作业要求源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363
一、将爬虫大作业产生的csv文件上传到HDFS
(1)在 windows 通过共享文件夹将爬取的vsc文件传进 Linux 。
(2)使用jps命令查看服务启动情况。创建hive目录,去掉census_all_data.csv文件的第一行数据。
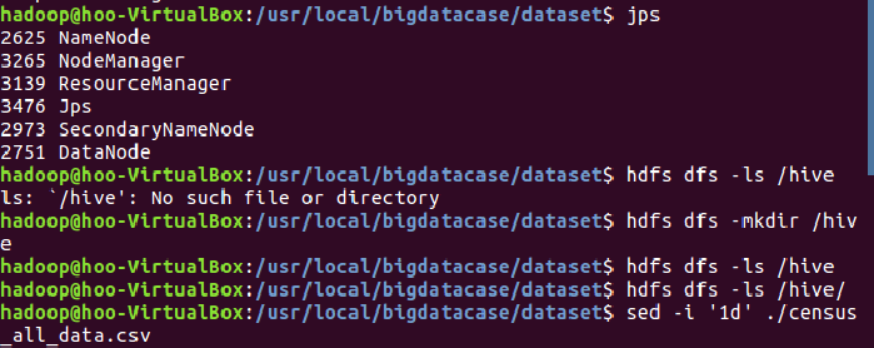
(3)将census_all_data.csv文件上传到HDFS。

二、对CSV文件进行预处理生成无标题文本文件
(1)对census_all_data.csv文件进行预处理。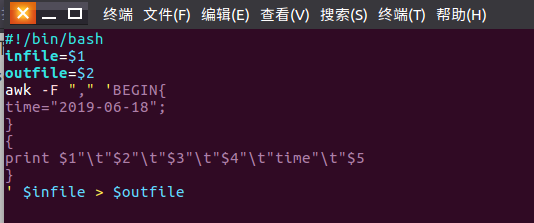
三、把hdfs中的文本文件最终导入到数据仓库Hive中
(1)进入数据仓库 hive ,创建并使用censusdb数据库。
(2)创建表censustb,并为其指定census_all_data.csv文件路径为/hive,将HDFS中的census_all_data.csv文件导入数据仓库hive中。

四、在Hive中查看并分析数据
(1)sql语句查询表census所有省份名。
(2)sql语句查询表censustb的前10条信息。
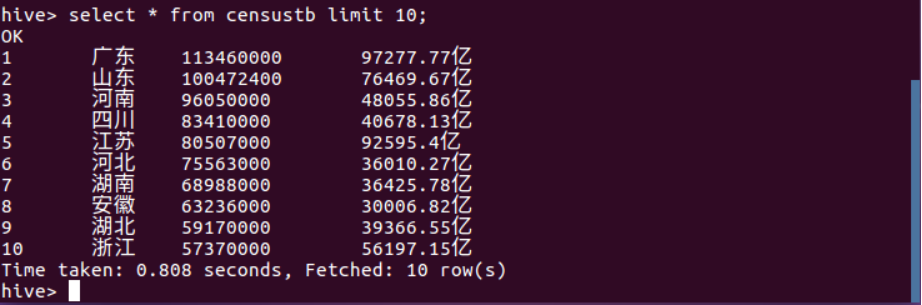
(3)查询censustb表中的信息数量。

(4)
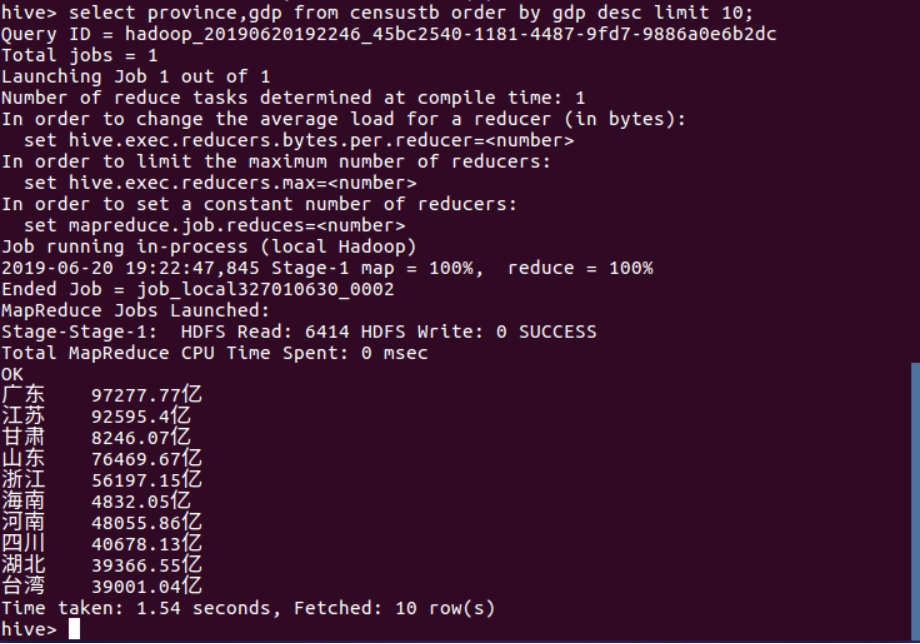
(5)

(6)

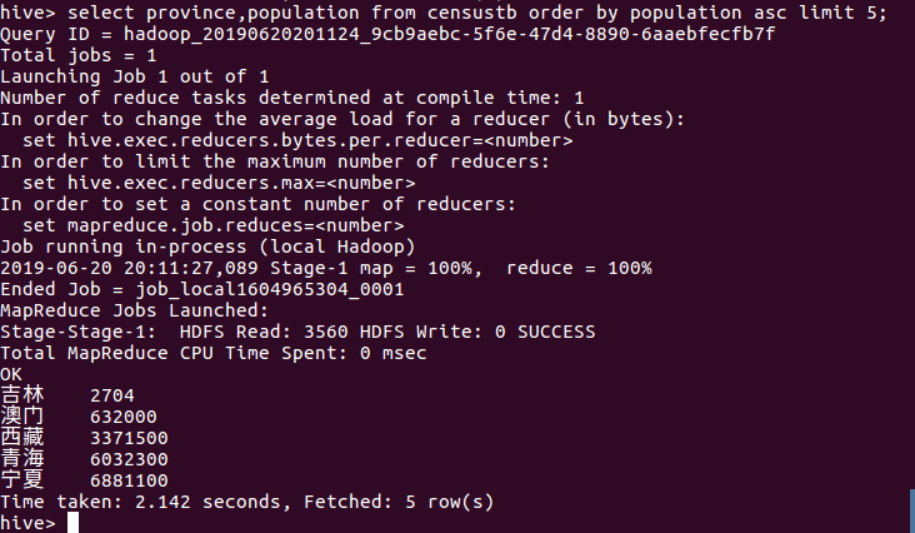
(7)
(8)
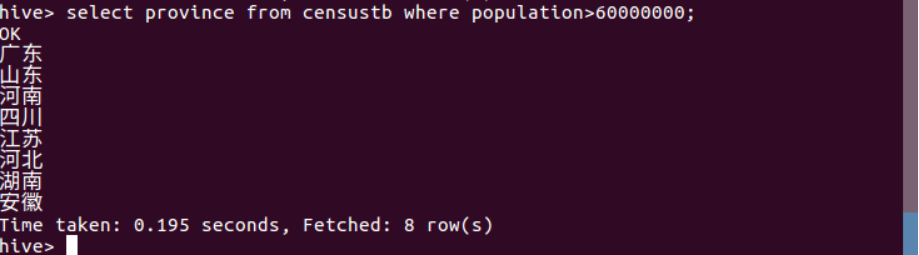
(9)
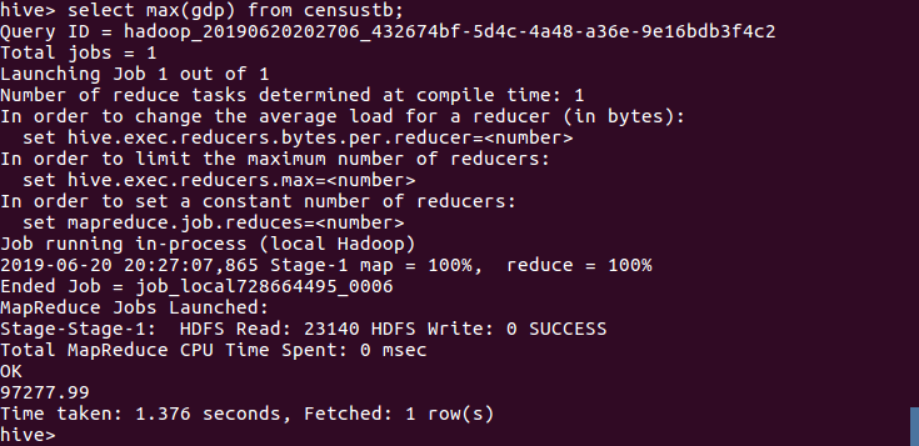
(10)
五、总结