Writer类即可以避免这种情况
什么是InputStreamReader[继承关系中]?
InputStreamReader 是字节流通向字符流的桥梁:它使用指定的 charset 读取字节并将其解码为字符。它使用的字符集可以由名称指定或显式给定,或者可以接受平台默认的字符集。每次调用 InputStreamReader 中的一个 read() 方法都会导致从底层输入流读取一个或多个字节。要启用从字节到字符的有效转换,可以提前从底层流读取更多的字节,使其超过满足当前读取操作所需的字节。 为了达到最高效率,可要考虑在 BufferedReader 内包装 InputStreamReader。例如:
BufferedReader in
= new BufferedReader(new InputStreamReader(System.in));例如txt编码方式是有ANSI,UTF-8,UTF-16,此时需要此类来设定charset。2
代码运用
只需要把上面FileInputStream与FileOutputStream中代码运用中读写代码相应改成Reader与Writer读取字符的代码
待缓存的输入/输出流
BufferedInputStream与BufferedOutputStream
继承关系
|- java.io.InputStream
|- java.io.FilterInputStream
|- jva.io.BufferedInputStream
常用构造关系
**BufferedInputStream**(InputStream in) 创建一个 BufferedInputStream 并保存其参数,即输入流 in,以便将来使用。 |
|---|
**BufferedInputStream**(InputStream in, int size) 创建具有指定缓冲区大小的 BufferedInputStream 并保存其参数,即输入流 in,以便将来使用。 |
BufferedReader与BufferedWriter
从字符输入流中读取文本,缓冲各个字符,从而实现字符、数组和行的高效读取。
通常,Reader 所作的每个读取请求都会导致对底层字符或字节流进行相应的读取请求。因此,建议用 BufferedReader 包装所有其 read() 操作可能开销很高的 Reader(如 FileReader 和 InputStreamReader)。例如,
BufferedReader in
= new BufferedReader(new FileReader("foo.in"));继承关系
|- java.io.Reader
|- java.io.BufferedReader
常用构造关系
**BufferedReader**(Reader in) 创建一个使用默认大小输入缓冲区的缓冲字符输入流。 |
|---|
**BufferedReader**(Reader in, int sz) 创建一个使用指定大小输入缓冲区的缓冲字符输入流。 |
重要方法
BufferedReader
String |
**readLine**() 读取一个文本行。 |
|---|---|
| void | **flush**() 刷新该流的缓存 |
BufferedWriter
void |
**newLine**() 写入一个行分隔符。 |
|---|---|
代码运用
题目
超文本标记语言(即HTML),是用于描述网页文档的一种标记语言。
HTML通过文本来描述文档显示出来应该具有的“样子”。它主要通过标签来定义对象的显示属性或行为。
如果把java的源文件直接拷贝到HTML文档中,用浏览器直接打开,会发现本来整齐有序的源文件变成了一团遭。这是因为,文本中的许多回车和空格都被忽略了。而有些符号在html中有特殊的含义,引起了更复杂的局面。
为了源文件能正常显示,我们必须为文本加上适当的标签。对特殊的符号进行转义处理。
常用的有:
HTML 需要转义的实体:
& ---> &
空格 --->
< ---> <
> ---> >
" ---> "
此外,根据源码的特点,可以把 TAB 转为4个空格来显示。
TAB --->
为了显示为换行,需要在行尾加<br/>标签。
为了显示美观,对关键字加粗显示,即在关键字左右加<b>标签。比如:
<b>public</b>
对单行注释文本用绿色显示,可以使用<font>标签,形如:
<font color=green>//这是我的单行注释!</font>
注意:如果“//”出现在字符串中,则注意区分,不要错误地变为绿色。
不考虑多行注释的问题(/* .... */ 或 /** .... */)
你的任务是:编写程序,把给定的源文件转化为相应的html表达。【输入、输出格式要求】
与你的程序同一目录下,存有源文件 a.txt,其中存有标准的java源文件。要求编写程序把它转化为b.html。
例如:目前的 a.txt 文件与 b.html 文件就是对应的。可以用记事本打开b.html查看转换后的内容。用浏览器打开b.html则可以看到显示的效果。
注意:实际评测的时候使用的a.txt与示例是不同的。 import java.io.*;
public class JavaSourceToHtml {
//读取每一行
//把每一行的东西进行转换
//把转换后的这一行读写到另外一个文件对应行
public static void transfromFileMessage(){
try {
//假定b.html一定不存在
File bhtml = new File("C:\\Users\\13612\\Desktop\\17 第三届决赛\\Java本科\\3\\b.html");
bhtml.createNewFile();
FileOutputStream fw = new FileOutputStream(bhtml);
OutputStreamWriter outstmwrr = new OutputStreamWriter(fw,"gb2312");
BufferedWriter bw = new BufferedWriter(outstmwrr);
//显式注明txt文本使用ANSI编码格式
InputStreamReader intStmRer = new InputStreamReader(new FileInputStream("C:\\Users\\13612\\Desktop\\17 第三届决赛\\Java本科\\3\\a.txt"),"gb2312");
BufferedReader bf = new BufferedReader(intStmRer);
String line = "";
bw.write("<html><body>\n");
bw.newLine();
while ((line = bf.readLine()) != null){
bw.write(transformLine(line));
bw.newLine();
}
bw.write("</body></html>");
bw.close();
bf.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
private static String transformLine(String oriLine){
char oriChar;
StringBuilder strBuier = new StringBuilder();
for (int i = 0; i < oriLine.length(); i++) {
oriChar = oriLine.charAt(i);
switch (oriChar){
case '&' : strBuier.append("&");
break;
case ' ' : strBuier.append(" ");
break;
case '<' : strBuier.append("<");
break;
case '>' : strBuier.append(">");
break;
case '"' : strBuier.append(""");
break;
case '\t' : strBuier.append("  ");
break;
default : strBuier.append(oriChar);
}
}
String strTrorm = strBuier.toString();
System.out.println(strTrorm);
strTrorm = strTrorm.replaceAll("public","<b>public</b>");
strTrorm = strTrorm.replaceAll("static","<b>static</b>");
strTrorm = strTrorm.replaceAll("void","<b>void</b>");
strTrorm = strTrorm.replaceAll("class","<b>class</b>");
strTrorm = strTrorm.replaceAll("final","<b>final</b>");
int mach = strTrorm.lastIndexOf("//");
//假如在字符串,存在问题,未更改【即字符串存在//,但是这行并没有注释】
if (mach != -1){
String comments = strTrorm.substring(mach);
System.out.println(comments);
//在字符串中有相同字符串,存在问题
strTrorm = strTrorm.replaceAll(comments, "<font color=green>" + comments + "</font>");
}
strTrorm = strTrorm + "<br/>";
return strTrorm;
}
public static void main(String[] args) {
transfromFileMessage();
}
}http://tool.oschina.net/apidocs/apidoc?api=jdk-zh↩