前言:
deepdive是基于python2的,如果写脚本时使用python3,就会出现一系列问题,例如最开始可能遇到的报错就是:即找不到dd文件等等
22:38:04 [Helpers$(akka://deepdive)] INFO Traceback (most recent call last):
22:38:04 [Helpers$(akka://deepdive)] INFO File "/opt/elementary-memex-ddlog/escort-review/udf/extract_test.py", line 12, in <module>
22:38:04 [Helpers$(akka://deepdive)] INFO import ddlib
22:38:04 [Helpers$(akka://deepdive)] INFO File "/home/eve/local/lib/python/ddlib/__init__.py", line 1, in <module>
22:38:04 [Helpers$(akka://deepdive)] INFO from dd import *
22:38:04 [Helpers$(akka://deepdive)] INFO ImportError: No module named 'dd'本篇目的就是修改相关源码,使我们可以使用python3
最后会具体给出一个实践,建议从第一篇博客看起:
https://blog.csdn.net/weixin_42001089/article/details/90749577
关于deepdive更多使用细节:中文翻译版
https://github.com/theDoctor2013/DeepDive-tutorial/blob/master/Deepdive_new.md
本篇实践部分代码:
https://github.com/Mryangkaitong/python-Machine-learning/tree/master/deepdive/demo_version_2
调试:
:在进行修改源码时,首先要知道哪里错了,即调试,可以使用如下两种方法:
一 deepdive 自带的调试API:
deepdive env python udf/my.py
对应到py3便是:
deepdive env python3 udf/my.py二:print大法
除了上述方法外,我们知道在python 中经常可以使用print大法来看某些输出进而可以定位错误,但是DeepDive的UDF的所有标准输出都被转换为TSJ或者TSV格式并存到数据库里,所以像Python中的print这样的语句是不可以作为屏幕信息输出的,这样会破坏我们的数据。所以正确的用法是把屏幕信息使用标准错误流standard error中进行输出(其他语言一样):
#!/usr/bin/env python
from deepdive import *
import sys
@tsj_extractor
@returns( ... )
def extract( ... ):
...
print >>sys.stderr, 'This prints some_object to logs :', some_object
...当然了,上述对应的是python2的写法,在python3中是:
#!/usr/bin/env python
from deepdive import *
import sys
@tsj_extractor
@returns( ... )
def extract( ... ):
...
print('This prints some_object to logs :', some_object, file=sys.stderr)
...修改:
涉及到的源码主要是在$HOME/local/lib/python/ddlib下的四个文件
__init__.py
dd.py
gen_feats.py
util.py
一个一个来看
__init__.py
需要将路径修改为当前路径,负责会找不到相关py文件:
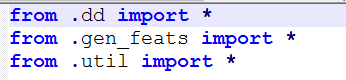
gen_feats.py
首先也是要改一下为当前路径
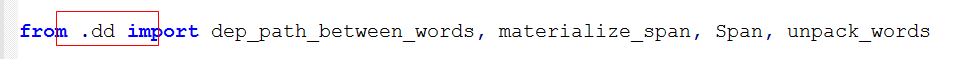
还有就是修改一下运行环境

util.py
这里需要改成对应的list,不然python3中zip 是没有len()的,后续代码中会用到len()

还有就是这里改为字符串标示

其次就是一些print需要加括号,对应的改一下就好啦
上面就是主要的修改成分,其他的一些都修改都很简单这里就不说啦,笔者这里已经修改好,直接复制这4个文件覆盖掉源码中的四个文件即可.
这样我们就可以使用python3脚本了,即udf下的脚本都可以换成python3,如果还是想在python3下用原demo中的部分脚本,一个是要将脚本开头指定为python3环境,另一个是要注意原demo中有几个脚本需要改下
比如原demo中给的trasform.py中要将print加括号等等。

map_company_mention.py中
xrange替换为range,因为python3中是没有xrange的,且在python3中unicode这种写法是不对的,直接改为str即可

实践:
由于使用使用deepdive 原始的斯坦福的nlp包进行文本信息提取时间过长,故换用ltp处理,本例子还是实现交易记录的预测,只不过nlp处理部分替换了
即主要写了一个nlp_markup.py替换原来的nlp_markup.sh,注意这里为了演示统一将udf下的所有python脚本指定为了python3环境
首先为了使用ltp要将app.ddlog中要调用nlp_markup.sh换为调用nlp_markup.py脚本

运行流程的命令没有变:
即先是导入文章
deepdive compile && deepdive do articles提取文本信息,基本需要几秒就可以结束该过程,而之前需要数小时
deepdive compile && deepdive do sentences
看一下结果

生成候选实体
deepdive compile && deepdive do company_mention
生成候选实体对
deepdive compile && deepdive do transaction_candidate提取特征
deepdive compile && deepdive do transaction_feature打标
deepdive do transaction_label_resolved变量表定义:
deepdive compile && deepdive do has_transaction预测:
deepdive compile && deepdive do probabilities看一下结果:
deepdive sql "SELECT p1_id, p2_id, expectation FROM has_transaction_label_inference
ORDER BY expectation desc"