最近在看清华大学数据挖掘导论,图个自己复习省事,把学的东西整理在这里,也希望本菜鸡的整理对一些童鞋有帮助吧。
分类问题:
定义:给定训练集:{(x1,y1),...,(xn,yn)},生成将任何未知对象xi映射到其类标签yi的分类器(函数)。
图示:
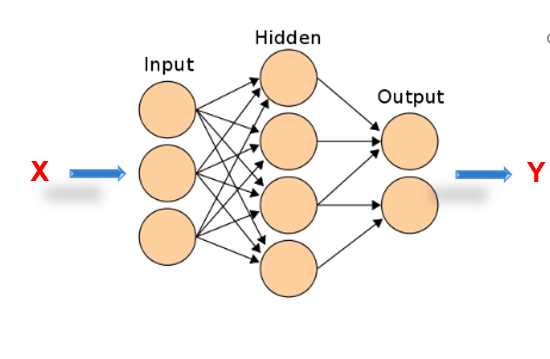
其经典算法:
- 决策树
- KNN
- 神经网络
- 支持向量机
注意:我们要的理想分类器是可以得到大部分正确的结果,并不是要达到100%,结果要求平滑。
分类问题算法中的交叉验证:

过程:
- 利用数据中的训练集进行模型的生成。
- 利用测试集进行模型的评测(evaluation)
- 将评测的结果反馈给生成模型。
- 若评测结果比较满意,进行生成模型的输出。否则重新生成。
至于如何进行评测,我们要首先了解一个名词:混淆矩阵(confusion matrix):

举一个栗子来帮助理解:
我们将性别作为y,即两分类问题中的类别,男,女。我们令男为positive,女为negative。
假若有一人性别为男,其actual value就是positive。如果我们将这个人的属性输入(属性是啥可以自己定咯)模型得到positive,则对应上图的true positive,表明预测成功,得到negative对应false negative,表明将男人预测为女人。反之,则对应其余两个格子。
当然,这一模型的准确率就可以用accuracy = ( TP+TN )/( P+N )(测试集数据结果)为此模型准确率。
下面ROC曲线:
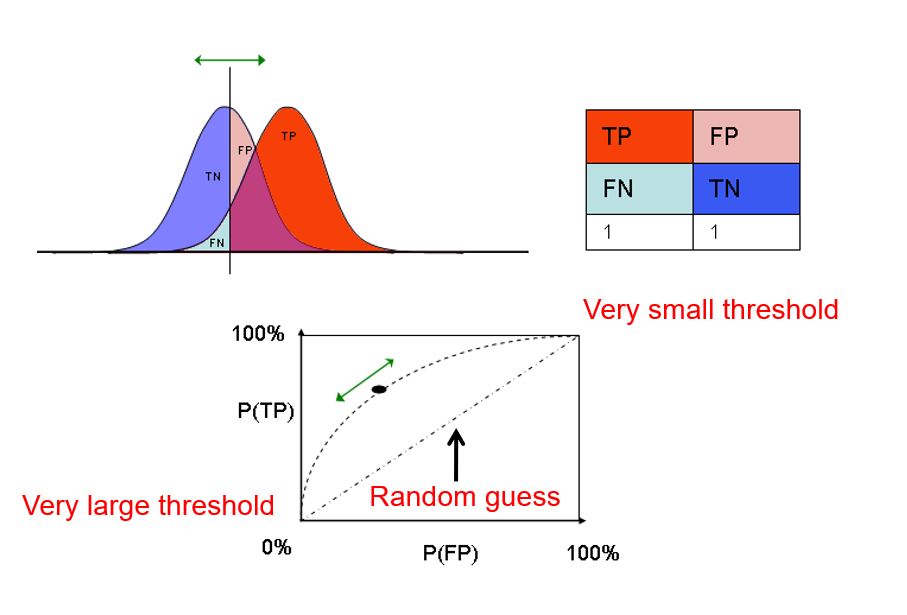
来看第一个图!
如果我们还是预测性别,利用身高属性来直接预测的话:
横坐标代表身高,两条线代表男人/女人,中间这个线啊,就是阈值。
紫色部分为TP,FP重合之处。
好,第二个!没啥说的。。。。其下面的1也是对应第一个图中线所围成的面积。
我们看第三个图:
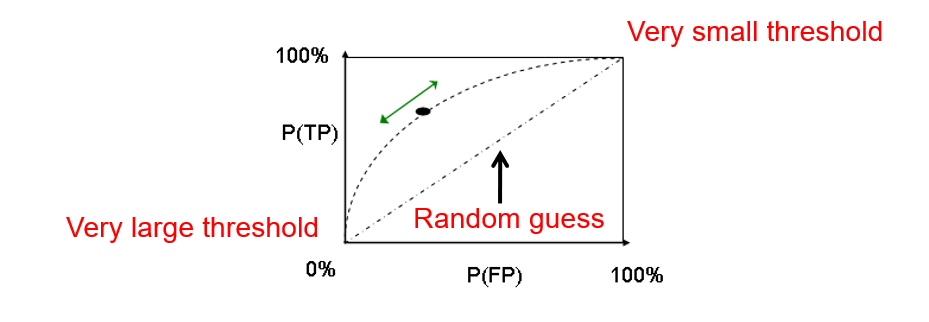
如果我们将阈值定为1m,所有预测都是男生。TP为100%,FP为100%。对应第三图右上角(very small threshold)。
如果将阈值定为5m,FP,TP都是0,对应于左下角(very large threshold)。
不同的阈值,对应着此坐标系中不同点的取值。
其中,链接两个对角的对角线为random guess,也就是来一个人,不管什么属性,随机猜,就是这个效果。
理论上,我们希望这条曲线越高越好。为了衡量这条线的好坏,定义AUC。为此线下面的面积,为测试模型好坏的一指标。越接近1,此模型越好。
本菜鸡还是初学者,有啥错误希望路过的大神指正。