前言
本篇不是Deepdive入门教程,而是对其一些源码细节进行了解读,换句话说要深入到内部去看看其具体是怎么做的,所以看本篇的前提是假设读者已经大概清楚了deepdive的使用流程,如果不是很熟悉,或是第一次使用建议先去看一下入门教程。
本篇先是分析特征方面的源码,接着是实践部分,即使用ltp替换默认的斯坦福NLP信息抽取部分进而可优化该部分到数秒内,最后简单说一下其模型方面的问题以及其它补充
其实关于入门教程总结来说就是使用了postgresql数据库来做存储部分,NLP部分使用的是standford nlp。然后过程基本都遵循以下套路:
---------------------------------------------------------------------------------------------------------------------------------------
一 先在app.ddlog中定义我们想要输出的结构化内容

二 再在app.ddlog中使用function定义相关的处理函数,其中over后面就是函数的形参,implementation 是指的真真的处理函数
可 以 是python 脚本,.sh等,但必须写成是一个迭代器,这个脚本就可以根据需求自行写啦

三 最后再在app.ddlog中调用上述函数,传入参数

上面三步都是在app.ddlog中定义的,其实也很清楚就是定义了一个函数,包括了输入输出以及怎么处理等等
四:上面只是定义好了,最后我们就是在命令窗口中运行上面过程了,很简单:就是编译和得到sentences
---------------------------------------------------------------------------------------------------------------------------------------
基本就是这么个套路,因为该部分不是本文重点,所以就不展开说了,更多的可以看:
Deepdive官网:http://deepdive.stanford.edu/
Deepdive 源码:https://github.com/HazyResearch/deepdive
中文博客:这是一个大佬写的,特别详细
https://blog.csdn.net/cx943024256/article/details/79056726
https://github.com/theDoctor2013/DeepDive-tutorial/blob/master/Deepdive_new.md
关于ltp 编译好的安装包:
链接:https://pan.baidu.com/s/12uqQmz3x0QeaLKeZFQwT2Q
提取码:bw6i
特征
在熟悉了DeepDive 流程后,不知道有没有注意到就是在特征提取部分即extract_transaction_features.py脚本,其中最重要的是调用了ddlib库的get_generic_features_relation产生了特征,特征的样子大概是这样:

我们这里选取的这句话是文章id号 1201734457的第三句话,这一对命名实体集合index分别是【46,51】和【22,27】
最后一共为这对命名实体结合提取了79个特征

为了下面便于分析结果,我们这里把这句话找了出来:

同时通过transaction_candidate表我们找到其对应的两个命名实体集合名即上面黄色的部分

可是上述得到的79个特征具体含义到底是什么呢?换句话说这些特征是怎么产生的呢?,这是本文想要解读的,所以本部分就其展开说明。
先看一下其整体的输入输出:
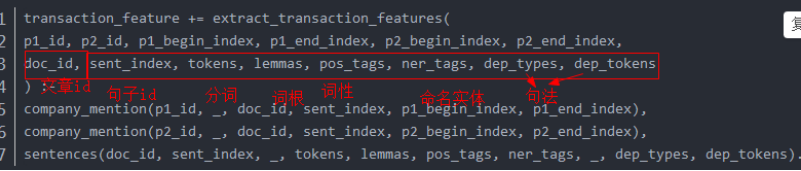
该部分代码主要就是调用了ddlib包,其有一些列属性和方法
其中属性定义在dd.py中
https://github.com/HazyResearch/deepdive/blob/master/ddlib/ddlib/dd.py

其中下面最常用的就是Word,Span,DepEdge
除此之外还会看到一个字典dictionaries,其里面可以看成就是保存了关键字
方法的话也有很多,其中就用本部分最重要的get_generic_features_relation
https://github.com/HazyResearch/deepdive/blob/master/ddlib/ddlib/gen_feats.py

可以看到有很多,别着急,大部分方法都是作为一个子模块被get_generic_features_relation调用的,现在我们就从get_generic_features_relation入手各个击破吧,当然load_dictionary就是一个从文件中加载预知关键字的函数没什么可说的。
下面正式开始吧:每一部分的关键代码会以红框圈出
----------------------------------------------------------------------------------------------------------------------------------------------------------

经过一些前面的步骤,我们大概要提取这么一对(图中两个橙色部分)的特征,然后get_generic_features_relation首先将一句话分为上述结构:span1和span2就是上述的一对命名实体集合(具体到本例子中就是一对公司),为了方面我们下文统一称这一对为mentions
其中betw_span对应的文本就是红色部分

Convering_sapn对应的就是黄色+红色的部分
span1和span2分别对应的是“甘薯大有农业科技有限公司”和“甘肃天润薯业有限责任公司”

然后其依次进行了如下九方面的特征提取
一 是否是反转的
当前两个命名实体集合是否是前后顺序,如果不是,会返回一个特征IS_INVERTED字段

由于当前例子中第一个命名实体集合是从46开始的,而后面一个命名实体集合是从22开始的,所以应该返回一个倒序的标志
对应的结果就是,否则就什么也不用返回了,所以当两个命名实体集合正好是前后顺序的时候,结果是没有返回的对应特征显示的

这也很好理解,文本特征一个重要方面就是上下文,所以这种前后关系至关重要!
二 _get_seq_features
分别将betw_span这个窗口内的词内容,词根,命名实体,词性输出并分别加上其对应的SEQ前缀

这里很简单,我们来对应的看一下其提取的特征结果:(就是文本红色的部分)

三 _get_window_features
这个是以converving_span为大小,分别取了begin左边的大小为3的窗口的词根和命名实体,以及end右面的大小为3的窗口的词根和命名实体即下面黑色区域


然后分别在词根和命名实体上对其左右进行many VS many组合即多对多组合

好了看一下对应的输出吧


这里所说的左面右面就是上述画图中的左右黑框,只不过这里"有限责任公司"是后一个图中后一个黄色框,“甘薯大有农业”是前一个黄色框,这里需要注意一下,同理下面的输出都应该注意该问题
这里应该是2(词根+命名实体)*3*3(多对多组合)个特征
加上第一方面的特征,目前为止已经是4+2*3*3=22个特征啦
四 _get_ngram_features
提取Betw_span内的N-grams
关于N-grams (https://www.cnblogs.com/jielongAI/p/10189907.html)
简单来说这里就是以窗口小于等于3为一个整体 的单词组合提取出来,比如
【我,是,中国,大家庭,中,的一员】
那么输出就是
我是
我是中国
是中国
是中国大家庭
,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,

对应的输出(文本中的红色部分)


五 _get_dictionary_indicator_features
提取一对公司中的关键字(dictionaries中存在的词根)
但是目前有两个疑问:
在本文例子中dictionaries中是空,没看到有什么?难道该部分没有提取吗
另外一个问题就是待从匹配的部分是从哪里开始的,看代码是从sentences一开始匹配,难道不应该是匹配两个命名实体集合吗?

由于没有加载关键字,所以没有对应的输出
六 _get_min_dep_path_features
提取一对公司的最小路径的一些特征,首先将这一对mentions(两个命名实体集合)中的实体两两组合求出当前两个实体的最短路径,然后迭代比较直到找到全局最小路径,最后就是输出一些该路径方面的信息

_get_min_dep_path方法就是对应的迭代过程

其中最关键的就是dd.dep_path_between_words,即找当前一对实体的最短路径,我们来看看其是怎么做的:
首先使用_path_to_root找到当前命名实体到最根节点上这一路上的词语集合,这里的根节点(dep_par)指的是我们通过句法结构挖缺得到的结果,一般句法结构结果包含两部分即句法和父节点,这里的dep_par就是结果中的父节点。

注意:从这里可以看到ddlib里面是将-1看为根节点的,而我们使用一些NLP信息抽取包在做句法抽取的时候对应的根节点一般是以0为根节点,所以为了使用这里ddlib包就得给我们抽取的出来的父节点减1,这也就是extract_transaction_features.py这里减一的原因:

然后就是求两者到根节点这一路上不相同的路径,然后记录下这些不相同的路径的一些详细信息,注意前后边结构中word1和word2设的不一样,而且最后进行了反转

其实感觉这里有点像LCA的影子,为了更清晰的理解上面额逻辑,我们这里还是画一下图简单说一下:

黄色就是代码中的common
然后反转后相当于变为3-》4,所以最后path的效果大概就是1-2-3-4
这样就得到了一对命名实体的路径,然后遍历一对公司下所有命名实体的组合,找到最短的那条路径对应的一路上边的信息即main_path.

之后就好说了,就是返回这条边的一些信息,主要从三方面来返回的
返回 label(句法结构,比如主谓什么的)和词根
只返回 label
也返回 label和词根,只不过是对应的词根要是在字典中出现的(即是关键字),那么就给其加一个表示符"DICT_"

输出结果:

由于这里没有预加载的关键字所以这里没有DICT_标示,即第三行和第一行的both一样!
七 _get_substring_indices
这里其实和五做了相同的事情,都是得到一些和最短路径有关的特征,五求的是一对mentions之间的最短路径,而这里求得是两个命名实体之外的关键字部分分别和这一对mentions的最短路径,其中_get_substring_indices是遍历整个sentence,以小于等于3的滑动窗口得到一些列小短语,然后通过过滤掉落在两个命名实体之间的部分,那么最后剩下的就是两个命名实体之外的部分了,同时判断其中这段小短语中是否包含关键字,只有包含了关键字才会进行:

其实说的再直白一点就是:五是求一对mentions之间的最短路径特征,六是求关键字和mentions之间的最短路径特征
所以最后特征中带有前缀KW_IND应该就是一对mentions之外的那些滑动窗口系列中含有的关键字。
最后得到的 kw_span就是一个个窗口,之后呢就没什么了,就是用kw_span去分别和那一对mentions即span1,span2做和五一样的事情了对应的是三种返回(也具体可以回看五)

由于没有预加载关键字,所以没有对应的输出。
八 提取大写字母
这个很简单啦,就是判断这一对mentions的开头词是否大写

对应的输出是:

九 这对mentions的长度
这里所谓的长度值的是以5为单位来算,看看其有多少个长度为5的单位,当然了5是get_generic_features_relation可调的一个参数


对应的输出是:

----------------------------------------------------------------------------------------------------------------------------------------------------------
到这里特征的部分基本就讲解完成了,更多的内容可以看(当然其中的大部分方法都以讲解了)
https://github.com/HazyResearch/deepdive/blob/master/ddlib/ddlib/gen_feats.py
https://addons.mozilla.org/zh-CN/firefox/addon/pdf-saver-for-csdn-blog/
实践
原demo中信息抽取部分是使用斯坦福包进行的,该过程很慢,需要几个小时,维持这里考虑替换使用ltp包,两种解决思路:
一种是先在外部使用ltp处理好数据即提取好信息,后续就是导入到数据库中
上述方法实际上将文本抽取信息这部分脱离了deepdive框架,这样就没有了完整性,所以我们也可以将ltp信息抽取整合到deepdive框架下进行
下面介绍的是第一种,由于目前在linux中安装ltp,只有在python3环境下安装成功了,而deepdive中是基于python2的,所以如果采用第二种方法整合在一起的话,会出现一些问题,即在deepdive框架下使用python3脚本需要修改部分deepdive源码,考虑到篇幅,这部分由另一篇博客介绍:
https://blog.csdn.net/weixin_42001089/article/details/91388707
开始第一种方法的解决
该部分代码:https://github.com/Mryangkaitong/python-Machine-learning/tree/master/deepdive/demo_version_1
如果之前实验过别的数据,这里一定要初始化数据库,即清空数据库,重新开始
deepdive initdb更多deepdive 可以使用help查看
deepdive help一使用pyltp提取信息:
由于系统问题,articles.csv文件在linux和win 上面会出现一些符号上面的错误,这个需要注意,下面用到的articlesc.csv就出现了一部分符号错误,但不影响大局,实际使用的时候要注意

可以看到加载数据和ltp模型大概用了25秒
之后就是提取这50篇 文章的信息啦

仅仅用到大概15秒,注意这里将一句话中提取的字段拼接成了一个字符串以&&&&隔开,另外具体到某一个字段比如句法父节点也是个列表,那么这里是以@@分隔,所以在解析的时候,相当于&&&&是一级分隔,分隔出各个字段的信息,@@是二级分隔,分隔出每个字段下面的具体信息。同时这里去掉了两个字段,如下:

第一个是词根,对于这个例子来说,中文的词根和tokens时一样的,所以后续只要将tokens复制给lemmas即可,另外从上面特征的分析部分也可以看到,根本是不需要doc_offsets(单词偏移量)这个字段的,所以这里也没有提取该字段
注意:一最后的csv名字是sentences_nlp(这里要和后面统一)
二csv不要保存列名,即header=0
二 新建sentences_nlp数据表,并导入
在app.ddlog中添加:

注意,表的列名即sentences_list可以顺便起
但表名必须和csv保持一致
导入很简单啦:
deepdive compile && deepdive do sentences_nlp
看一下是否导入成功:
deepdive query '?- sentences_nlp(sentences_list).'
三 转化成sentences多个字段的信息
这部分就是将sentences_nlp表的数据结构转化成如下数据结构,注意这里去掉了doc_offects字段

需要修改的部分,首先是app.ddlog

可以看到这里我们使用nlp_markup.py来处理,其实该python很简单啦,就是split以一级分隔符&&&&和二级分隔符@@进行分隔即可,具体的可以看相关脚本文件。
好啦,开始运行:
deepdive compile && deepdive do sentences看一下运行结果:
deepdive query '
doc_id, index, tokens, ner_tags | 5
?- sentences(doc_id, index, text, tokens, lemmas, pos_tags, ner_tags, _, _).'注意因为我们上面少了一个字段,所以对比deepdive官网给的demo,这里应该少一个字段哈:

注意:至此,上面的部分其实可以归结为使用nlp包进行最原始的信息抽取,可以使用不同的nlp包,进行不同的
而后面的步骤流程基本都一样啦,只不过有的地方需要小改,比如原先使用斯坦福nlp包的时候,公式对应的是ORG,而使用ltp包的时候,其对应的是-Ni,所以后面不再细说,可直接参看deepdive官网本demo的说明,下面只说哪里需要改动
为了清楚区分两部分,这里暂且画一条分割线吧
------------------------------------------------------------------------------------------------------------------------------------------------------------------
四 抽取候选关系
需要改的地方首先是app.ddlog中给map.comanpy_mention.py传参的时候,用到的是sentences表,但是注意,因为我们在上面给表sentences取掉了一个字段,所以下面第二个红框记得删除一个字段

再者需要修改的就是map.comanpy_mention.py函数,原先公司对应的命名实体是ORG,使用ltp包后应该是Ni,当然啦,其还进一步对Ni进行了细化,这里不管,只要包含Ni即可

好啦,修改完毕,运行:
deepdive compile && deepdive do company_mention
看一下结果:
deepdive query 'mention_id,mention_text,doc_id,sentence_index,begin_index,end_index | 5 ?- company_mention(mention_id,mention_text,doc_id,sentence_index,begin_index,end_index).'
五 抽取候选关系
这里不需要什么修改,直接运行即可
deepdive compile && deepdive do transaction_candidate查看一下结果
deepdive sql "select * from transaction_candidate"
六 特征提取
这里仅仅需要修改extract_transaction_features.py输入参数时用到sentences表,还是将其参数减少一个
即app.ddlog:

修改完毕运行:
deepdive compile && deepdive do transaction_feature看一下运行结果
deepdive sql "select * from transaction_feature"
七 样本打标
先导入先验label 数据,即已知的交易数据,很简单,直接导入就可以啦:
deepdive compile && deepdive do transaction_dbdata首先需要修改supervise_transaction.py函数输入参数时用到sentences表,还是将其参数减少一个
即app.ddlog:

其次修改supervise_transaction.py脚本:

修改完毕,运行
deepdive compile && deepdive do transaction_label_resolved
看一下结果:
deepdive sql "select * from transaction_label_resolved"
八 模型构建
没什么变化,直接运行即可
deepdive compile && deepdive do has_transaction看一下结果:

九 因子图构建
没什么变化直接运行即可
deepdive compile && deepdive do probabilities查看一下结果:
deepdive sql "SELECT p1_id, p2_id, expectation FROM has_transaction_label_inference ORDER BY random() LIMIT 20"


-----------------------------------------------------------------------------------------------------------------------------------------------------------------------
最后这里再提一句,由于ltp提取的命名实体中,使用Ni 表示机构名,且其进一步进行了细化即使用B 表示实体开始词,I表示实体中间词,E表示实体结束词,S表示单独成实体,所以如果想完全和斯坦福对应,这里可以考虑将所有细化都改为Ni
模型
关于模型方面是采用的因子图,可以分为两大块来看那就是:权重学习和推理
推理部分就是利用权重进行一个边缘概率的计算,很简单,最后计算得到一种关系的概率。
https://blog.csdn.net/unreliable/article/details/79982361
儿难点在于权重学习部分,这里又有两大部分,一种是人为指定的某些依赖关系的权重,就是demo中比如p1和p2有交易,那么就认为p2和p1有交易,这里的权值是3,不用学习,还有一部分weight是特征,需要靠特征学习,得到这些特征的权值,可以使用如下命令查看训练后特征的权值
首先要运行
deepdive do data/model/weights该命令会创建一个权重的综合的视图,叫做: dd_inference_result_weights_mapping. 有了这个视图,就可以很容易得到每个推理规则和它们的参数值,如:
deepdive sql "SELECT description,weight FROM dd_inference_result_weights_mapping order by weight desc"
正如上面所看到的,有了权值,通过计算一个边缘概率(所谓的推理部分)便可得到我们想要的最终关系的预测概率,所以重点在于权重要合理,就这要求我们指定一些依赖关系为常数的时候,要充分考虑当前预测领域的一些专业背景,这里可以定义各种依赖关系的常数权重。
最后总结一下,最终的预测概率是一个边缘概率,其计算用到两方面一个是和依赖节点的这个关系的权值,一个是依赖节点的概率,其中后者中部分节点的概率是已知的即label(当然label 的得来其实也可以看做是另外一个权值的过程,因为从打标的过程可以看出,其也是定义了多种规则,对于一个样本最后得到一系列权值,随后将其相加即综合考虑后才决定了最终的label是1还是0,) ,其余是待预测的
注意:要区分开打标过程中定义的那些规则和模型这里的定义的依赖关系的定义,前者是针对一个节点的label说的,其最终要实现的目的是经过定义的多种规则后确定label 的正负,而后者是因子图里面的因子,即依赖关系+权值,重点是要说明哪些依赖关系的权值是多少,这两部分要分开看。
补充
下面几个应该是常用的几个数据库层面的deepdive命令
#查看当前数据库中的表
deepdive relation list
#查看某个表的字段
deepdive relation columns articles
#导出数据库
deepdive unload bar bar-1.tsv /data/bar-2.csv.bz2下面三个文件,是DeepDive中编译的三个相关文件:
app.ddlogdeepdive.confschema.json
即当任何一个文件改变时,要先编译,编译后产生的文件是位于run/文件夹下的,即run/文件夹是编译产生的
run下的比较常用的可以看一下dataflow.svg,其就是这个数据流图,可以用浏览器直接打开。