二手车交易预测
实验目的与要求
- 结合问题理解,描述三种适用于本题的模型。
- 掌握数据挖掘的基本流程,包括数据分析与预处理,特征过程,模型训练与测试,实验内容文件中给出了一些可以参考的步骤,大家可以自行选择或自由发挥完成各阶段的工作。
- 最后将预测结果文件上传到比赛网站上进行测试,将结果截图,记录分数和排名。
试验环境
本次实验采用PC机进行数据分析,采用服务器进行训练模型并进行预测。
【PC机配置】
CPU:11th Gen Intel® Core™ i7-11700K @ 3.60GHz 3.60 GHz
GPU:NVIDIA GeForce RTX 3060
操作系统:Windows 10 专业版
【服务器配置】
CPU:Intel® Xeon® CPU E5-2680 v4 @ 2.40GHz
GPU:2张NVIDIA A100
操作系统:Linux
实验内容及过程
一、数据分析
1、基础数据分析:
首先引入必须的库,然后将训练集数据和测试集数据合并,以便后面的操作。
查看前几行数据:

通过分析,以及查阅资料,可知数据中共包含31个字段,其中包含15个匿名变量,其余变量展示如下:
| 字段名 | 意义 |
|---|---|
| SaleID | 交易ID,唯一编码 |
| name | 汽车交易名称,已脱敏 |
| regDate | 汽车注册日期,例如20160101,2016年01月01日 |
| model | 车型编码,已脱敏 |
| brand | 汽车品牌,已脱敏 |
| bodyType | 车身类型:豪华轿车:0,微型车:1,厢型车:2,大巴车:3,敞篷车:4,双门汽车:5,商务车:6,搅拌车:7 |
| fuelType | 燃油类型:汽油:0,柴油:1,液化石油气:2,天然气:3,混合动力:4,其他:5,电动:6 |
| gearbox | 变速箱:手动:0,自动:1 |
| power | 发动机功率:范围 [ 0, 600 ] |
| kilometer | 汽车已行驶公里,单位万km |
| notRepairedDamage | 汽车有尚未修复的损坏:是:0,否:1 |
| regionCode | 地区编码,已脱敏 |
| seller | 销售方:个体:0,非个体:1 |
| offerType | 报价类型:提供:0,请求:1 |
| creatDate | 汽车上线时间,即开始售卖时间 |
| price | 二手车交易价格(预测目标) |
首先大致观察数据:
使用describe总览数据情况
通过info()来熟悉数据类型
发现除了“notRepairedDamage”之外其他都是数值特征,说明后续需要对这个特征进行数值化处理。
2、特征相关性分析:
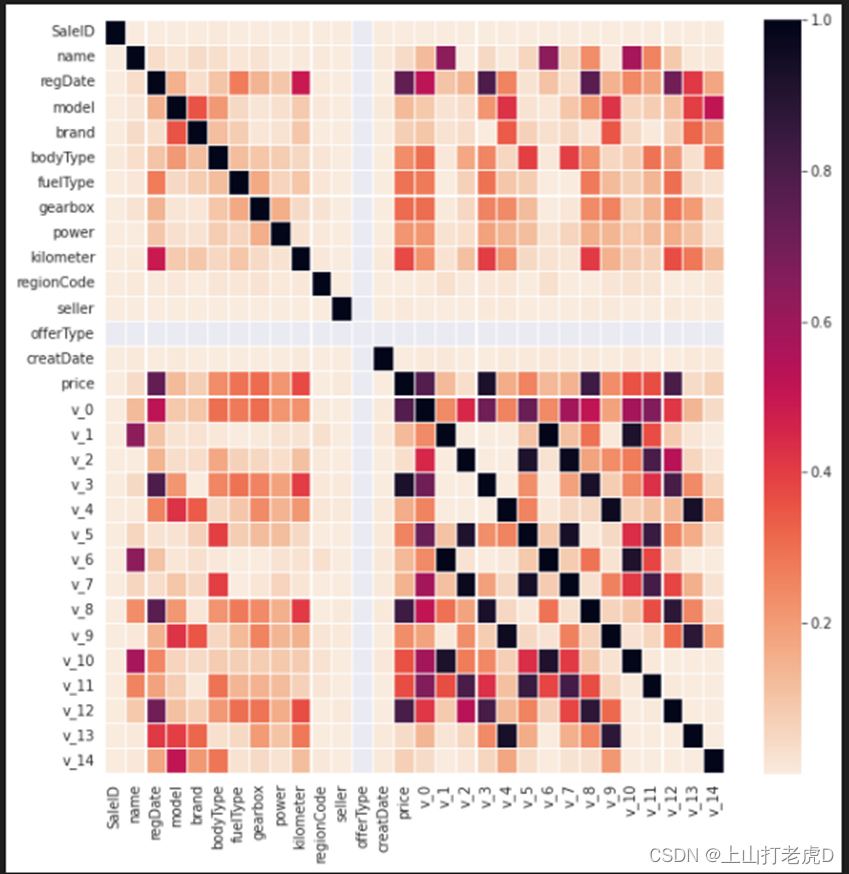
绘制特征相关度的热度图。发现与价格相关度比较高的特征有regDate,匿名特征v_0、v_3、v_8、v_12,则在特征工程中需要重点对这些属性进行处理。
3、特征值重复度分析:
统计每个特征中不重复的值的数目。对于重复度很高的特征,后续缺失值可以考虑使用众数填充的方法来处理。
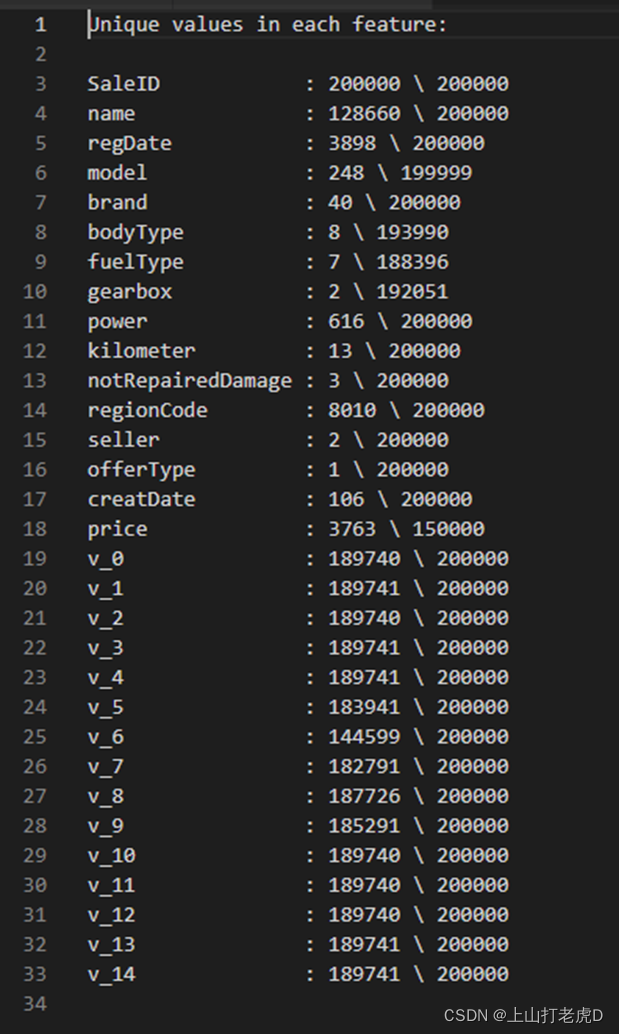
4、缺失值统计分析:
接下来,对数据缺失以及异常情况进行统计:
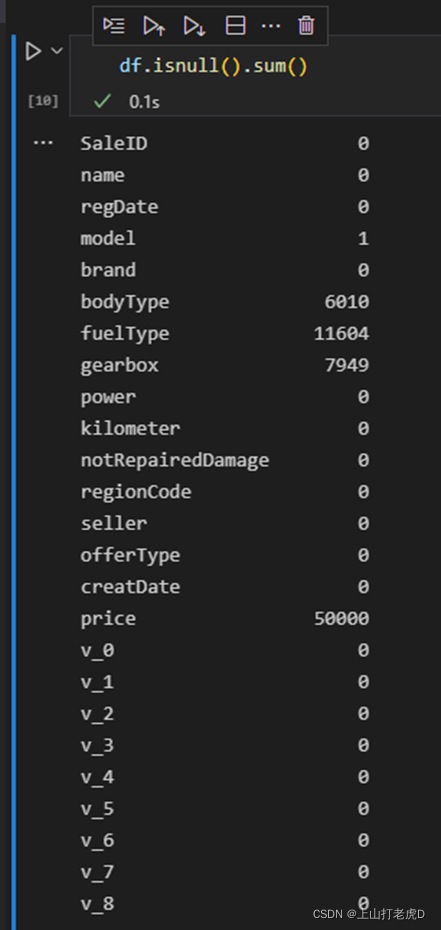
可以发现bodyType,fuelType,gearbox三个字段缺失较多。
进行数据可视化
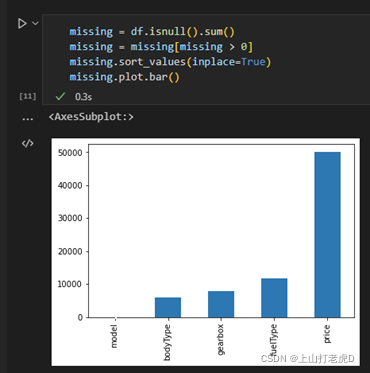
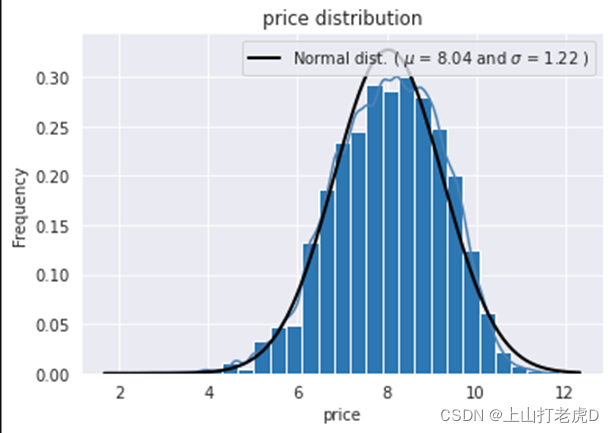
5、价格分布分析:
绘制价格的直方图、密度图,可以得出,价格大致呈长尾分布,说明后续需要将数据进行正态化的处理。
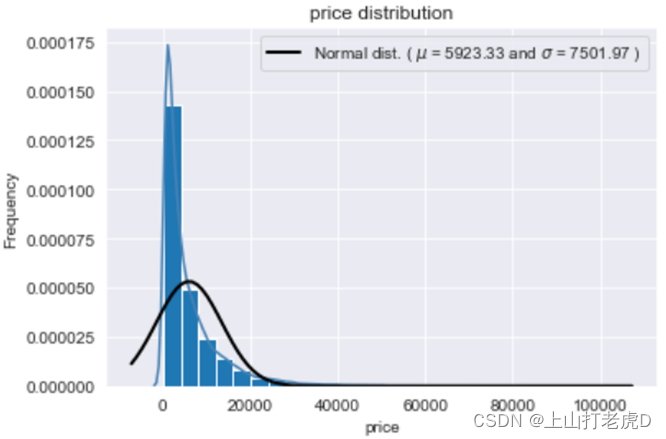
正态化后:
二、数据预处理
1、缺失值处理:
通过上面数据重复度的统计,发现有缺失值的特征大多数值重复度都比较高,故使用众数填充的方法补充缺失值。

2、数值化非数值特征
非数值特征只有“notRepairedDamage”,它有‘-’,‘0.0’,‘1.0’三种值。将值‘-’用‘0.0’来代替,并把特征值转为浮点数类型。

3、异常值处理
功率特征power的范围在1 ~ 600之间,因此将超出范围的值截断在正常范围内。

发现匿名特征v_13、v_14的特征值集中分布在一定范围内,因此将超出范围的少数异常点进行截断。

三、特征工程
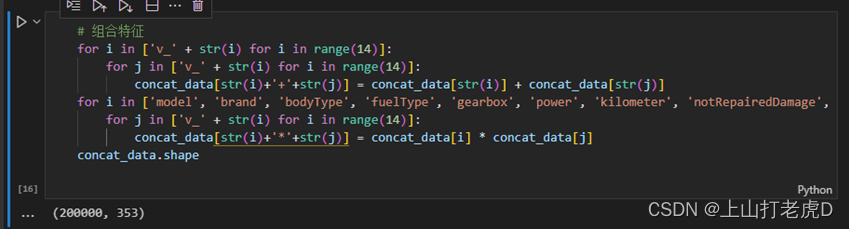
1、组合匿名特征:
一些匿名特征与价格的相关度比较高,说明匿名特征很重要。通过匿名特征之间的组合、匿名特征与其他特征的组合构造新特征,方便后续使用分析。
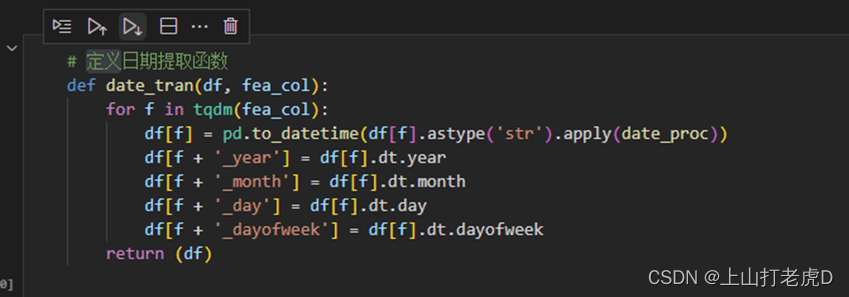
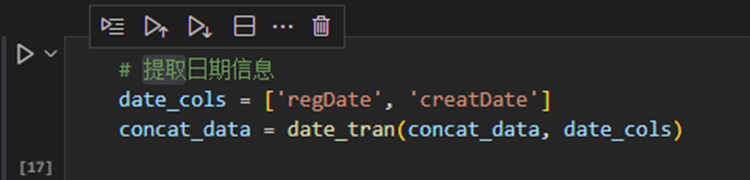
2、提取日期信息
日期信息有“regDate”、“creatDate”两个特征,通过定义日期解析函数date_tran(),将日期拆分为年、月、日。
3、特征的count编码
统计一些特征的值的数量,将特征与其值的数目构成新的特征。定义函数count_coding()统计特征值的数目。


4、日期的特征构造
基于注册日期和创建日期两个特征,构造更有意义的特征,如汽车的使用时长、注册日期与现在日期的天数、创建日期与现在日期的天数。由于得到的这些天数是离散值,需要对它们进行分桶处理。定义函数cut_group()进行分桶。

5、特征交叉
用数值特征对类别特征做统计刻画,这里选择了与价格相关度最高的几个匿名特征。定义函数cross_cat_num()进行一阶交叉。
6、特征编码
由于存在汽车名称、汽车品牌、区域编码等类别特征,而这些特征都是高基数定性的特征,因此需要对这些类别特征进行编码。常见的方法使用独热编码和标签编码的方法,但这两种方法过于简单,不易产生好的效果,而且容易消耗大量内存和训练时间,所以这里我使用了更加适合高基数定性特征的两种编码方式:平均数编码和目标编码。
①平均数编码
定义平均数编码的类,声明需要编码的特征,调用函数对训练集的特征和标签进行拟合,最后对测试集进行编码即可。
②目标编码
首先给出每种编码的默认值。这里选择了最大值、最小值、平均值这三种编码。通过与类别特征的组合进行目标编码。
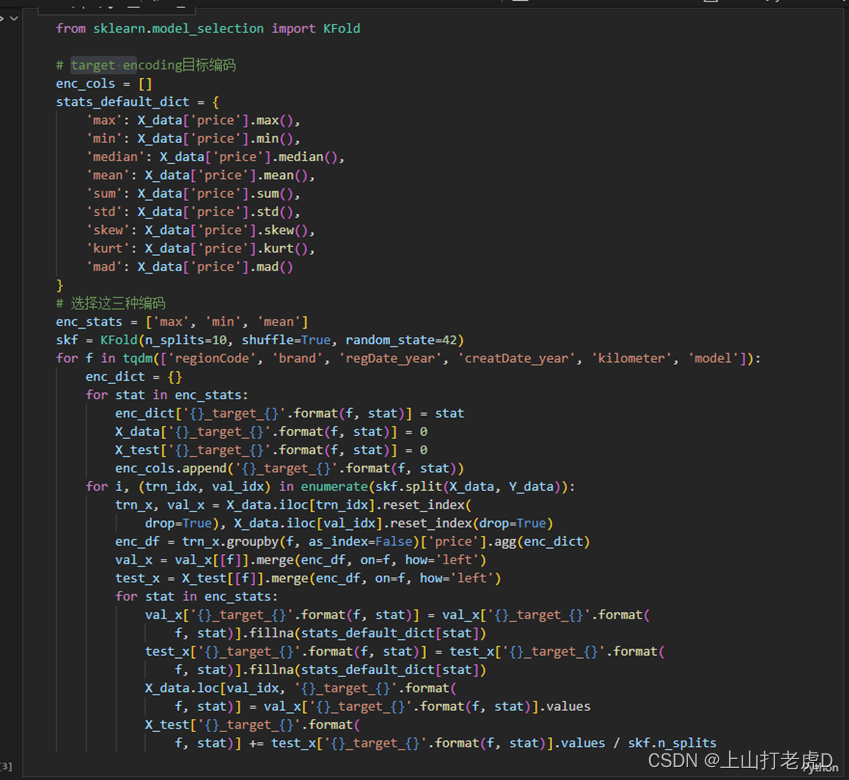
③特征归一化
合并训练集和测试集,使用MinMaxScaler对数据进行归一化。

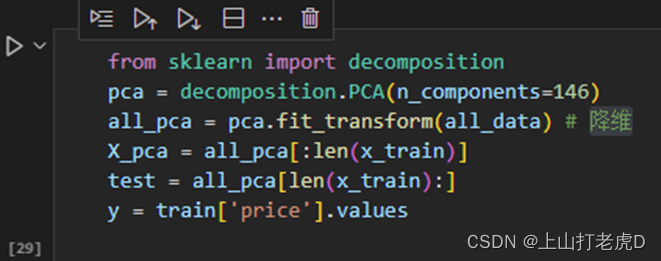
④特征降维
使用PCA对特征进行降维处理,最后将处理完的数据分配回给训练集和测试集。
四、预测模型
1、问题分析
本问题属于对二手车的交易价格的预测,属于典型的有监督回归问题,可以使用回归模型、集成方法等多种算法进行处理。
2、可用模型
针对本问题,可以使用lightgbm、catboost、neural network等模型进行训练预测。lightgbm和catboost都属于树模型,它们的优点是训练收敛速度很快,可以在训练过程中调整正则化系数和学习率,缺点是占用内存空间大、耗时比较长。本次实验我采用了neural network的方法进行训练预测,神经网络不仅在训练时可以使用小规模的数据,而且它的收敛速度的收益大,精度与树模型接近。另外加上Adam优化器等优化方案,可以降低内存消耗,提升计算效率,可以很好地处理特征。
3、训练模型与预测
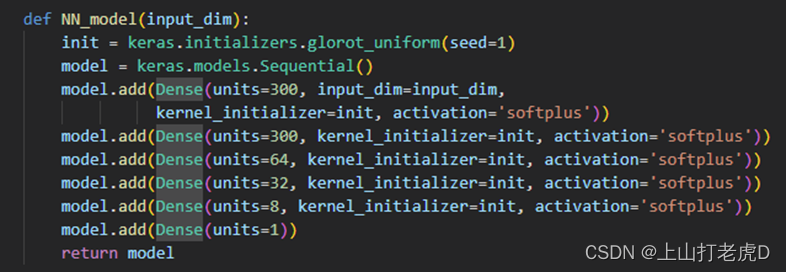
①定义神经网络模型构造函数,这里我使用了六层神经网络结构
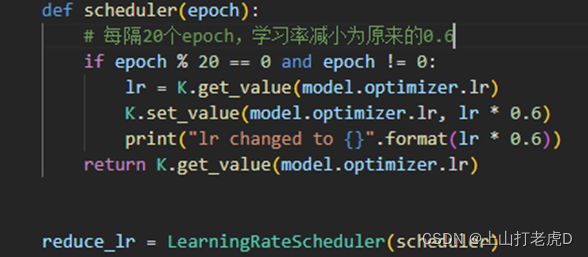
②定义学习率调整函数,每隔100个epoch,学习率减小为原来的1/10
③开始训练和预测。训练过程中使用正则化防止过拟合。同时对训练过程的误差进行分析,选择学习率下降的时机对学习率进行调整。另外使用六折交叉验证,减小过拟合。这里我还使用了Adam对梯度下降进行优化。并将loss比较小的保存为提交文件
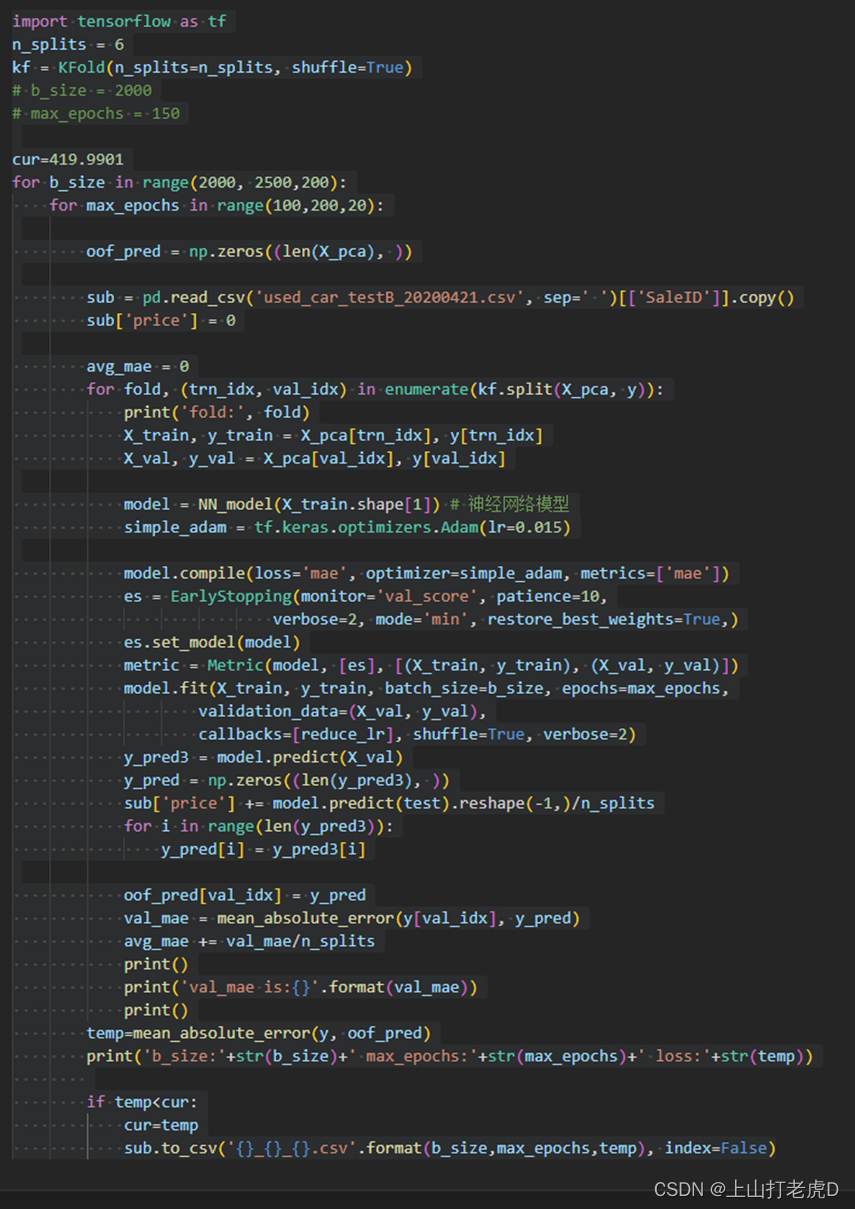
五、调参并测试
本次预测的模型中含有epoch,batch,learnRate,以及网络层数等参数,为了获取更好的结果,我查阅资料,进行了多次调参。由于提交次数有限,我选择本地测试后loss比较小的几组进行提交,进行调优上分。
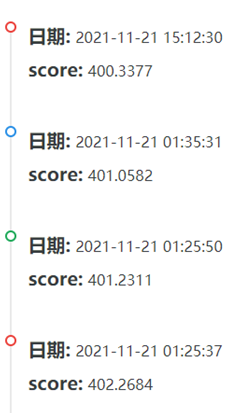
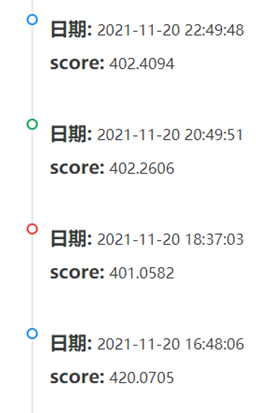
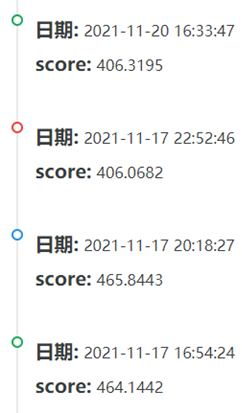
六、最终提交结果:
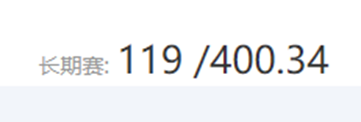
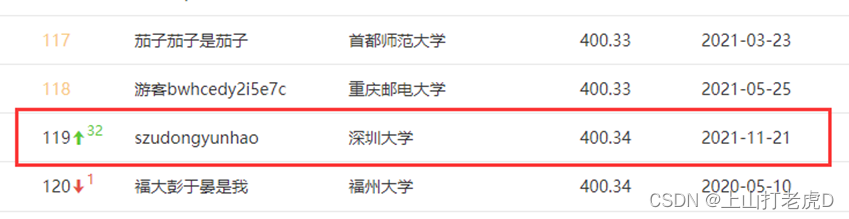
经过一系列的调整,发现当batch为2000,epoch为145,采用大小分别为300,64,32,8,1的五层神经网络模型时上分效果最好。从比赛网站中提交最后的预测结果,最终我的分数为400.3377分,排名为119名。

实验收获
本次实验中,我参加了阿里天池举办的《二手车价格预测比赛》,我学会了通过查阅资料与书籍,独立的进行数学分析,数据清洗并选择合适的模型进行预测。这使我对数据挖掘有了比较全面的认识,在此,我掌握了几种常见的数据分析,数据清洗的方法,学会,理解并实战了常用的预测模型。
此外,对于本次实验中所用的参数(学习率,batch,epcho等)没有一个比较合理的概念,我手动调参,并选择结果比较好的进行多次提交刷榜,最后取得了不错的成绩。