1.1、理解MapReduce思想
MapReduce思想在生活中处处可见。或多或少都曾接触过这种思想。MapReduce的思想核心是“分而治之”,适用于大量复杂的任务处理场景(大规模数据处理场景)。即使是发布过论文实现分布式计算的谷歌也只是实现了这种思想,而不是自己原创。
Map负责“分”,即把复杂的任务分解为若干个“简单的任务”来并行处理。可以进行拆分的前提是这些小任务可以并行计算,彼此间几乎没有依赖关系。
Reduce负责“合”,即对map阶段的结果进行全局汇总。
这两个阶段合起来正是MapReduce思想的体现。
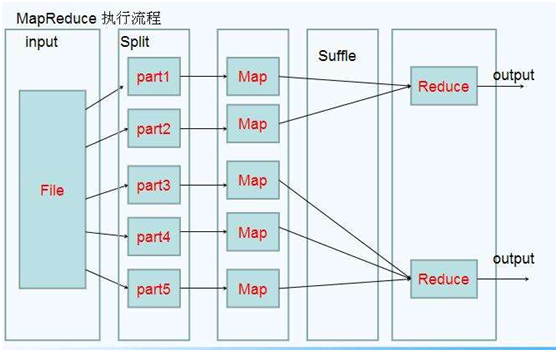
1.2、Hadoop MapReduce设计构思
1.如何对付大数据处理:分而治之
2. 构建抽象模型:Map和Reduce
map: (k1; v1) → [(k2; v2)]
reduce: (k2; [v2]) → [(k3; v3)]
3.统一构架,隐藏系统层细节
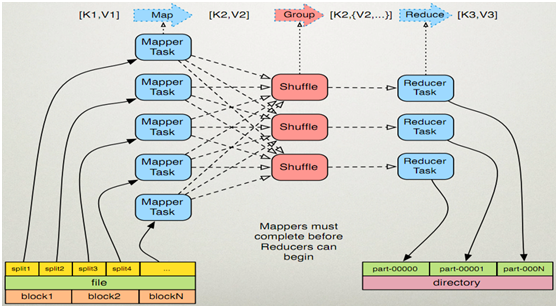
1.3、MapReduce框架结构


1.4、MapReduce编程规范及示例编写
mapReduce编程模型的总结:
MapReduce的开发一共有八个步骤其中map阶段分为2个步骤,shuffle阶段4个步骤,reduce阶段分为2个步骤
Map阶段2个步骤
第一步:设置inputFormat类,将我们的数据切分成key,value对 (k1,v1),输入到第二步
第二步:自定义map逻辑,处理我们第一步的输入数据,然后转换成新的key,value对进行输出 (k2,v2)
shuffle阶段4个步骤(可以全部不用管)
第三步:对输出的key,value对 (k2,v2) 进行分区
第四步:对不同分区的数据按照相同的key进行字典顺序的排序
第五步:对分组后的数据进行规约(combine操作),降低数据的网络拷贝(可选步骤)(减少输出的k2的数据量)
第六步:对排序后的额数据进行分组,分组的过程中,将相同key的value放到一个集合当中(调用一次reduce逻辑)
reduce阶段2个步骤
第七步:对多个map的任务进行合并,排序,写reduce函数自己的逻辑,对输入的key,value对进行处理,转换成新的key,value对 (k3,v3) 进行输出
第八步:设置outputformat将输出的key,value对 (k3,v3) 数据进行保存到文件中
八个步骤背下来!
每一个步骤都是一个class类,将八个步骤的class类组织到一起就是我们的mapreduce的程序。