上一章学习了用 python 模拟登陆百度,其中 get 和 post 的步骤很多,在任何一个环节出错都会导致最后登陆失败,所以这个对于新手来说有点勉强。这一章介绍一个简单的登陆方式,用以获取登陆后的 cookie 。
在 python 中有一个很强大的库 selenium ,这个库能调用浏览器,利用浏览器来登录百度,再提取出 cookie ,等下次登陆的时候利用这个 cookie 就能达到登陆的效果。而且,用 selenium 模拟浏览器根本不需要管什么 get 啊 post 啊,如果条件允许下,作者还是喜欢用 selenium 。在使用 selenium 前需要做一些准备工作:
- 下载解压安装
selenium-2.45.0.tar.gz- 下载浏览器,
Chrome的版本为47.0.2526.106 m,firefox的版本为32.0.1- 下载浏览器支持插件到
python,作者的Python34是安装在C盘,所以将插件放在C:\Python34\下面,Chrome的为chromedriver.exe,firefox的为firefoxdriver.exe
解压完 selenium-2.45.0.tar.gz 后,找到 setup.py ,运行 python setup.py install 等待安装完成即可。这里为什么不用高版本的 selenium ?因为高版本的 selenium 不支持低版本的浏览器,而且高版本的浏览器插件貌似还没更新,用的时候会出现意想不到的 bug ,所以这里使用了低版本的 selenium 。安装浏览器后切记关闭浏览器的更新,Chrome 关闭更新的方法有:
C:\Program Files (x86)\Google\下直接删除update文件夹- 右键计算机 -> 管理 -> 服务 -> 禁止
firefox 同理,直接删掉升级的 exe ,再禁止掉更新服务。顺便可以在浏览器中找到设置,把设置里面的更新也停止掉。
最后将浏览器插件放到 Python34 的目录下,尝试如下代码
'''
遇到python不懂的问题,可以加Python学习交流群:1004391443一起学习交流,群文件还有零基础入门的学习资料
'''from selenium import webdriver
# browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser.get("https://www.baidu.com")
如果能成功打开浏览器,那么就证明安装成功了!如下图所示:
selenium 可以根据页面前端的 id 、 class 、 tag name 等方式定位。打开百度首页, F12 选择 点击查看页面中的元素 ,将指针放到搜索栏,点击左键:
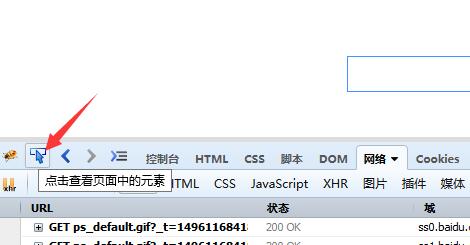
点击搜索框后可以得到搜索框的 html 代码:
<input id="kw" class="s_ipt" autocomplete="off" maxlength="255" value="" name="wd">
同理将指针放到 百度一下 按钮上面,得到百度一下的 html 代码:

<input id="su" class="bg s_btn" type="submit" value="百度一下">
可以看到搜索框的 id 是 kw , 百度一下的 id 是 su ,而利用 selenium 可以定位到搜索框,并在搜索框填写需要搜索的东西,最后实现点击百度一下,代码为:
url = "https://www.baidu.com/"
browser = webdriver.Chrome()
# browser = webdriver.Firefox()
browser.get(url)
# 清空搜索框
browser.find_element_by_id("kw").clear()
# 通过id方式定位
browser.find_element_by_id("kw").send_keys("TTyb")
# 点击“百度一下”
browser.find_element_by_id("su").click()
也可以通过 name 、 class name 、 CSS 、 xpath 定位:
# 通过name方式定位
browser.find_element_by_name("wd").send_keys("TTyb")
# 通过class name 方式定位
# browser.find_element_by_class_name("s_ipt").send_keys("TTyb")
# 通过CSS方式定位
# browser.find_element_by_css_selector("#kw").send_keys("TTyb")
# 通过xpath方式定位
# browser.find_element_by_xpath("//input[@id='kw']").send_keys("TTyb")
# 点击“百度一下”
browser.find_element_by_id("su").click()
是不是很神奇?而利用 selenium 来登陆百度会更加简单,完全不需要管 postdata ,只需要:
- 打开登陆页面
https://passport.baidu.com/v2/?login- 查找 账号 、 密码 、 登陆 的
html- 填写账号密码,直接登陆
在百度的登陆页面中,账号的 html 为:
<input id="TANGRAM__PSP_3__userName" class="pass-text-input pass-text-input-userName pass-text-input-hover" type="text" autocomplete="off" name="userName" placeholder="手机/邮箱/用户名">
密码的 html 为:
<input id="TANGRAM__PSP_3__password" class="pass-text-input pass-text-input-password" type="password" name="password" placeholder="密码" autocomplete="off">
登陆的 html 为:
<input id="TANGRAM__PSP_3__submit" class="pass-button pass-button-submit" type="submit" value="登录">
可以很明显的知道账号的 id 为 TANGRAM__PSP_3__userName ,密码的 id 为 TANGRAM__PSP_3__password ,登陆的 id 为 TANGRAM__PSP_3__submit ,用代码实现:
# 清空账号输入框
browser.find_element_by_id("TANGRAM__PSP_3__userName").clear()
# 通过id方式定位账号
browser.find_element_by_id("TANGRAM__PSP_3__userName").send_keys("username")
# 清空密码输入框
browser.find_element_by_id("TANGRAM__PSP_3__password").clear()
# 通过id方式定位密码
browser.find_element_by_id("TANGRAM__PSP_3__password").send_keys("password")
# 点击“登陆”
browser.find_element_by_id("TANGRAM__PSP_3__submit").click()
万一出现验证码怎么办?定位到验证码的 html ,手动输入验证码进去:
verifycode = input("验证码是:")
# 填写验证码
browser.find_element_by_id("验证码id").send_keys(verifycode)
# 点击“登陆”
browser.find_element_by_id("TANGRAM__PSP_3__submit").click()
登陆成功后,可以获取登录后的 cookie :
cookie = [item["name"] + "=" + item["value"] for item in browser.get_cookies()]
得到的 cookie 是一个数组,将这个数组转化为 dict ,在保存为本地的 json ,下次登陆就直接可以调用 requests 登陆了:
dict = {}
for item in cookie:
itm = item.split("=")
dict[itm[0]] = itm[1]
import json
file = open("cookie.json","w")
file.write(json.dumps(dict))
file.close()
最后记得关闭浏览器 browser.quit()