文章基于Apache Flink 1.7的文档翻译而来
https://ci.apache.org/projects/flink/flink-docs-release-1.7/concepts/programming-model.html
https://ci.apache.org/projects/flink/flink-docs-release-1.7/concepts/runtime.html
文章目录
数据流编程模型
抽象级别
Flink提供了不同的抽象级别用于开发 流式/批处理 应用。
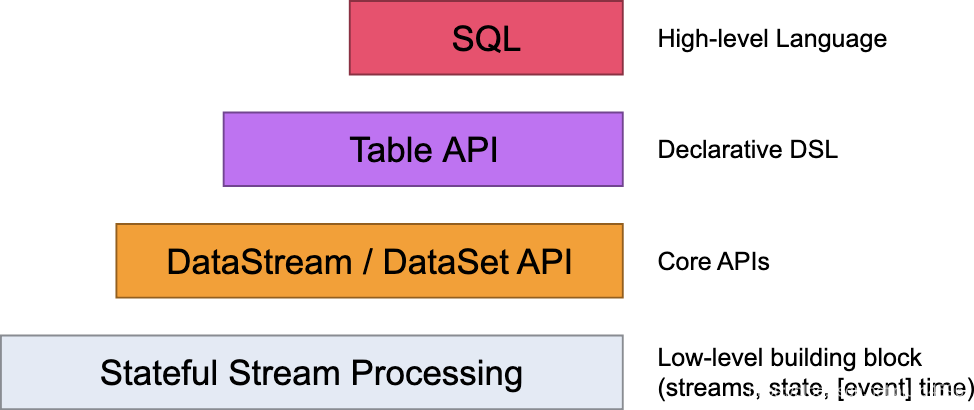
最底层的抽象仅仅简单地提供了有状态的流。它集成在通过过程函数(Process Function)访问的 数据流API(DataStream API 中。它允许用户在一个或多个流中任意处理事件,并且可以使用一致性的状态容错机制。附加的,用户可以注册事件时间并且处理时间回调函数,允许程序实现复杂运算。
实践中,大部分应用都不需要基于底层抽象订阅实现,常用的是核心API如数据流API(DataStream API(有限流/无限流)和数据集API(有限数据集合)。流式API(fluent API)提供了数据处理的常规构建模块,如大量指定类型转换(user-specified transformations),联合(joins),聚合(aggregations),窗口(windows),状态(state)等形式。在这些API中处理的数据类型以各自程序语言的类形式呈现。
数据流API融合了底层过程函数,能够只针对某些确定的操作执行底层抽象。数据集API针对有限数据集合提供了附加的原始类型,如循环/迭代(loops/iterations)。
表API(Table API) 是一套围绕表的声明式特定领域语言(DSL -> domain-specific language),在流展示时有可能动态修改表。表API遵循(扩展的)关系模型:表会有附加规格(类似关系型数据库中的表)并且API提供类似的操作,如select, project, join, group-by, aggregate等。表API程序显式定义了逻辑操作应当如何执行而不是给出这些操作的详细代码.尽管表API能够被用户定义方法扩展为很多类型,代价比核心API稍高,但是更加易用(较少代码)。而且表API在执行前还会由优化器执行优化规则。
在表和数据流/数据集之间可以无缝切合,并且允许程序混合使用表API和数据流/数据集API
Flink提供的最高级抽象就是SQL。无论从语意或者表现上都类似于表API,以SQL查询语法的方式呈现。SQL抽象和表API有密切关联,并且SQL的查询可以直接在表API定义的表上执行。
程序与数据流
构建Flink程序的基础模块就是流和转换。(注意在Flink的数据集API中使用的数据集底层还是流–后面会详细讲。)理论上流就是(无限的)数据记录的流,转换就是将一个或多个流作为输入,并且输入一个或多个流作为结果。
Flink程序在运行时会被映射至由流和转换操作组成的持续数据流。每个数据流都是从一个或多个源(sources)开始,结束于一个或多个汇(sinks)。这些数据流类似于任意的有向无环图(DAGs)。尽管环的具体形式一般是通过迭代结构来访问,大部分我们会直接忽略这个部分。
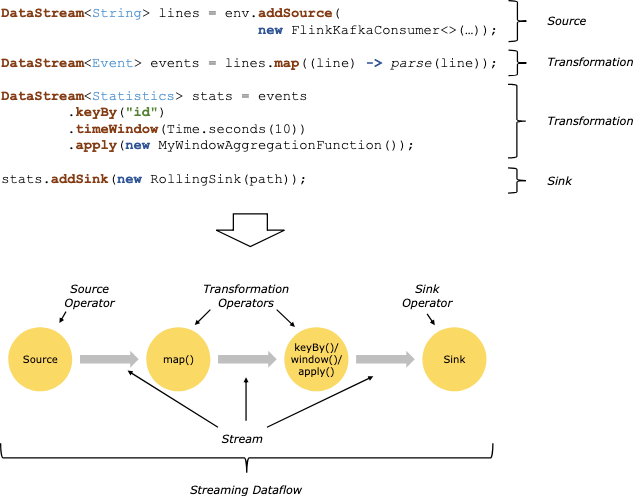
在程序中的转换和数据流的操作一般都是一一对应的。但是某些情况,会存在一个转换由多个转换操作组成。
源和汇记录在流连接器和批连接器的文档中。转换记录在数据流操作和数据集转换中。
并行数据流
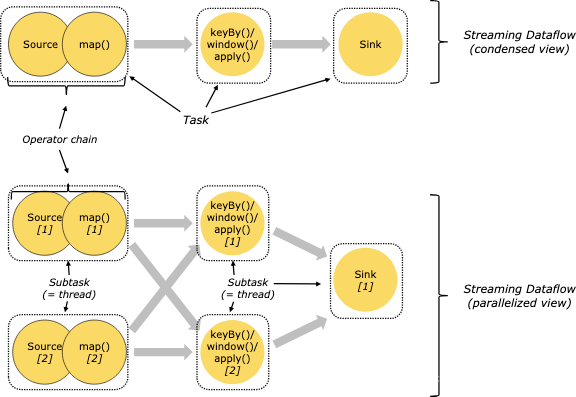
Flink的程序天然就是并行和分布式的。在执行时,一个流包含一个或多个流区块,一个操作会包含一个或多个操作子任务。操作子任务相互独立,可能会在不同线程或者不同的机器/容器中执行。
操作子任务的数量就是特定操作的并发量(parallelism),流的并发量就是它的输出操作。同一个程序的不同操作可能包含不同级别的并发量。
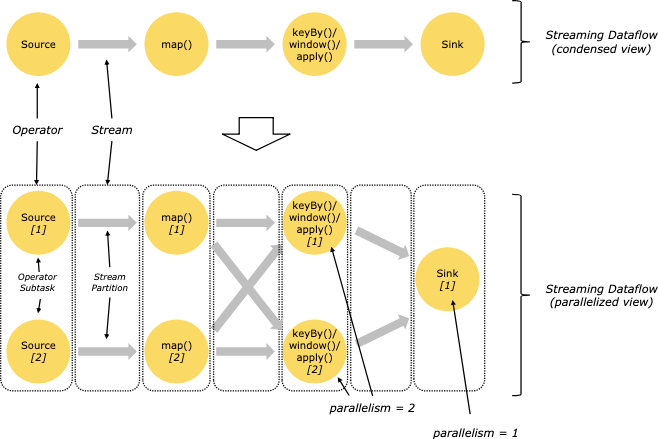
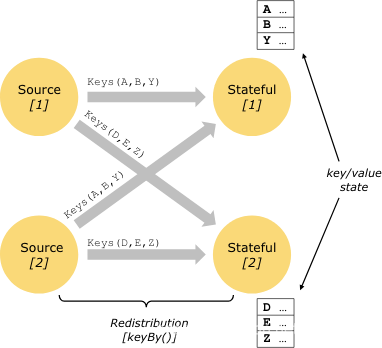
当存在两个操作是一对一(或者正向)模式或者重分配模式时,流能够在它们直接传输数据:
- 一对一流(例如上图中在Source和map()之间的操作)保留了元素的分块和顺序。意味着map()操作的子任务[1]会以相同的元素和相同的顺序接收到Source操作产生的子任务[1]。
- 重分配流(例如上图中在map()和 keyBy/window,以及 keyBy/window和Sink)会改变流的分块。每个操作子任务都将数据传输到不同的目标子任务,如何分发依赖于选择的转换。例如keyBy()(使用key的哈希值将数据重新分块),broadcast(),或者rebalance()(随机数据重新分块)。在一个重分配交换中,元素之间的顺序只会在每对发送和接受的子任务间保持(例如子任务[1]的map()和子任务[2]的keyBy/window)。在这个例子中,每一个key的顺序是能够保持的,但是并行计算时,不同key在聚合结果集中到达sink的顺序是不确定的。
并行计算的配置和控制详情可以在并行计算文档查看。
窗口
聚合事件(如,counts,sums)在批处理和流处理中是不同的。例如,在流中是不可能对所有元素进行计数的,因为流是无限的(无边界)。流中的聚合计算(counts,sums等)是通过窗口来限定的,例如“统计过去5分钟”,或者“合计最新的100个元素”。

窗口可以是时间驱动的(例如:每30秒)或者数量驱动(例如:每100个元素)。典型的窗口不同分类,例如滚动窗口(不会重叠),滑动窗口(可能重叠),会话窗口(可能会被静止时间打断)。
Time- and Count Windows
更多窗口示例能够在这篇文章中查看,更多详情在这篇关于窗口的文档中。
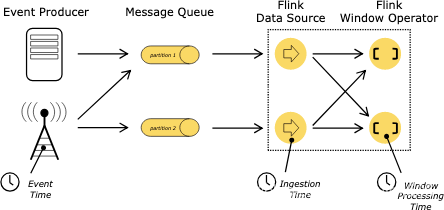
时间
当在流程序中涉及到时间(例如定义窗口时),有如下几种时间的定义:

- 事件时间是事件创建的时间。它在事件中通常会时间戳形式记录,例如由生产传感器或者生产服务产生。Flink通过时间戳归属来访问事件时间戳。
- 进入时间是事件进入Flink数据流的源操作的时间。
- 处理事件是每个操作执行基于时间的操作花费的本地时间。
关于处理时间的更多详情可以查看事件时间文档。
有状态操作
当一个数据流中的很多操作同时观察一个独立事件时(例如事件转换器),有些操作会在多个事件中记住信息(例如窗口操作)。这样的操作就被称为有状态的。
有状态操作的状态可以认为是在用个内部的键值对存储中维护的。这些状态是会在被有状态操作读取的流中分块和散布的。因此只有在有主键(keyed)的流中才可以访问键值对状态,并且是在*keyBy()*方法之后,而且只能访问当前事件的key所对应的值。校准流和状态的key能够保证所有的状态更新都是本地操作,不需要额外的事务来保证一致性。这样也能够允许Flink重新分配状态,并且轻易的调整流的分块。
更多信息可以在状态文档查看。
容错检查点
Flink是通过流重放和检查点的组合来实现容错的。检查点是指在每个输入流中包含每个操作的相关状态的特殊点。所以数据流能够从检查点重新开始以保证一致性(严格只处理一次),并且需要我们保存操作的状态,并且从检查点开始重放后续事件。
检查点间隔意味着测量容错恢复的执行时间(需要被重放的事件的数量)。
容错内部机制文档提供了更多关于Flink如何管理检查点以及相关主题。打开与定义时间点的更多详情在时间点API文档中。
流的批处理
Flink是把批处理当作一个特殊的流式程序来处理,只是流是有界的(有限数量元素)。数据集内部是作为一个数据的流。这样的概念就使得我们处理批处理程序和流程序是一样的,但会有一些轻微的异常:
- 批处理中的容错不使用检查点,而是重放完整的数据流,因为数据是有界的。所以批处理的恢复效率更低,但是正常处理效率更高,因为无需添加检查点。
- 数据集API的有状态操作简单的内存或者外部存储结构,而不是键值对索引。
The DataSet API introduces special synchronized (superstep-based) iterations, which are only possible on bounded streams. For details, check out the iteration docs.
分布式运行环境
任务与操作链
在分布式执行中,Flink将操作子任务链在一个任务内。每个线程执行一个任务。将操作链入任务是个非常有效的优化:它减少了线程之间的交换和缓存损耗,通过低延迟提高了整体吞吐量。链的行为是可以被定义,在链文档中查看明细。
下图中的数据流执行了5个子任务,因此需要5个并发线程。(要看图的下半部分,是有5个子任务的。)
JOB管理,任务管理,客户端
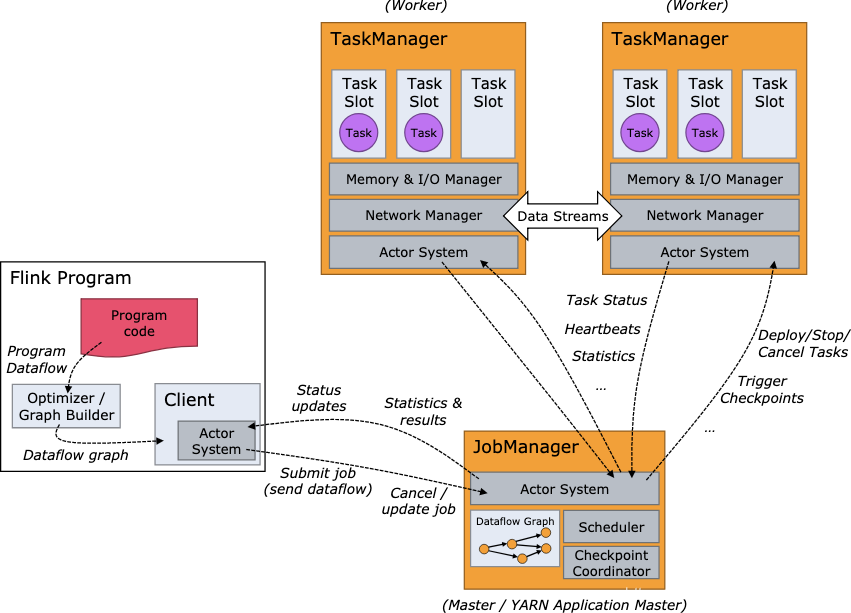
Flink的运行过程定义了两种处理方式:
-
JOB管理(JobManagers)(也称为管理节点)协调管理整个分布式执行过程。它们负责来安排任务,协调检查点,以及错误恢复等。
至少要有一个JOB管理节点。建议多台JOB管理形成高可用,一台为管理,其他待命。 -
任务管理(TaskManagers)(也称为执行节点)执行数据流中的实际任务(更具体就是子任务),并且缓存和交换数据流。
同样也至少要有一个任务管理节点。
JOB管理和任务管理节点可以以多种方式运行:可以在单台机器作为单例集群,或者在容器中运行,或者由资源管理框架如YARN2或者Mesos3来运行。任务管理节点连至JOB管理节点,声明自己的有效性,然后被分配任务。
客户端并不是运行或者程序执行过程中的一部分,但是可以用于准备并发送数据流给JOB管理节点。完成之后客户端就可以断开了,或者保持连接接收处理报告。客户端一般是触发执行的Java/Scala程序的一部分,或者在命令行中直接执行 ./bin/flink run
任务槽和资源
每个执行节点(任务管理)都是一个JVM进程,可以再不同的线程中执行一个或者多个子任务。为了控制一个执行节点能够运行多少任务,一个执行节点也可以称为任务槽(至少一个)。
每个任务槽都是任务管理的一个确定的资源子集。例如一个任务管理包含三个任务槽,会将自身管理的内存分给每个任务槽1/3。分槽意味着一个子任务不会与另外一个JOB的子任务争抢内存资源,而是给定的内存资源总量。注意CPU资源不会隔离,目前的任务槽只会隔离内存管理。
通过调整任务槽数量,用户可以决定子任务之间的隔离策略。一个任务管理节点只设置一个任务槽意味着每个任务组都是运行在一个单独的JVM进程中的(这个进程也可以是在一个容器中启动的)。设置多个任务槽则会多个子任务会共用相同的JVM。同一个JVM中的任务会共用TCP连接(通过复用)和心跳信息。也可以共享数据集和数据结构,因此能够降低单个任务的资源消耗。
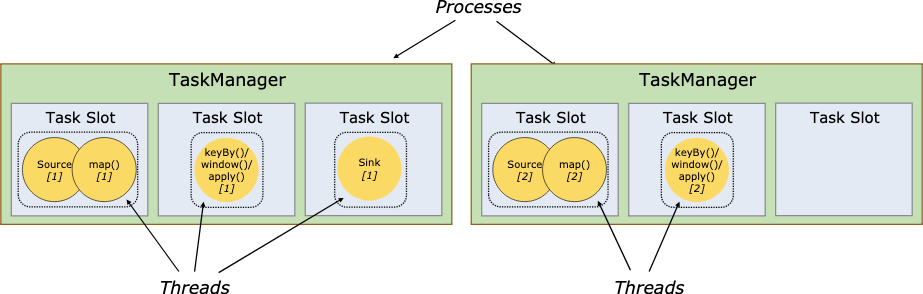
Flink默认是允许不同任务的子任务共享任务槽,只要是同一JOB发起的。一个槽可能会包含一个JOB的完整管道。允许任务槽共享有2个主要的好处:
- Flink集群中的任务槽的数量只要和JOB中的最高并行数量相同即可。不需要计算一个程序中总共包含多少个任务(以及他们不同的并行数量)。
- 能够达到更高的资源使用率。如果没有任务槽共享,分散的 source/map() 子任务就会被集中的 窗口 子任务占用的资源阻塞。但是任务槽可以共享,在我们的例子中增加基础并行数量,从2个加到6个,提高了任务槽的资源使用率,并且能够确保重度子任务能够均匀的分布在任务管理节点中。
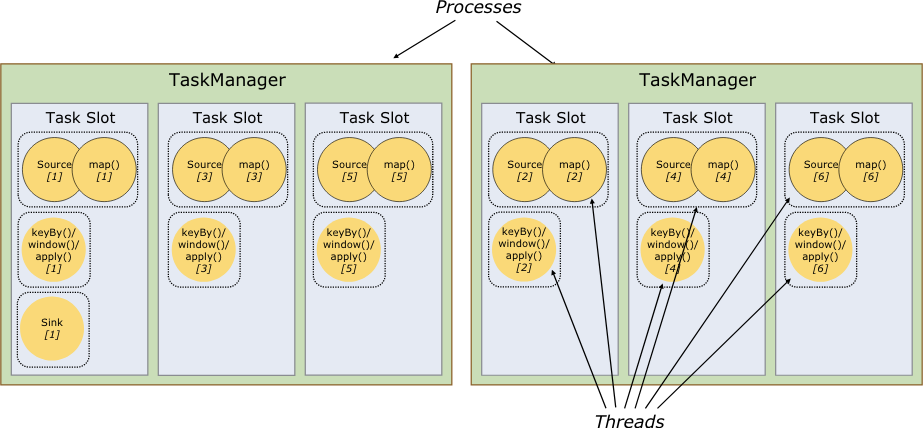
API还包含了资源组机制用于防止不受控的任务槽共享。
根据经验法则,任务槽的数量和CPU内核的数量保持一致是比较合理的。使用超线程技术时,每个任务槽可以使用2个或者更多的硬件线程。
状态后端
键值对索引的存储的具体的数据格式取决于选择的状态后端。状态后端可以存储在内存中的HashMap,也可以使用RocksDB作为键值对存储。另外为了使得数据结构能够保存状态,状态后端也实现键值对状态保存时间点快照的业务逻辑,从而能够生成检查点。
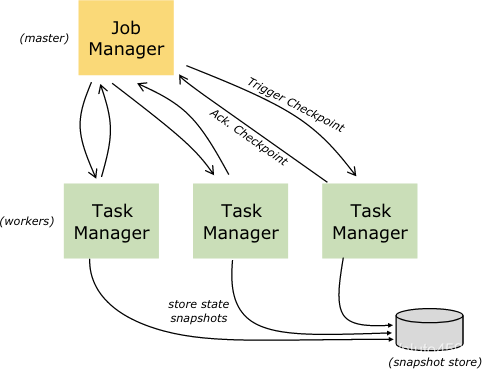
保存点
通过数据流API编写的程序能够从一个保存点重新开始执行。保存点能够允许同时更新你的程序和Flink集群而不丢失任何状态。
保存点手动触发检查点,生成程序的快照并且写入到状态后端中。保存点依赖于常规的检查点机制。执行过程中,程序周期性的生成工作节点的快照,并且生成检查点。恢复只需要最后一个完整的检查点,并且当信的检查点点完整生成后旧的检查点就可以安全的丢弃。
保存点和周期性的检查点很相似,但是它们是由用户触发产生并且当新的检查点生成后不会自动过期。保存点是由命令行或者通过REST API取消任务时生成的。
超步(superstep)包含三部分内容:
(1).计算compute:每一个processor利用上一个superstep传过来的消息和本地的数据进行本地计算;
(2).消息传递:每一个processor计算完毕后,将消息传递个与之关联的其它processors
(3).整体同步点:用于整体同步,确定所有的计算和消息传递都进行完毕后,进入下一个superstep。 ↩︎Apache Hadoop YARN(Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。 ↩︎
Apache MesosApache下的开源分布式资源管理框架,它被称为是分布式系统的内核。Mesos最初是由加州大学伯克利分校的AMPLab开发的,后在Twitter得到广泛使用。 ↩︎