一、MapReduce 概述
1.1 MapReduce定义
MapReduce 是一个分布式运算程序中的编程框架, 是用户开发“基于 Hadoop 的数据分析应用”的核心框架.
MapReduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式0运算程序,并发运行在一个 Hadoop 集群上。
1.2 MapReduce 优缺点
优点
- 易于编程
它简单的实现一些借口,就可以完成一个分布式程序,这个分布式程序可以分不到大量廉价的 PC 机器上运行。也就是说你写一个分布式程序吗,跟写 一个简单的串行程序是一样的,就是因为这个特点使用 MapReduce 编程很流行。
- 良好的扩展性
当你的计算资源不能满足的时候,可以通过简单的增加机器来扩展它的计算能力。
- 高容错性
MapReduce 设计的初衷就是使程序能够部署在廉价的 PC 机器上,这就要求它具有很高的容错性。比如一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工的参与,而完全是由 Hadoop 内部完成的。
- 适合PB级以上海量数据的离线处理
可以实现千台服务器集群开发工作,提供数据处理能力。
二、WordCount 案例
2.1 hello.txt
hello world
hello OK
are you ok
I am ok
hello OK2.2 代码实现
package com.kangna.mapreducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/********************************
* @Author: kangna
* @Date: 2020/1/25 11:14
* @Version: 1.0
* @Desc:
********************************/
public class WordCountMain {
public static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private Text word = new Text();
private IntWritable one = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 取到一行个数据
String line = value.toString();
// 按照空格切分
String[] words = line.split(" ");
// 遍历数据
for (String word : words) {
this.word.set(word);
context.write(this.word, this.one);
}
}
}
public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable > {
private IntWritable total = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// 作累加
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
// 包装 结构并输出
total.set(sum);
context.write(key, total);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1. 获取一个 Job 实例
Job job = Job.getInstance(new Configuration());
// 2. 设置 类的路径
job.setJarByClass(WordCountMain.class);
// 3. 设置 Mapper 和 Reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 4. 设置 Mapper 和 Reducer 的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 5. 设置输入输出数据
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 6. 提交Job
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
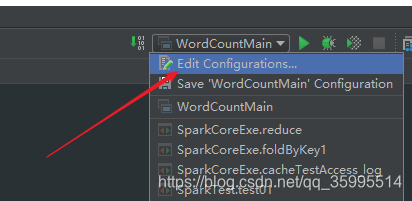
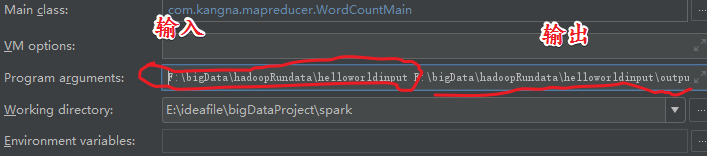
参数的设定
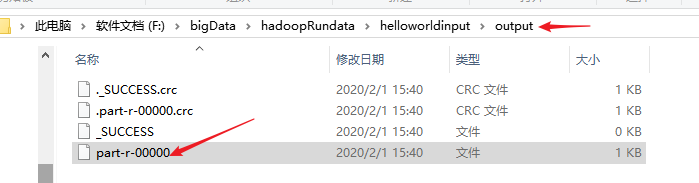
查看输出的文件结果

打包在集群中也是可以运行的。
