前言
- 你有没有想过,当我们在某个网站上登陆时,网站是如何通过验证的,我们都提交给了网站哪些信息,浏览器都发起了哪些请求?
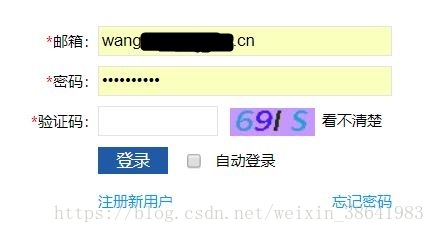
下图是某个网站的登陆界面,接下来就让我们通过命令行模拟浏览器实现登陆操作,看看一个简单的登陆操作,具体是如何实现的。
首先,我们先来明确登陆该网站的所有步骤:
载入需要的工具包
import requests
import time
from io import BytesIO
from PIL import Image
import re
from lxml import etree初始化信息
- 这里我们定义了发起http请求需要用的请求头、cookie、发起验证需要用到的表单数据、以及需要请求的URL。你也可以不使用请求头,但这样会使我们发出去的请求带有明显的
python-requests字样,使服务器一眼就能识别我们是爬虫程序。为了更加完美的模拟浏览器,我们不妨多写几行代码。 - 当然,考虑到隐私方面的问题,有些数据已经被我隐去了。
# http请求头
header = {
"accept":"*/*",
"accept-encoding":"gzip, deflate",
"accept-language":"zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"cache-control":"no-cache",
"connection":"keep-alive",
"host":"dxxxxxxxxxx.cn",
"pragma":"no-cache",
"referer":"http://xxxxxxxxxx.cn/login.htm",
"user-agent":"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0"
}
# 登陆时需要提交的验证信息
data = {
"username":"wangxxxxxxxxxx.cn",
"keyp":"xxxxxxxxxxxxxxxxxxxxxxxxx",
"submitBtn":"登录"
}
# 初始化cookie信息
cookie = requests.cookies.RequestsCookieJar()
cookie.set("u", "5", domain="xxxxxxxxxx.cn", path="/")
# 网络地址
capt_url = "http://xxxxxxxxxx.cn/servlet/ImageServlet"
login_url = "http://xxxxxxxxxx.cn/login.htm?m=login"
subsite_url = "http://xxxxxxxxxx.cn/favorite.htm"
logout_url = "http://xxxxxxxxxx.cn/login.htm?m=cancel"建立一个http会话
- 首先,我们需要建立一个http请求的会话session,使我们请求验证码的请求和提交登陆信息的请求处于同一个session中,否则即使获得了验证码也无法通过验证。
- 这里我们直接将初始cookie信息传递给会话session,在http会话的过程中,该session会自动的通过
HTTP header更新cookie信息,所以之后就不需要我们手动更新cookie了。
s = requests.Session()
s.headers = header
s.cookies = cookie获取验证码
- 该网站在获取验证码的时候,需要我们提供一个Java
long类型的时间戳。当然我们也可以在python中直接调用Java的currentTimeMillis方法,不过这里我们就直接用python的time函数做了一下简单的处理。
d = int(time.time() * 1000)
capt_raw = s.get(capt_url, params = {"d":d})查看验证码
这里我们从网站获取的
capt_raw响应对象是以raw的数据形式存储的,而且存储的是整张图片的信息,而不是二进制的图像像素数据,所以不能直接用Image.frombytes转换为Image对象。查看Image.frombytes方法的帮助文档:Note that this function decodes pixel data only, not entire images.
If you have an entire image in a string, wrap it in a :py:class:~io.BytesIO
object, and use :py:func:~PIL.Image.opento load it.得到解决方案:先将raw数据写入IO流,再通过
Image.open方法打开。不能一行代码搞定,还是有点气的。而且Image.open方法有一个参数flag,只能传递“r”(从文件中读取),就不能换个参数,跳过读取文件这一步,直接从内存中读入数据吗?
# 将二进制的图片写入IO流
f = BytesIO()
f.write(capt_raw.content)
# 查看验证码
capt = Image.open(f)
capt.show()
# 关闭IO流
f.close()- 我们获得的验证码展示出来之后大致是下图这个样子,一眼就能识别图中的字符。这里我们需要记住验证码中的字符,接下来登陆操作的过程中会使用到。

- 当然我们也可以通过机器学习自动化识别图中的字符,对于这种难度的验证码,识别率达到98%以上还是很轻松的,这点容我之后慢慢完善。
登陆操作
- 接下来我们就要进行登陆操作了,执行以下代码,程序会停在
输入验证码:,等待我们输入刚才得到的验证码,然后将接收到的输入作为表单的一部分提交给服务器。
data["verifyCode"] = input("输入验证码:")
login_result_html = s.post(login_url, data = data, allow_redirects=True)
查看是否登陆成功
- 无论身份验证证是否成功,网站都会返回给我们一个页面
login_result_html,我们怎么知道自己是否登陆成功了呢?这里我们使用xpath语句查询返还的页面,看看自己的账户名是否在返回值列表中出现了! - 由于返还的页面比较简单,所以我这里写的xpath语句也比较随便,要让代码更加稳健,xpath应该更具有唯一性才行。不论如何,能得到我们想要的数据就好。
doc = etree.HTML(login_result_html.text)
doc.xpath("//li/a//*/text()")
登陆子网站
- 接下来我们将尝试获取子网站(只有通过登陆才能查看)的信息,怎样验证我们成功获取了子网站页面呢?
- 首先,我在子网站收藏了几份数据(如下图),名称
myCollection**都是我自己取的。

- 获取子网站,通过正则匹配看看我们收藏的数据是否都在输出列表中!当然这里也可以对收藏的数据进行进一步的操作,我这里就不详述了。
subsite_html = s.get(subsite_url)
re.compile("myCollection\\d+").findall(subsite_html.text)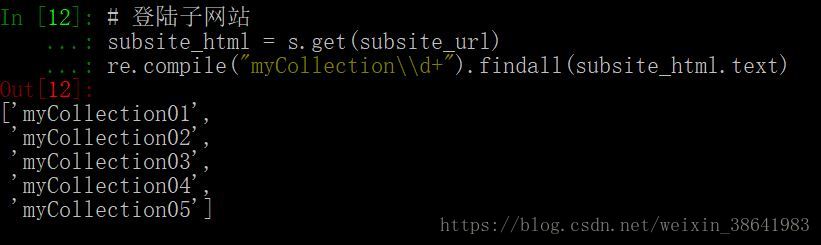
退出登陆
- 退出登录其实也很简单,只要请求一次
logout_url网址就可以了。此时我们再去请求子网站就不能获得收藏的信息了,而是被跳转到登陆页面。最后,不要忘记关闭hui’hsession。
s.get(logout_url)
s.close()结语
- 至此,我们“使用python模拟浏览器实现登陆”的任务总算结束了,登陆验证程序更加复杂的网站也是可以的,不过就是更加细腻的网络流量分析和更加精心的模拟浏览器罢了。
- 大家有好的建议或意见,欢迎留言或与我联系。
本帖仅供学习交流,请勿用于其它用途。