MapReduce原理
分而治之,将一个大的任务拆分成很多小的子任务(map),并行执行后,合并结果(reduce)。
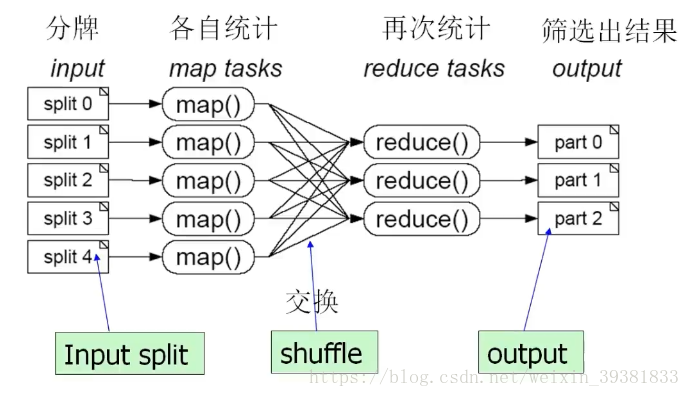
MapReduce 运行流程
1 Job&Task
一个job会被拆分成多个Task
Task又分为
- MapTask
- ReduceTask
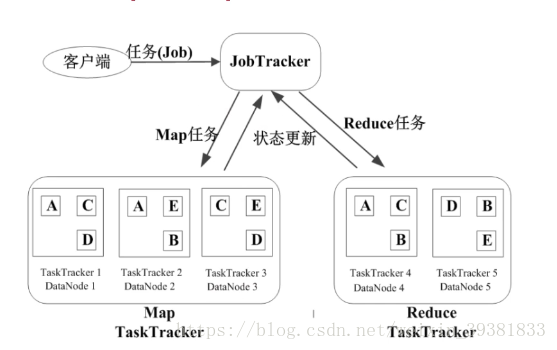
JobTracker的角色
- 作业调度
- 分配任务、监控任务执行进度
- 监控TaskTracker的状态
TaskTracker的角色
- 执行任务
- 汇报任务状态
Hadoop2.0以后的版本移除了原有的JobTracker和TaskTracker,改由Yarn平台的ResourceManager负责集群中的所有资源的同意管理和分配,NodeMangager管理Hadoop集群中单个计算节点
优点;
- 减少了JobTracker的资源小号,减少了1.0中发生单点故障的风险。
- 在YARN平台上还可以运行Spark和Storm作业,充分利用资源
MapReduce作业执行过程
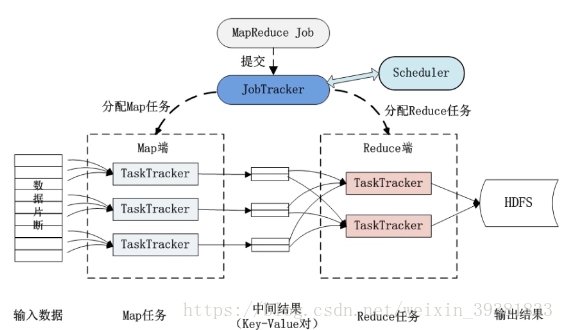
MapReduce的容错机制
1 重复执行
最大重复执行4次,还是失败,则放弃执行
2推测执行
TaskTracker执行同一个任务时,其中有一个节点过慢
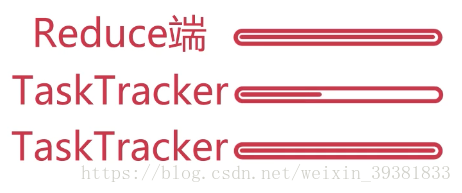
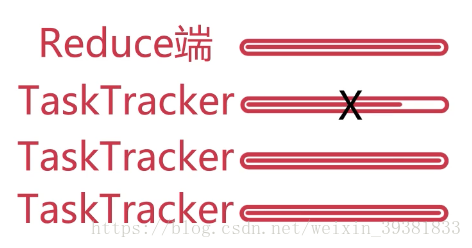
算的慢的继续算,再找一个TaskTracker算这个任务,谁先算完用那个,慢的停止
MapReduce的四个阶段
1 Splitf阶段:分片输入阶段
2 Map阶段(需要编码)
3 Shuffle阶段
Reduce阶段(需要编码)
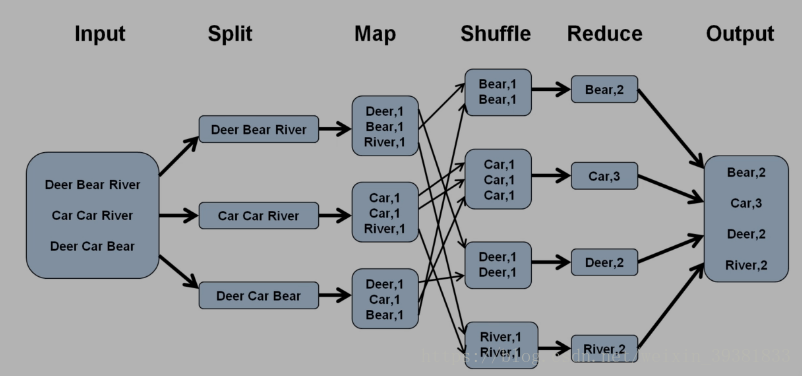
实例
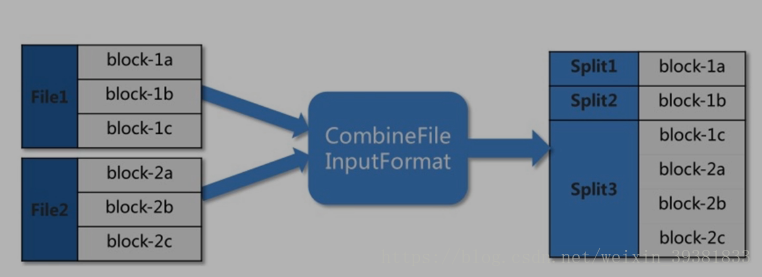
1 split阶段
file1 和 file2经过分片处理后生成Split123作为Map的输入
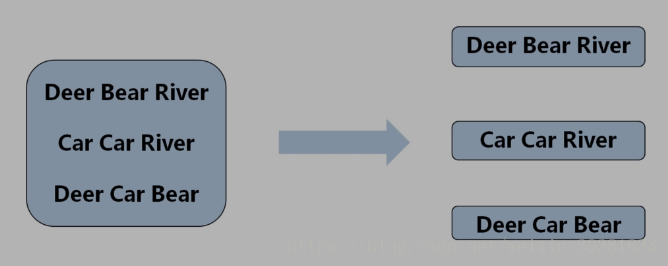
三行文本 拆分成三份
2 Map阶段
输入为<key value>
value为单词出现的次数
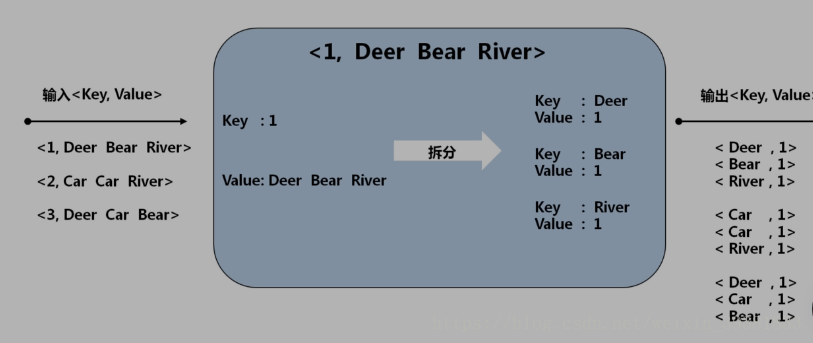
3 Shuffle阶段
接收Map阶段的<key value>作为输入
Shuffle阶段可以理解为Map输出到Reduce输入的过程
设计网络传输
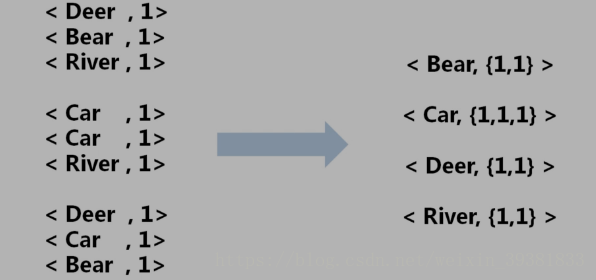
虽然有次数的累计,但是不会算出总数,只是将相同的放在一起
4 Reduce阶段
输入为<key value>

总结