前言
仍然是学概念,以下大部分是对官方doc的翻译,但是也会有些个人的理解(主要是对比Spark),以及查找的一些解决自己的一些疑惑相关资料。
从Flink 的数据流编程模型和分布式运行环境的基本概念开始学习会对您了解其他部分的文档有帮助,包括安装以及编程指南。强烈推荐先阅读这两部分文档。
数据流编程模型
抽象级别
Flink提供了不同的抽象级别以支持开发流式、批处理等应用。
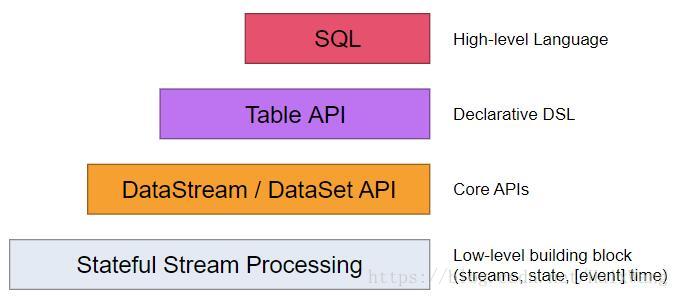
- 最底层级的抽象仅仅提供了有状态流处理。它将通过过程函数(Process Function)嵌入到DataStream API中。它允许用户自由地处理来自一个或多个流数据的事件,并使用一致、容错的状态。除此之外,用户可以注册事件时间和处理事件回调,从而使程序可实现复杂的计算。
- 实际上,大多数应用并不需要上面所说的最底层抽象,而是针对 核心API(Core APIs) 进行编程,比如DataStream API(有界或无界流数据)以及DataSet API(有界数据集)。这些流畅的API为数据处理提供了通用的构建模块,比如由用户定义的多种形式的**转换(transformations),连接(joins),聚合(aggregations),窗口操作(windows),状态(state)等等。这些API处理的数据类型以类(classes)的形式由各自的编程语言所表示。
- Table API 是以表为中心的声明式DSL,其中表可能会动态变化(在表达流数据时)。Table API遵循(扩展的)关系模型:表具有附加的模式(类似于关系数据库中的表),同时API提供可比较的操作,例如select、project、join、group-by、aggregate等。 尽管Table API可以通过多种类型的用户定义的函数进行扩展,其仍不如 核心API 更具表达能力,但是使用起来却更加简洁(代码量更少)。此外,Table API程序还会通过优化程序,在执行之前应用一些优化规则。
【暂时理解为SQL优化?比如Hive中的SQL优化?】【TODO:哪些优化?】 可以在表和DataStream / DataSet之间无缝转换,允许程序混合Table API以及DataStream和DataSet API。
补充: 与常规SQL语言中将查询指定为字符串不同,Table API查询是以Java或Scala中的语言嵌入样式来定义的,具有IDE支持如:自动完成和语法检测。Elasticsearch有基于json的查询DSL,不知道是否可以类比理解。
Table API可以用于Scala和Java中,Scala Table API利用了Scala表达式,Java Table API则是基于字符串来的,字符串会被解析并转换成等价的表达式。
对于Table API,以后细学、使用时是再做记录,现在的话,大家可以参考简书——写Bug的张小天:Flink的Table API
- Flink提供的最高级抽象是SQL。这种抽象在语义和表达方面类似于Table API,但是将程序表示为SQL查询表达式。 SQL抽象与Table API紧密交互,SQL查询可以在Table API中定义的表上执行。
我对Table API 和 SQL 的理解:
- 同SQL一样,这些API操作的对象,也是表。一些情况下,这些通过这些API可以得到与SQL语句相
同的结果,只是Table API调用的是函数,比如tableName.groupBy()、select()、where()、filter()、distinct()、join()等,而SQL是连续的语句。所以,Table API更散一些。它们所完成的功能,确实时有重叠的。 - 要类比的话,Flink中的Table就好比如Spark DataFrame,DataFrame中也可以用groupByKey、union、join这些算子,而SQL这边,可以使用SQL语句。
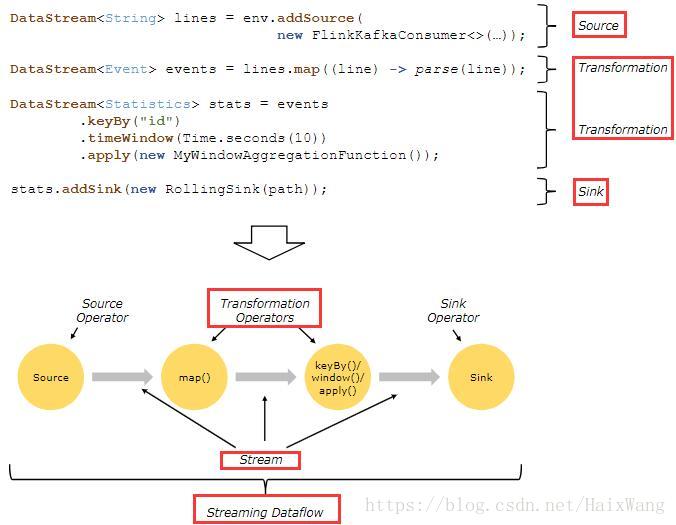
程序与数据流
Flink程序的基础构建模块是 流(streams) 与 转换(transformations)。从概念上来讲,流是(可能永无止境的)数据记录流,而转换是一种操作,它取一个或多个流作为输入,并生产出一个或多个输出流作为结果。
- 执行时,Flink程序会被映射到streaming dataflows【整个流程称之为streaming dataflow】 ,streaming dataflow由流以及转换算子构成。
- 每一个数据流起始于一个或多个 source,并终止于一个或多个 sink。
- 数据流类似于任意的有向无环图 (DAG) 。虽然通过迭代构造允许特定形式的环,但是大多数情况下,简单起见,我们都不考虑这一点。
类比Spark:
Spark执行程序时,通过宽窄依赖来划分Stage,然后也是组织为DAG,由TaskScheduler、DAGScheduler执行相应操作。所以,Flink是又怎样调度作业的?
并行数据流
Flink程序本质上是并行分布的。在执行过程中,一个 流 包含一个或多个 流分区(stream partitions) ,而每一个 operator 包含一个或多个 子operator 任务(operator subtasks) 。operator 子任务间彼此独立,以不同的线程执行,甚至有可能运行在不同的机器或容器上。
operator subtasks的数量即这一特定operator 的 并行度 。【同Spark并行度概念。】
forwarding模式与redistributing模式
流在两个算符之间传输数据,可以通过 一对一 (或称 forwarding )模式,或者通过 redistributing 模式。
【forwarding的概念类似于Spark中的窄依赖,只是暂时不知道Flink的forwarding模式是否包含多对一;redistributing模式类似于宽依赖,数据可以一对多。】
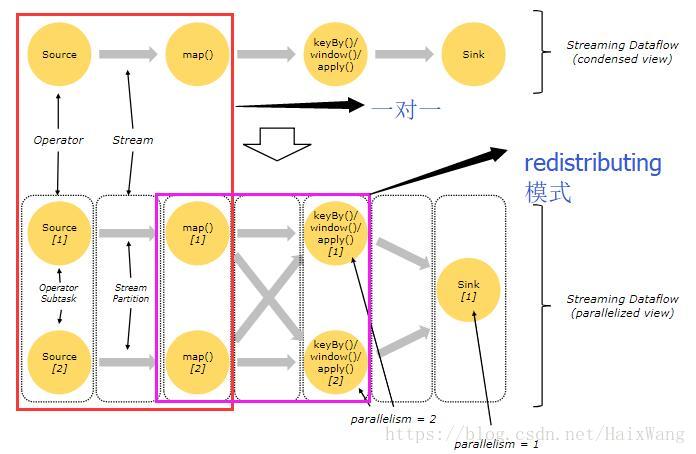

- 一对一 流(例如上图中 Source 与 map() 算符之间)保持了元素的分区与顺序。意味着 map() 算符的子任务[1]将以与 Source 的子任务[1]生成顺序相同的顺序查看到相同的元素。
That means that subtask[1] of the map() operator will see the same elements in the same order as they were produced by subtask[1] of the Source operator.
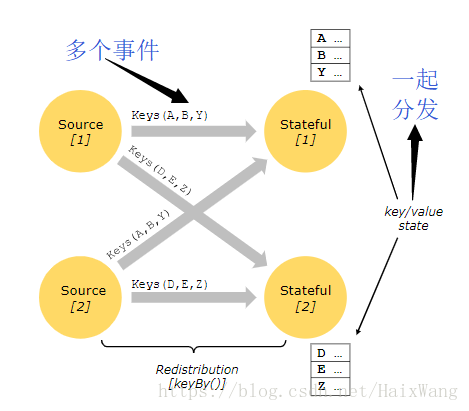
- Redistributing 流(如上图中 map() 与 keyBy/window 之间,以及 keyBy/window 与 Sink 之间)则改变了流的分区。每一个 operator 子任务 根据所选择的转换,向不同的目标子任务发送数据。比如 keyBy() (根据key的哈希值重新分区), broadcast() ,或者 rebalance() (随机重分区)。在一次 redistributing 交换中,元素间的排序只保留在每对发送与接受子任务中(比如, map() 的子任务[1]与 keyBy/window 的子任务[2])。因此在这个例子中,每个键的顺序被保留下来,但是并行确实引入了不确定性——对于不同键的聚合结果到达sink的顺序。
but the parallelism does introduce non-determinism regarding the order in which the aggregated results for different keys arrive at the sink.
窗口
流上的聚合事件(比如counts、sums)工作方式与批处理不同。
比如,对流中的所有元素进行计数是不可能的,因为流通常是无限的(无边界的)。
解决方案是;流上的聚合由窗口来划定范围,比如 “count over the last 5 minutes”” ,或者“sum of the last 100 elements” 。
窗口可以是时间驱动的(比如:每30秒)或者数据驱动的 (比如:每100个元素)。
窗口通常被区分为不同的类型,比如 滚动窗口 (没有重叠), 滑动窗口 (有重叠),以及 会话窗口 (由不活动的间隙所打断——punctuated by a gap of inactivity)

时间
当在流程序中(例如定义窗口)提到时间时,你可以参考以下不同的时间概念:
-
事件时间 是一个事件被创建的时间。它通常由事件中的时间戳描述。Flink通过时间戳分配器——timestamp assigners访问事件时间戳。
-
摄入时间 是事件进入Flink数据流的source operator的时间。
-
处理时间 是每一个执行时间操作的算符的本地时间。
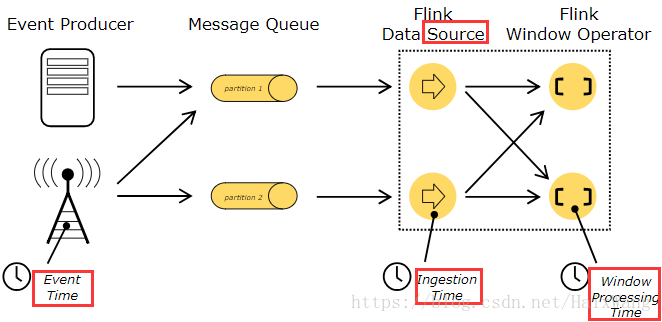
关于如何处理时间的更多细节可以查看文档:事件时间。
有状态操作 Stateful Operations
虽然数据流中的很多操作一次只查看一个独立的事件(比如事件解析器),但有些操作却会记录多个事件间的信息(比如窗口算符)。 这些操作被称为 有状态的 。
有状态操作的状态保存在一个可被视作嵌入式键/值存储的部分中。
状态与stateful operators读取的流一起,被严格地分区与分布——partitioned and distributed。因此,只能在keyBy() 函数之后才能访问keyed streams 上的键/值状态,并且仅限于与当前事件键相关联的值。
对齐streams中的key、state确保了所有状态更新都是本地操作,以在没有事务开销的情况下确保一致性。这种对齐还使得Flink可以透明地重新分配状态与调整流的分区。
更多信息请参阅文档:状态。
容错检查点
Flink通过使用 流重播——stream replay 与 检查点 结合的方式实现了容错。检查点与每个输入流中的特定点以及每个操作符的对应状态相关。 A streaming dataflow can be resumed from a checkpoint while maintaining consistency (exactly-once processing semantics) by restoring the state of the operators and replaying the events from the point of the checkpoint.(一个streaming dataflow可以从一个检查点恢复出来,其通过恢复operators的状态并从检查点重播事件来保持一致性 (恰好一次处理语义))。
流上的批处理
Flink将批处理程序作为流处理程序的特殊情况,只是这种情况下的流是有界的(有限个元素)。 DataSet 内部仍被视为数据流。
上述适用于流处理程序的概念同样适用于批处理程序,下面是一些区别:
-
DataSet API中的程序不使用检查点。而通过完全地重播流来恢复。因为输入是有界的,因此这是可行的。这种方法使得恢复的成本增加,但也正是因为避免了检查点,使得正常情况下的处理的开销更小。
-
DataSet API中的有状态操作使用简化的im-memory/out-of-core数据结构,而不是键/值索引。
-
DataSet API引入了特殊的同步(基于superstep的)迭代,而这种迭代仅仅能在有界流上执行。细节可以查看迭代文档。
还是不知道流怎样变为批的,感觉应该是时间窗口,但是上文又说窗口与批处理不同。。。