集群与分布式区别
集群:复制模式,每台机器做一样的事。
分布式:两台机器分工合作,每台机器做的不一样。
分布式好处:
- 独立开发,部署,测试
- 易于扩展
- 复用性高,例如:所有的产品都可以使用该系统作为用户系统,无需重复开发。
架构演进
架构演进一: 早期雏形
特征:应用程序主要做静态文件读取,返回内容给浏览器。
架构演进二: 数据库开发(LAMP特长)
特征:应用程序主要主要读取数据表值,填充html模块。业务逻辑简单,写sql处理。
主要:增删改查
主要压力:来自查询,多表联合,数据量膨胀。
架构演进三: javaweb的雏形
tomcat + servlet + jsp + mysql。一个war包打天下
项目结构:ssh/ssm三层结构。
架构演进四: javaweb的集群发展
硬件机器的横向复制,对整个项目结构无影响。
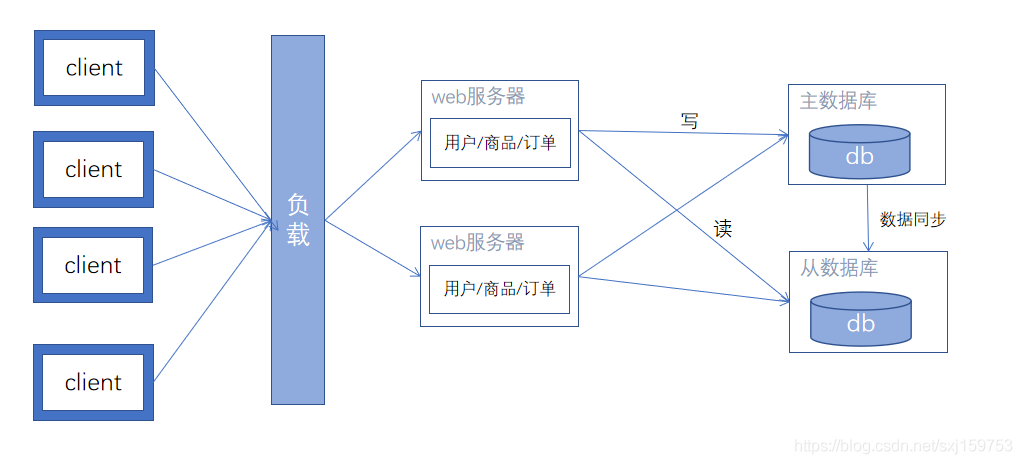
架构演进五: javaweb的分布式发展
特征:将Service层单独分离出去,成为一个单独的项目jar。单独运行。
Web服务器通过rpc框架,对分离出去的service进行调用。
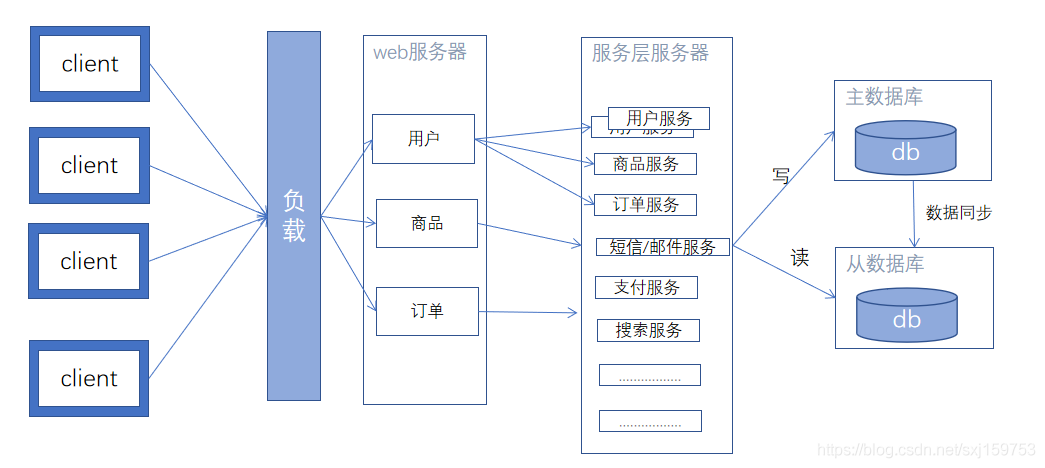
架构演进六: javaweb的微服务发展
从业务角度,细分业务为微服务,每一个微服务是一个完整的服务(从http请求到返回)。在微服务内部,将需要对外提供的接口,包装成rpc接口,对外部开放。
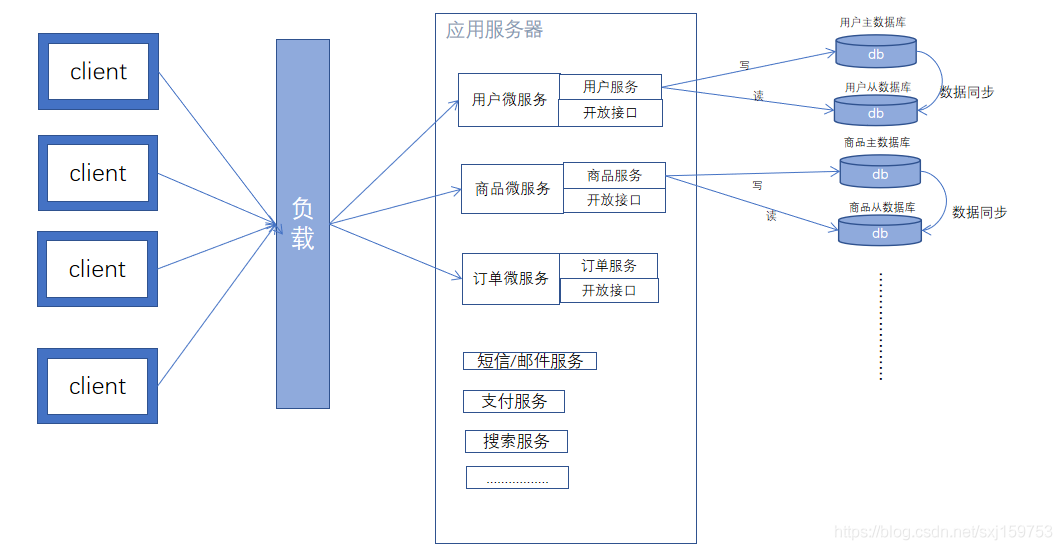
服务治理:
1、无论是分布式拆分,还是微服务拆分,最后形成的服务层应用,都需要相互之间调用。
2、这种服务间调用是跨系统的。跨系统调用rpc有很多协议: RMI,webservice,http请求,网络达到服务间访问。
dubbo:很多,dubbo协议
springcloud:使用http协议通信
3、服务集群,有负载路由。需要服务发现–zookeeper。
4、数据积累大:订单服务—积累。
分库/分表 -----需要修改业务sql语句。(有侵入性)----------->mycat中间件。
/分区。 -------》对sql语是没有侵入性。------------》对库没办法减压。
架构一个系统依据
1、系统目标是并发数(tps)多少:tomcat的安全连接数在500tps上下
2、系统要承受的数据量级:mysql — 单表到达 700W,性能会急剧下降。
3、并发数(tps) transation per seconds:每秒钟的访问—每秒处理事务数。
架构方案:
1、首先考虑缓存方案解决性能问题
2、集群模式------比较重的模式:浪费成本
3、用分布式

缓存解决方案:
缓存服务器:redis、memcache。
一般缓存方案
1、先到缓存中查,有值直接返回
2、无值(缓存穿透、击穿)则调用接口或者查库,并将值补入缓存区
3、缓存区数据与db中可能不一致,使用过期时间调节
4、若缓存区数据集中在某一短时刻失效,将导致大量的缓存击穿(雪崩)
永不过期方案
1、不设置过期时间,数据永久有效,避免雪崩
2、需要额外机制来实现数据的同步更新(参照数据同步)
集群引起的负载问题方案,如何session共享
1、tomcat自己插件,能够session共享
2、spring-session插件,实现session共享。
大数据量的切片方案
数据分片:数据的路由保持不变
1、设置数据片数量,比如100个柱
2、当前库,均分这100个柱
3、当加库扩容时,这100个柱动态迁移
前端演进:
1、一个url > 一个html页面 > 点击按钮跳转 > 页面跳转。
2、页面,ajax方式刷新页面
3、mvvm的开发流程:
a、前端人员开发的程序包放在静态服务器里
b、浏览器访问静态服务器,得到前端html
c、html页面发起ajax请求到后台服务器,得到业务数据,渲染出页面。
