关系型数据库主要考点
考点思维导图

一、索引模块
1、常见问题
- 为什么要使用索引
- 什么样的信息能够成为索引
- 索引的数据结构
- 密集索引和稀疏索引的区别
为什么要使用索引
索引是一个排序的列表,在这个列表中存储着索引的值和包含这个值得数据所在的行的物理地址,在数据十分庞大的时候,索引可以大大加速查询的速度,这是因为使用索引后可以不用扫描全表来定位某行的数据,而是先通过索引表找到该行数据对应的物理地址然后访问相应的数据。
什么样的信息能够成为索引
- 主键、唯一键以及普通键等
索引的数据结构
- 生成索引,建立二叉查找树进行二分查找
- 生成索引,建立B-Tree结构进行查找
- 生成索引,建立B+-Tree结构进行查找
- 生成索引,建立Hash结构进行查找
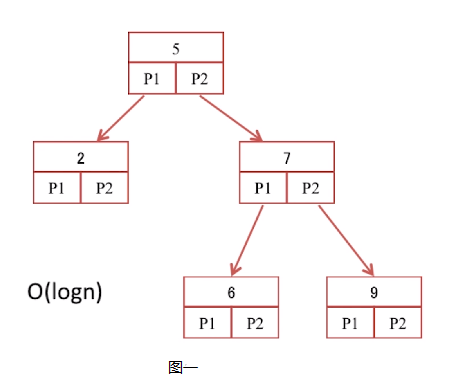
二叉查找树
二叉查找树是每个节点最多有两个子节点的树结构,通常子树被称为左子树和右子树,左子树的值均小于它的父节点,右子树大于它的父节点。
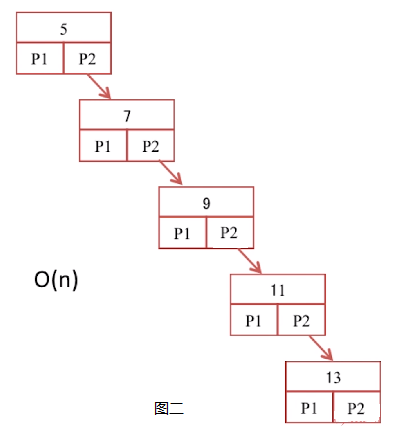
图一是一个平衡二叉树——其左子树和右子树的高度相差不超过1,其时间复杂度是O(logn)。当出现节点的删除和新增的时候,例如删除节点2和节点6,同时新增节点11和节点13,其树行结构会变成图二,时间复杂度会变成O(n)其性能大大的降低,这也是二叉树的缺点
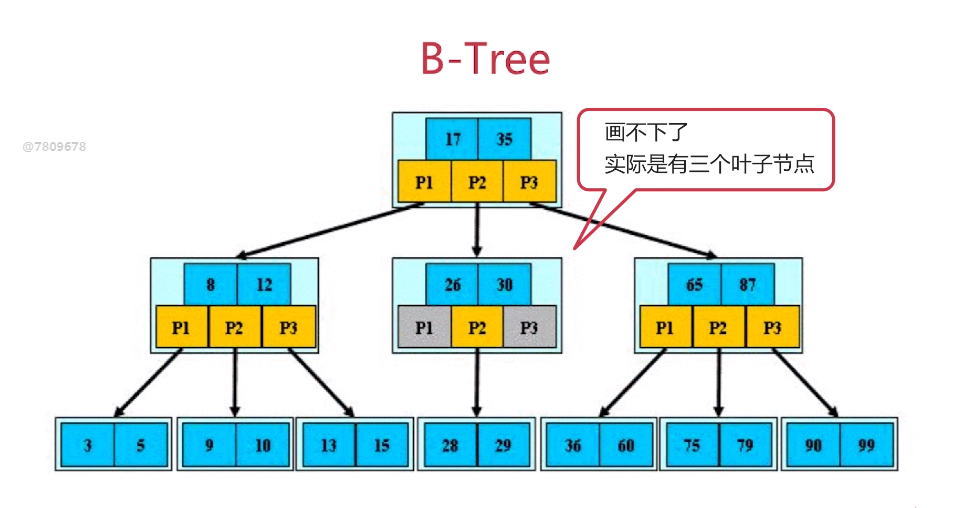
B-Tree
定义:
- 根节点至少包括两个孩子
- 树中每个节点最多含有m个孩子(m>=2)
- 除根节点和叶节点外,其他每个节点至少有ceil(m/2)个孩子。(注:ceil函数的意思是向上取整;例如ceil(3/2)=2)
- 所有叶子节点都位于同一层,即叶子节点的高度都一样的
- 假设每个非终端节点中包含n个关键字信息,其中
- Ki(i=1....n)为关键字,且关键字按顺序升序排序K(i-1)<Ki。
- 关键字的个数n必须满足:[ceil(m/2)-1]<=n<=m-1
- 非叶子节点的指针:P[1],P[2],....,P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其他P[i]指向关键字属于(K[i-1],K[i])的子树,(注:(K[i-1],K[i])是开区间的)
当数据出现增加和删除时,现有的树结构很有可能会打乱成线性的,由于上述的限制,B-Tree会通过相应策略(合并、分裂、上移、下移节点)保持原有的特征;所以B-Tree的时间复杂度会一直保持在O(logn)
B+-Tree
B+树是B树的变体,其定义基本与B树相同,除了:
- 非叶子节点的子树指针与关键字个数相同(表明能够存储更多的关键字)
- 非叶子节点的子树指针P[i],指向关键字值[K[i],K[i-1])的子树
- 非叶子节点仅用来索引,数据都保存在叶子节点中
- 所有叶子节点均有一个链指针指向下一个叶子节点,方便用来做统计。

结论
B+树更适合用来做存储索引
- B+树的磁盘读写代价更低,因为B+树内部结构并没有指向关键字具体信息的指针,也就是说不存放数据只存放索引信息。
- B+树的查询效率更加稳定
- B+树更有利于对数据库的扫描