本次作业的要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339
Hadoop综合大作业 要求:
1.将爬虫大作业产生的csv文件上传到HDFS
此处选取的是爬虫大作业——豆瓣上排名前250的电影评价
此处选取的是douban.csv文件,共计32829条数据。
首先,在本地中创建一个/usr/local/bigdatacase/dataset 文件夹。 然后把douban250.csv文件复制到这个文件夹中,然后
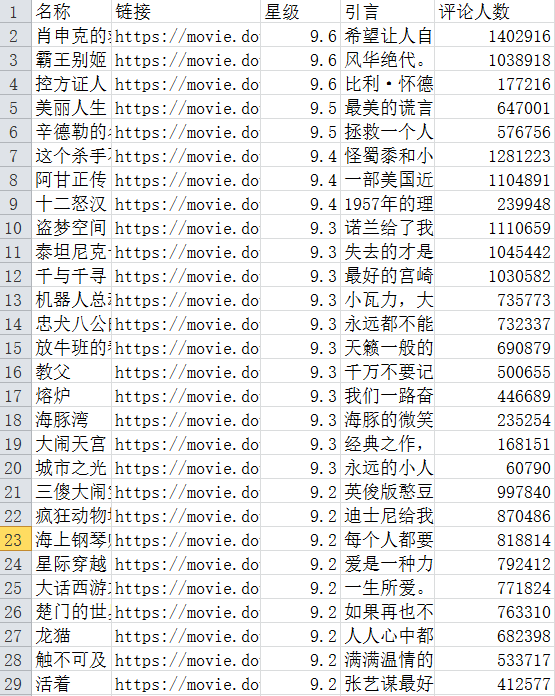
删除第一行记录以及 显示前五行记录 如下图所示:
对CSV文件进行预处理生成无标题文本文件
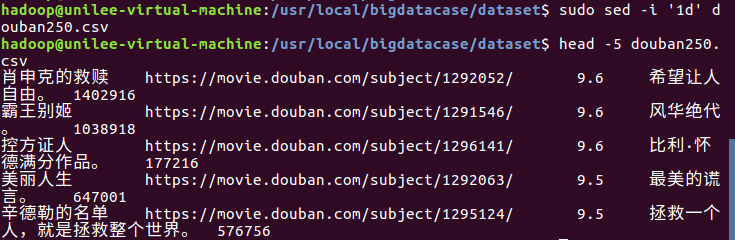
编辑pre_deal.sh文件对csv文件进行数据预处理,使得pre_deal.sh中的内容生效。如下图所示:

查看user_table.txt里面的内容,如下图所示:

将user_table.txt 存放在/usr/local/文件夹下赋予bigdatacase权限 如下图所示:

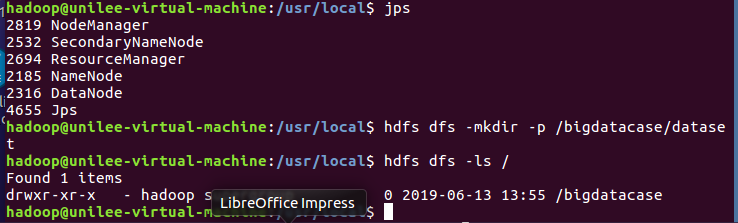
接着,启动hadoop, 在HDFS上建立/bigdatacase/dataset文件夹
并且把user_table.txt上传到HDFS中 步骤如下:
查看HDFS中的User_table.txt的前10条记录,如下图所示:

启动MySQL数据库、启动Hadoop、启动Hive,进入命令行 在Hive中创建一个数据库dblab,如下图所示:
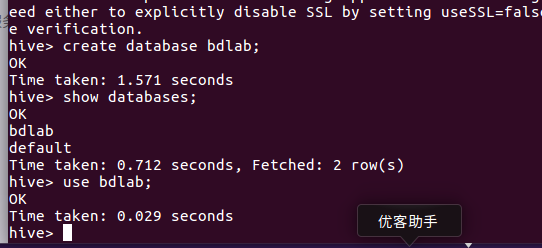
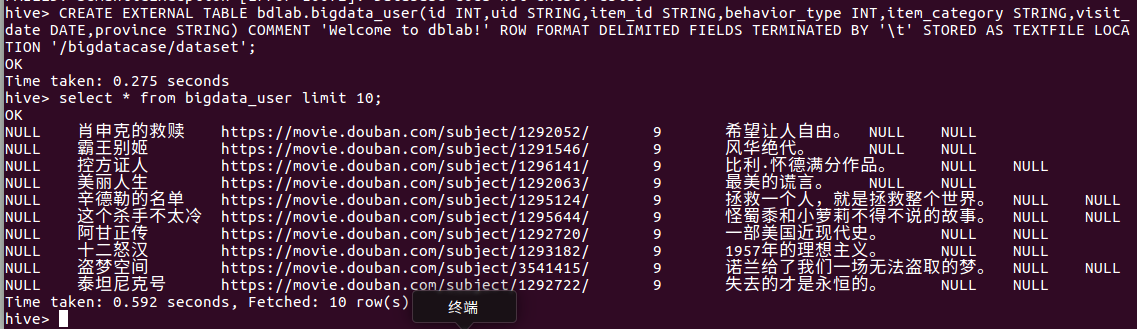
创建外部表,把HDFS中的 /bigdatacase/dataset 目录下的数据加载到Hive仓库中,
并且显示 bigdata_user 前十条数据. 如下图所示:
查询前10位豆瓣用户对电影的评分, 如下图所示:

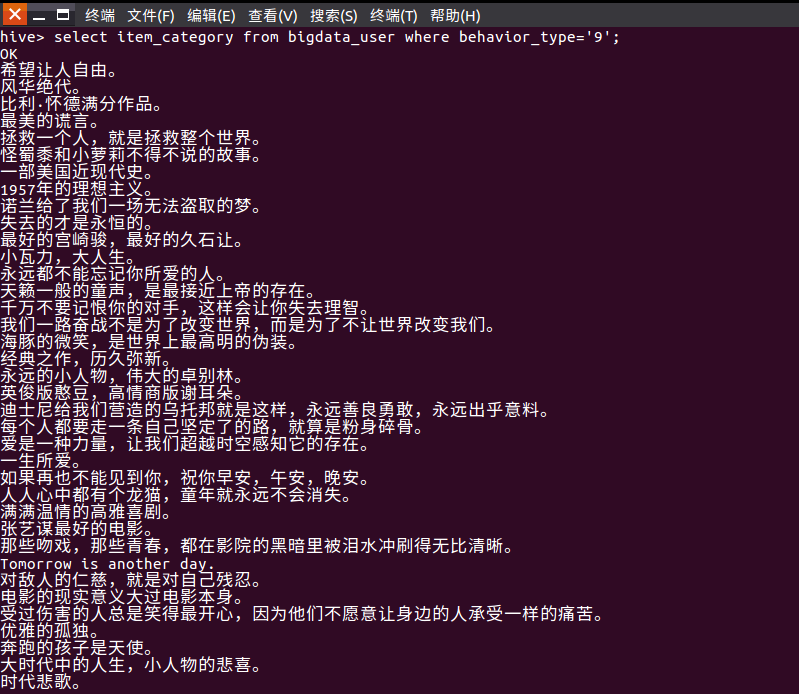
查询电影评分为9分 的用户对电影的评价。 如下图所示:
查看豆瓣中电影评分小于8分的电影 如下图所示:

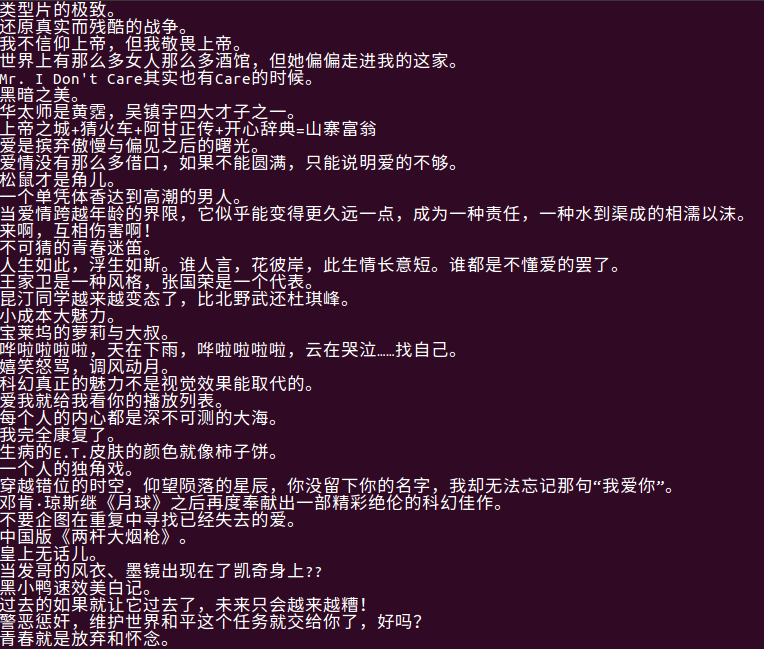
查看豆瓣中电影评分少于8分的电影的文字评价。如下图所示:
总结:通过这学期的学习我对Hadoop的 mapreduce还有hdfs文件系统有了更加深层次的理解,也对hive的创建数据库、
结构化查询的功能更加深入了解。 更加学习了python.明白了这门课程的真正用途,这学期的课学到了很多新的知识,也
复习了以前的知识,让我对计算机有了更加深层次的理解!