环境:namenode(主机名hdp01) 1台 datanode (主机名hdp02 hdp03)2台
已搭建集群分布
启动 YARN,输入 jps 查看是否启动 NodeManager
三台机器都要启动,网页访问 hdp01:8080查看管理页面
搭建好集群服务,并且启动 YARN 服务。
MapReduce 代码分为三部分
第一部分:Map
第二部分:Reduce
第三部分:Job 提交器
首先在 hdfs 文件目录中创建/wordcount/input/和/wordcount/output/(output 不用创建)
将统计的单词文件放在/wordcount/input/里面
第一部分 Map 代码的书写
package Map;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* Created by hubo on 2017/12/2
*
* KEYIN,VALUEIN,KEYOUT,VALUEOUT
*
* KEYIN:读到一行数据的起始偏移量,Long
* VALUEIN:框架读到的一行数据的内容,String
*
* KEYOUT:要输出的 key 类型,此例中是单词,String 值
* VALUEOUT:输出的 value 类型, 此例中是整数,Int 值
*/
public class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>{
//重写父类中的 map 方法
//key 框架传给的参数的 KEYIN
//value 框架传给我们的参数 VALUEIN
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//将拿到的数据按空格切分
String[] words = value.toString().split(" ");
for(String word : words){
context.write(new Text(word),new LongWritable(1L));
}
}
}第二部分 Reduce 代码书写
package Map;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Created by hubo on 2017/12/2
* KEYIN,VALUEIN,KEYOUT,VALUEOUT
*
* KEYIN:对应 map 阶段输出的 key 的类型,Text
* VALUEIN:对应 map 阶段的 value 类型,LongWritable
*/
public class MyReduce extends Reducer<Text,LongWritable,Text,LongWritable>{
//一组相同 key 的数据调用一次 Reduce
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context)
throws IOException, InterruptedException {
//累计这一次 kv 数据的 values 值即可
Long count = 0L;
for(LongWritable value : values){
count += value.get();
}
//输出放到 context 中就可以
context.write(key,new LongWritable(count));
}
}
第三部分:Job 提交器
package Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.junit.Test;
import java.io.IOException;
/**
* Created by hubo on 2017/12/2
*
* job 提交器就是 YARN 集群的客户端,他负责将 mr (程序需要的信息)封装一个配置文件,
* 然后连同 mr 程序的 jar 包,一起提交给 yarn,由 yarn 去启动我们的 mr 程序中的 Mrappnaster
*
*/
public class JobClient {
public static void main(String[] args)
throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
conf.set("yarn.resourcemanager.hostname","hdp01");
//创建一个 job 提交器对象
Job job = Job.getInstance(conf);
//job.setJar("/root/wordcount.jar");
//告知客户端提交器 mr 程序所在的 jar 包
job.setJarByClass(JobClient.class);
//告知 mrappmaster,程序中的 map 和 reduce 实现类
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReduce.class);
//告知 mrappmaster ,程序中 map 阶段和 reduce 阶段的数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//告知mrappmaster要求要启动的 reduce task 数量是多少
job.setNumReduceTasks(2);
//告知mrappmaster,我们数据的输入和输出目录
org.apache.hadoop.mapreduce.lib.input.FileInputFormat.setInputPaths(job,new Path("hdfs://hdp01:9000/wordcount/input/"));
org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.setOutputPath(job,new Path("hdfs://hdp01:9000/wordcount/output/"));
//提交 job
//不要用 submit ,程序运行完之后就结束。
//waitForCompletion,等待程序运行完
boolean res = job.waitForCompletion( true);
System.exit((res?0:1)); //以后用脚本判断执行结果
}
}将上面的源码打包成 jar 文件。
上传到客户端服务器或者 datanode 和 namenode 上面都行(但是客户端要和集群中的配置相同,不然没法传文件)
我直接将 jar 上传到 namenode 上面
我的 jar 文件名字(MapReduce.jar)
输入命令 hadoop jar MapReduce.jar Map.JobClient 启动
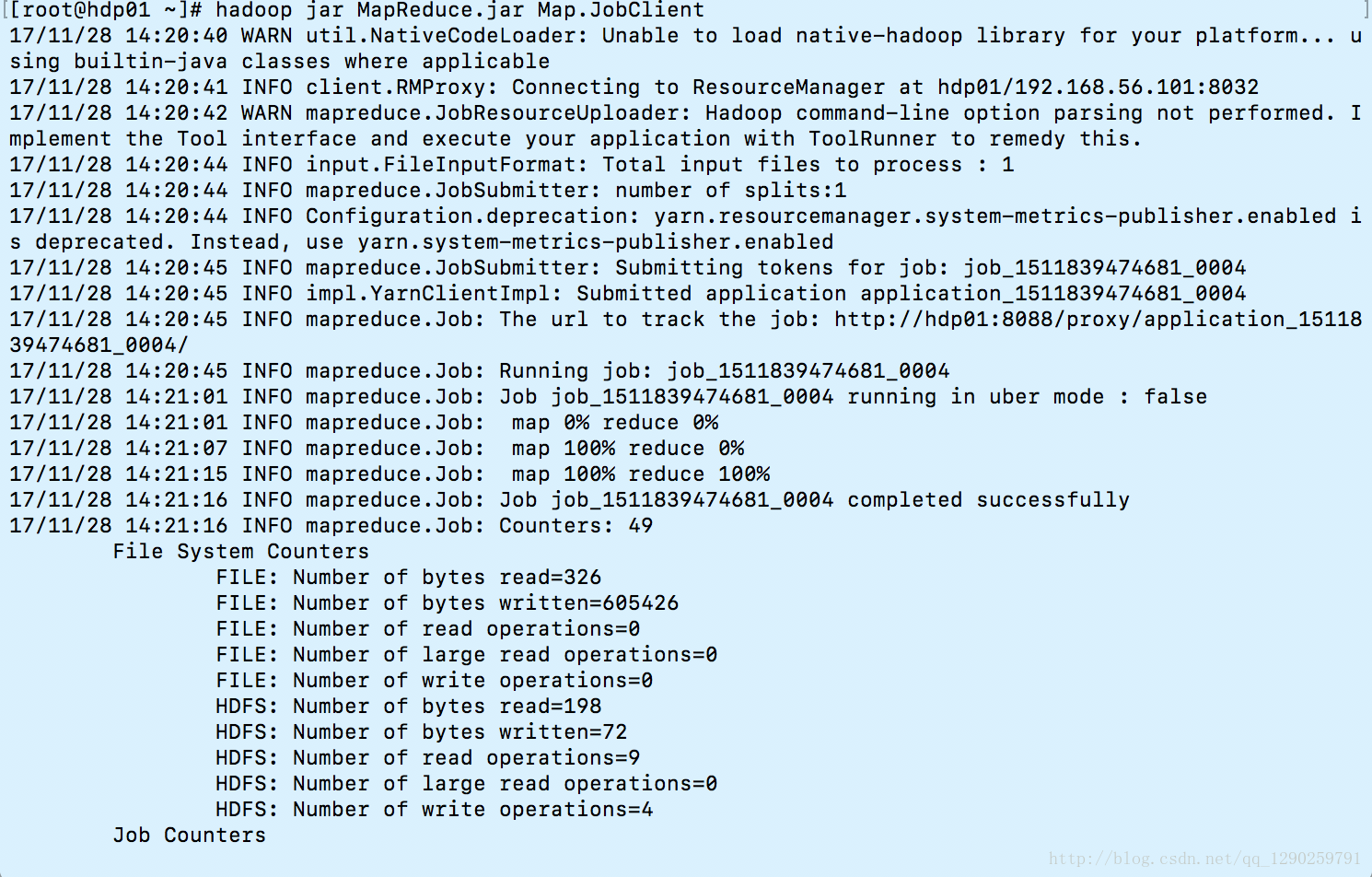
可以看到先启动 map 完成后 reduce
其实 map 没有完成的时候 reduce 已经开始启动了(但是一定要 map 完成 reduce 才会结束)
可以看到 output 目录下由两个文件(因为启动了两个 Reduce )

可以查看内容

报错因为使用的 java 包,我没编辑 64位hadoop 的包,没什么影响。
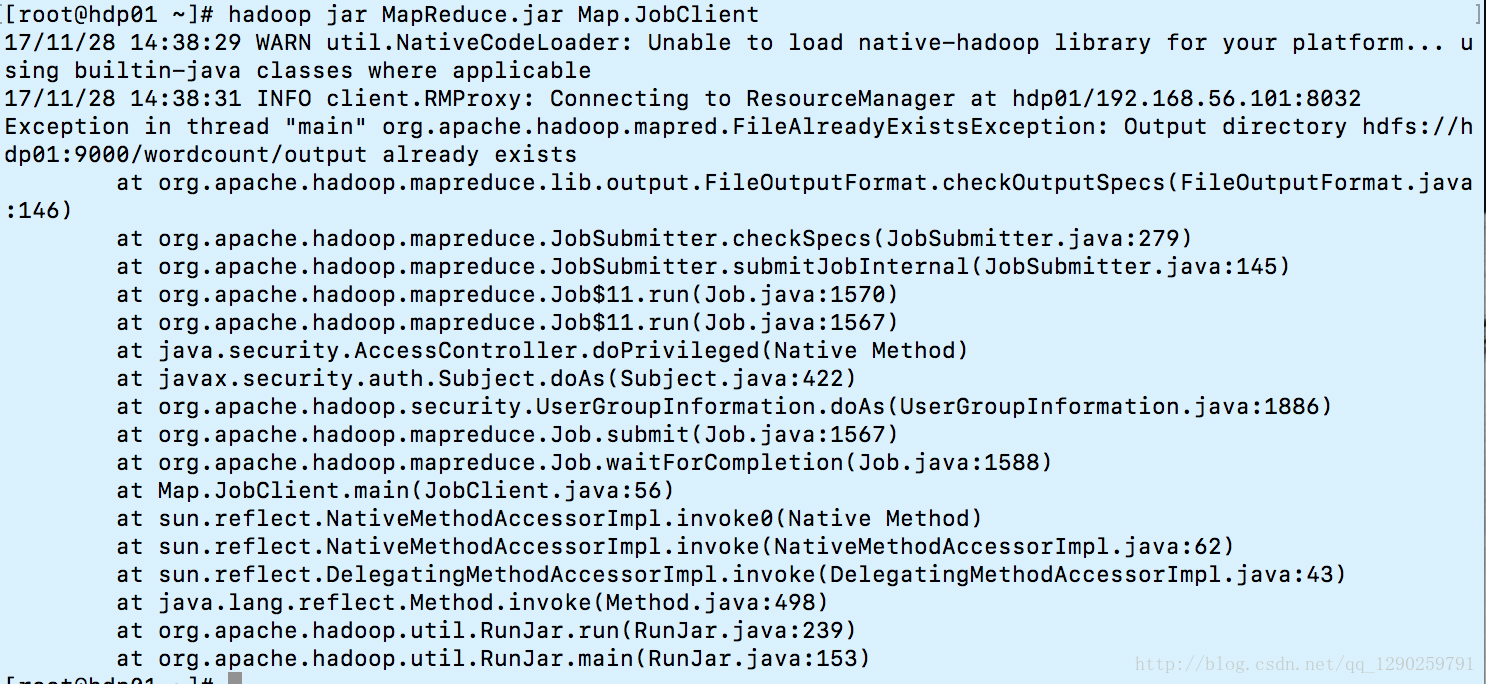
说一下遇到的问题:
Exception in thread “main” org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory
因为之前生成文件夹了,将 output 目录删除就可以了
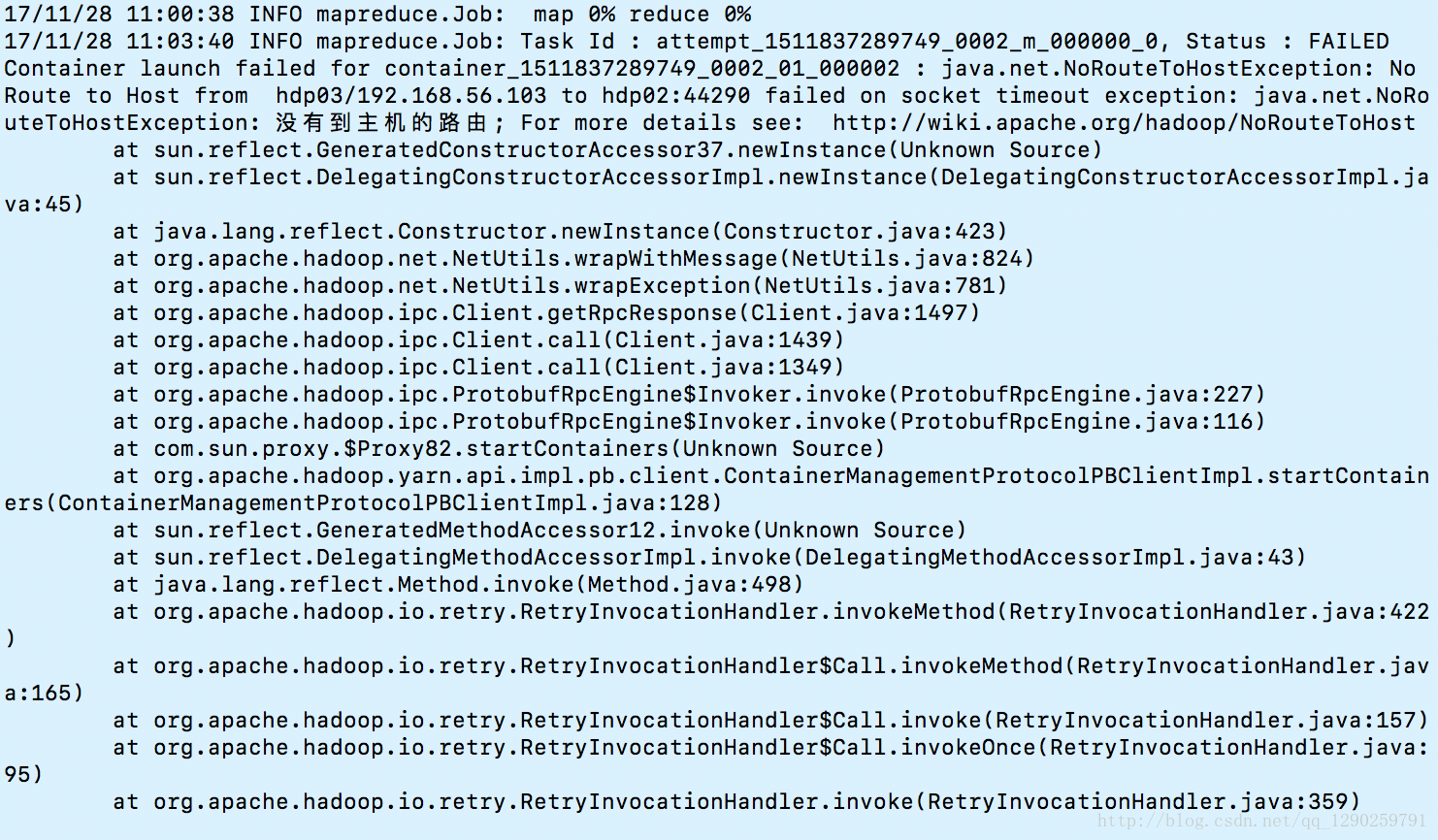
failed on socket timeout exception: java.net.NoRouteToHostException: 没有到主机的路由; For more details see
这个问题就很坑了,之前明明记得所有的防火墙都关闭了,一个这个问题纠结了一晚上,才发现防火墙没有关闭。
关闭防火墙
跳板机可以从外网到内网,只能开防火墙的端口
查看防火墙状态 service iptables status
关闭 service iptables stop 但是开机还是会启动的
设置防火墙开机不启动
chkconfig iptables --list
chkconfig iptables off 防火墙不回开机启动
只要程序没写错,jar 打包没问题,应该可以正常运行了。
有可能还有一些问题,自己解决了没写上去,有朋友遇到解决不了的可以留言。