目录
考点
- 判断(20)简答(20)问答(60)
- 三个公式的基本运用
- 不考太复杂的算法
- 系统部分:hadoop,spark,hiracks,spark streaming
- 去年题型:
- 结点扩容,如何使负载均衡
- 数字存储改为字符串存储
- 根据三个公式计算期望、方差和质量保证
算法(记忆)
亚线性空间算法
Morris算法

FM算法(弗拉约利特-马丁算法)

BJKST算法

Misra Gries算法(米斯拉·格里斯算法)

Final Count Sketch算法

AMS算法

Bloom Filter
- 用于检索一个元素是否在一个集合中

亚线性时间算法
连通分量

最小生成(支撑)树
如何计算C(i) ?

图的平均度

时间亚线性判定算法
e-远离
排序链表搜索:先抽样S,找p,q,再从原数据列表中从p搜到q。
- 全0数组判定:独立抽取s=2/e个位置上的元素进行检查。
- 数组有序判定:独立抽取q=2/e个,对qi的两边二分查找。
- 串相等判定:看成二进制数,n位上的n个数求和,判断是否相等。
大数据计算系统和管理系统
Hapdoop
调度:迭代执行机制
Hive
Spark
- 调度:DAG
- Spark streaming
| hadoop | 磁盘IO开销大,延迟高,表达能力有限,在前一个任务执行完成前其他任务无法开始 |
| spark | j基于MapReduce,还提供了多种数据集操作模型;提供内存计算;基于DAG的任务调度执行机制 |
- spark生态系统
- “一个软件栈实现不同应用需求”
- spark可以部署在资源管理器YARN上
- 同时支持批处理、交互式查询和流数据处理

(资源虚拟化层、存储层、处理层,访问接口层)

- spark 运行架构

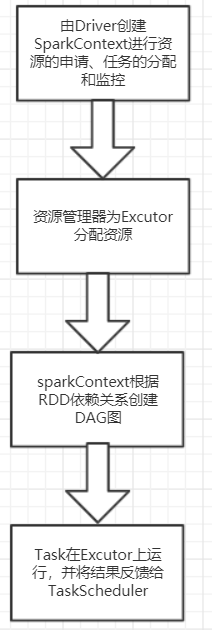
- RDD:分布式内存
- DAG:有向无环图
- 将内存和磁盘共同作为存储设备,有效减少IO开销
- spark 运行架构特点
- 利用多线程来执行具体的任务
- 运行过程与资源管理器无关
- Task采用了数据本地性和推断执行等
RDD
- 只读的共享内存模型
粗粒度转换
高效
- 创建RDD


优点:管道化、不需要保存中间结果,惰性调用,避免同步等待,每次操作简单
Spark Streaming和Storm
- 基于实时数据处理
NoSQL
- 键值数据库、列族数据库、文档数据库和图数据库
- ACID
- 原子性
- 一致性
- 隔离性
- 持久性
- 三大基石:CAP、最终一致性和BASE。
- CAP:一致性、可用性和分区容忍性。只能三选二。
- BASE:基本可用、软状态和最终一致性。
优化方法

不懂

