点赞多大胆,就有多大产!微信公众号搜索【达摩克利斯之笔】获取更多资源,文末附二维码!
Github地址:https://github.com/stt0626/JavaGreat持续收录更新资料
前言
说到数据库优化脱口而出就是添加索引,如果不会用请移步《解锁数据库系列》数据库索引已为你备好!如果你也和我一样一直搞不懂数据库索引底层数据结构,懵X树上懵X果,懵X树下你和我,请在下方留言告诉我不止我一个,心里好受点,可是现在我已悟透,看完整篇文章相信你也和我一样拨开迷雾对天笑说:就这?对它就这,话不多说直接发车!
索引数据结构
数据库索引主要有Hash表、二叉树、红黑树、B树、B+树,我们MySQL使用的是B+树!
Hash索引
介绍
Hash索引(hash index)基于哈希表实现,对于每一行数据,存储引擎都会对所有的索引列计算一个hash码(hash code),哈希码是一个较小的值,哈希索引将所有的哈希码存储在索引中,同时在哈希表中保存指向每个数据行的指针。如果hash码一样则会采用链表的形式存储,类似于HashMap,Hash索引适用于精准查询。
举例
有下表
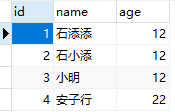
如果我们在name列建立索引,name数据库会使用哈希算法计算name列每一行数据的hash值并进行存储。因为Hash值是随机计算的,所以可能存在冲突,假如计算结果如下
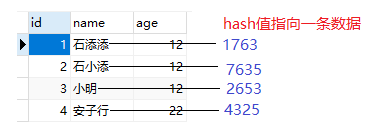
Hash索引数据结构如下

我们有一条SELECT id,name,age FROM t_user WHERE name=‘石小添’; 这样的一条SQL可以直接对石小添 按哈希算法算出来一个Hash值,通过该值找到对应的记录指针,通过记录指针找到表中的哪一行数据,最后比较name是否为石小添,以保证就是要查找的行。
但是如果我们有 SELECT id,name,age FROM t_user WHERE name>‘石小添’; 这样的一条SQL则无能为力,因为Hash表支持快速的精确查询,但是不支持范围查询。
Hash索引总结
- 哈希索引只包含哈希值和行指针,而不存储字段值,所以不能使用索引中的值来避免读取行
- 哈希索引数据并不是按照索引值顺序存储的,所以也就无法用于排序
- 哈希索引不支持部分索引列匹配查找,因为哈希索引始终是使用索引列的全部内容来计算哈希值
- 哈希索引只支持等值比较查询,不支持任何范围查询
- 访问哈希索引的数据非常快,除非有很多哈希冲突(不同的索引列值却有相同的哈希值)。当出现哈希冲突的时候,存储引擎必须遍历链表中所有的行指针,逐行进行比较,直到找到所有符合条件的行
- 如果哈希冲突很多的话,一些索引维护操作的代价也会很高。例如,如果在某个选择性很低(哈希冲突很多)的列上建立哈希索引,那么当从表中删除一行时,存储引擎需要遍历对应哈希值的链表中的每一行,找到并删除对应行的引用,冲突越多,代价越大
二叉树
二叉树(Binary Tree)是每个结点最多有两个子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。二叉树常被用于实现二叉查找树和二叉堆。
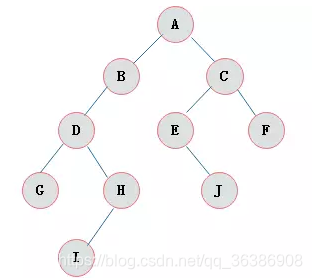
举例
id列添加索引使用二叉树进行存储,如下图
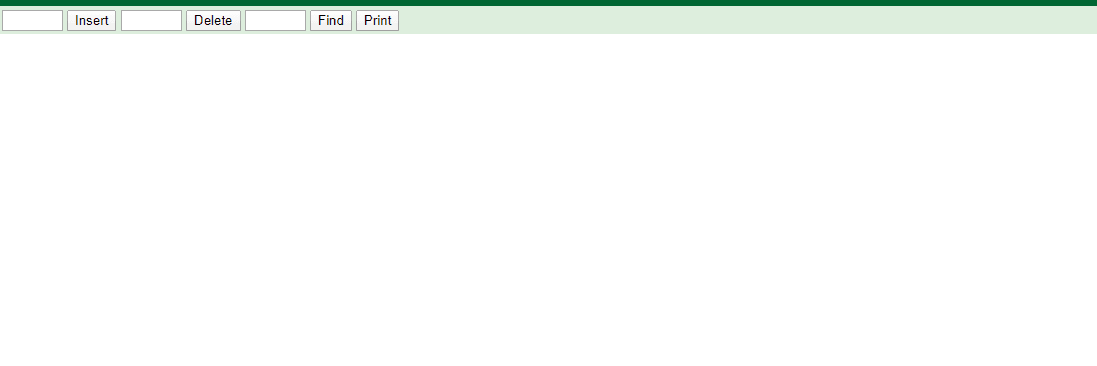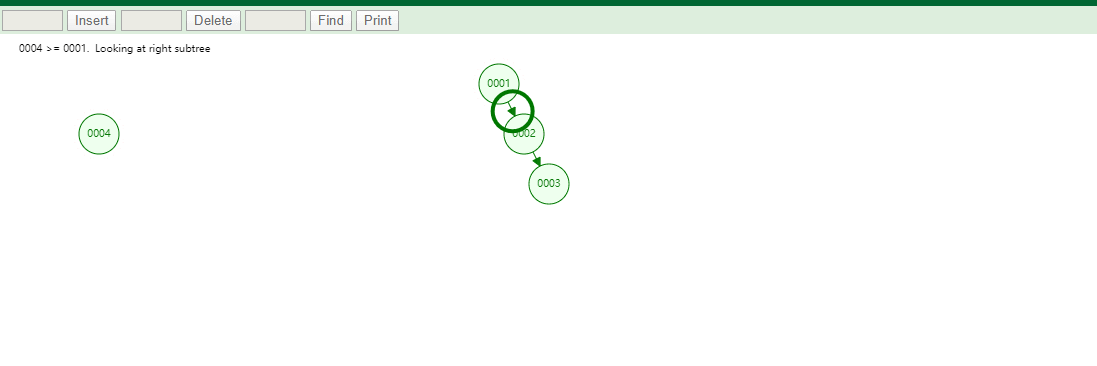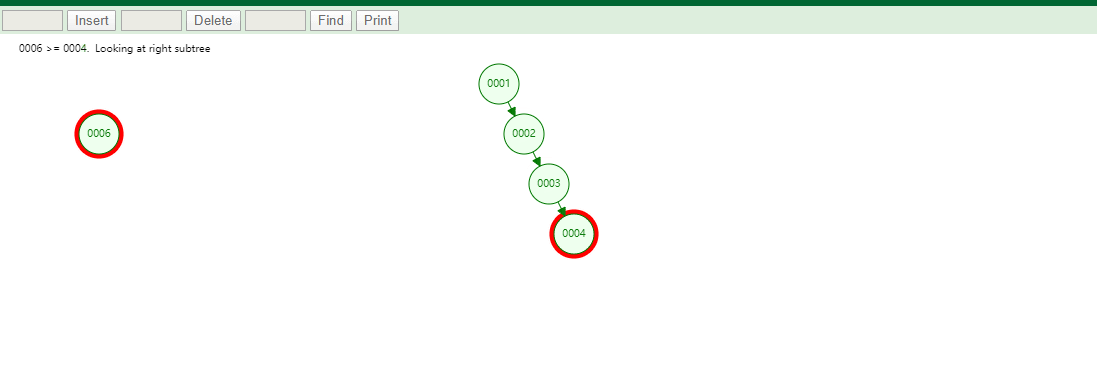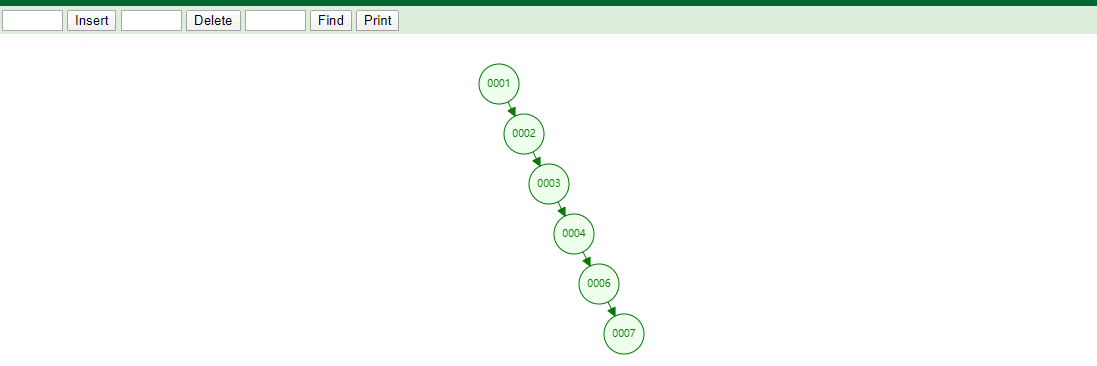
如果我们的数据是单边增长的最终二叉树可能成为一个链表,我们查询一个数据如下图
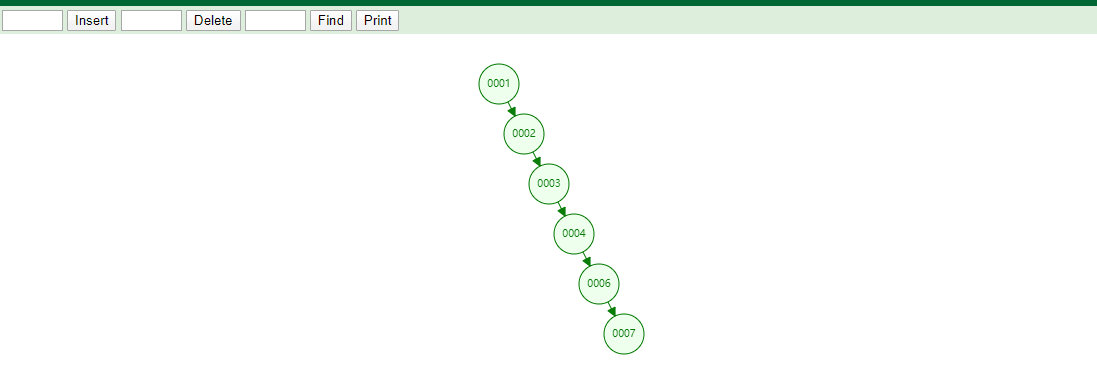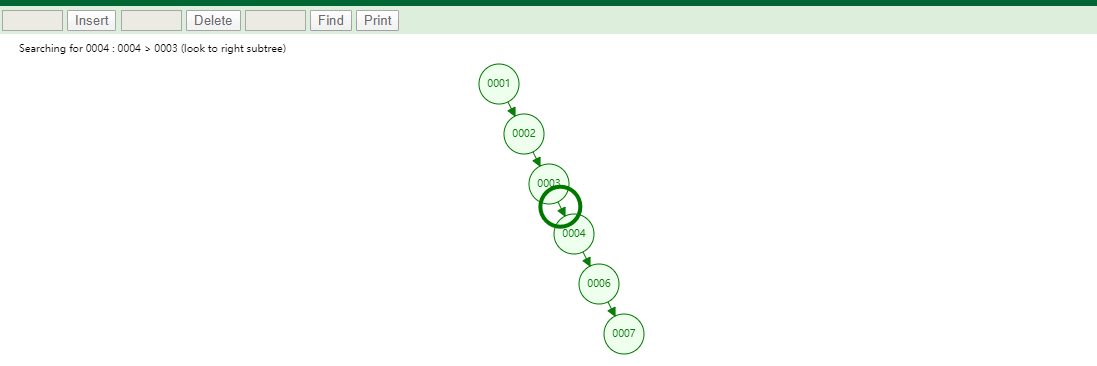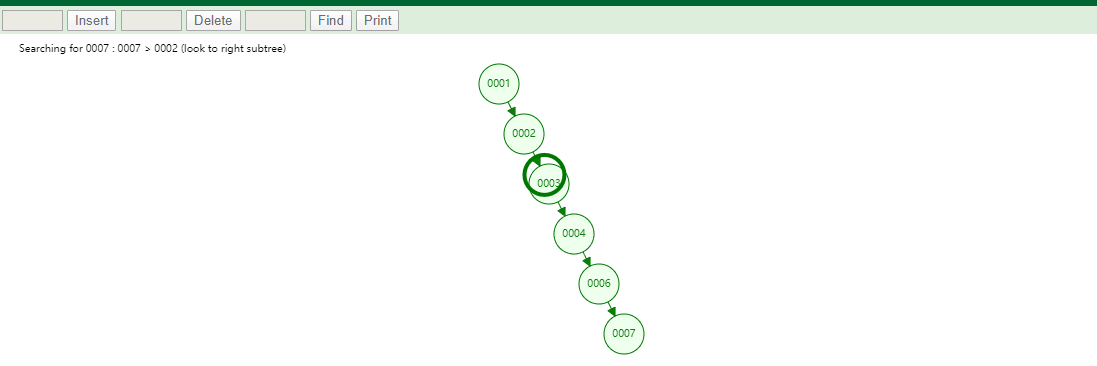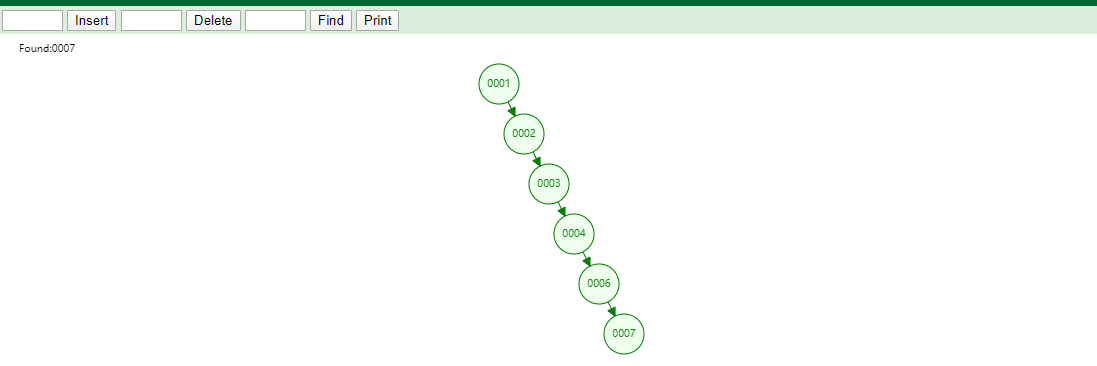
如果有一条SQL
SELECT id,name,age FROM tb_user WHERE id=7,对该字段创建索引并且使用的是二叉树维护它会查找6次,速度和没有创建索引是一样的!
二叉树索引在索引字段是连续时或其他场景下性能很低,而且这棵树是不平衡的严重倾斜,我们就此引出红黑树
二叉树特点
- 若它的左子树不空,则左子树上所有结点的值均小于它的根节点的值;
- 若它的右子树上所有结点的值均大于它的根节点的值;
- 它的左、右子树也分别为二叉排序树
红黑树
红黑树(Red Black Tree)是一种含有红黑结点并能自平衡的二叉查找树,是一种平衡二叉树。红黑树的每个节点上都有存储表示节点的颜色,可以是红(Red)或黑(Black)
相同的,id列添加索引使用红黑树进行存储,如下图,我们会发现会做一个调整,使这棵树相对平衡,较小的值放上级节点左边,较大的值放上级节点右边
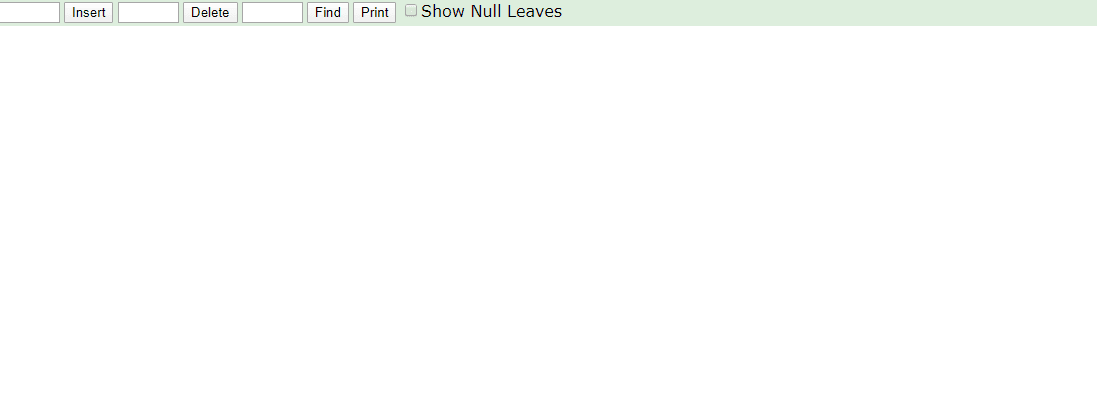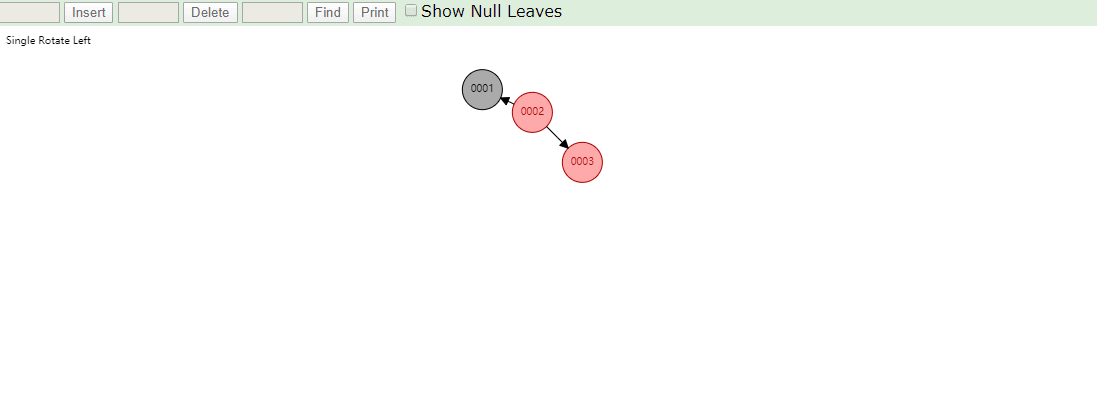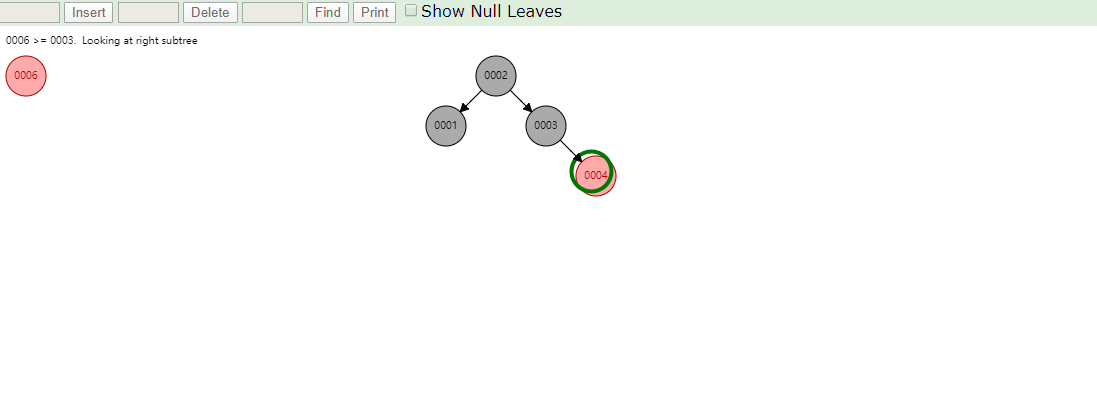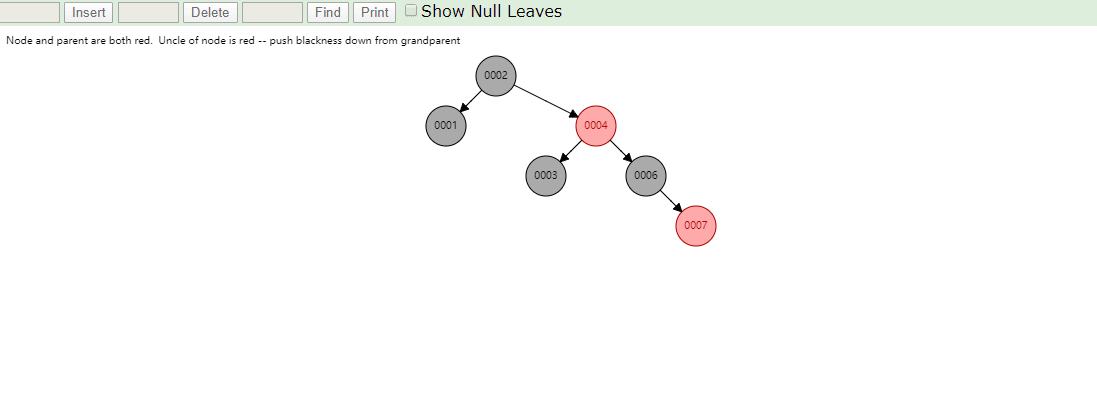
相同的去查找一样的4和7两个数据,如下图
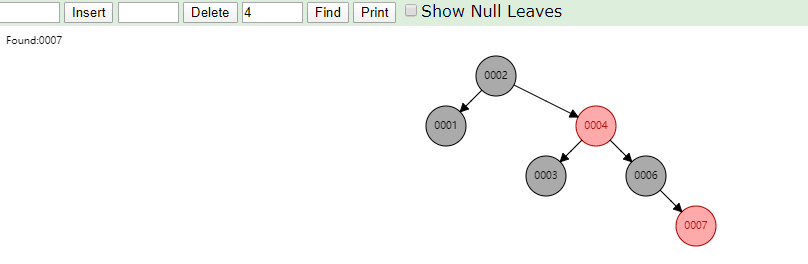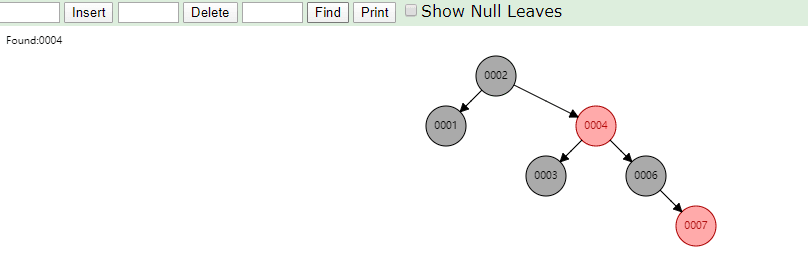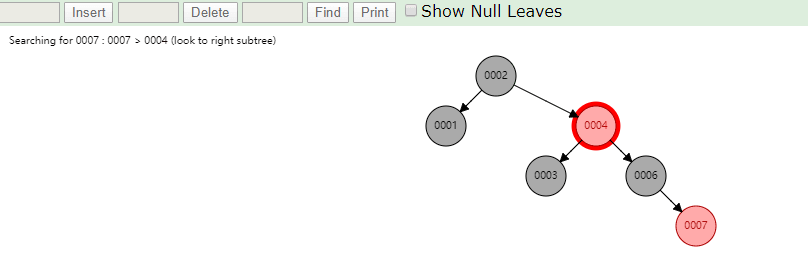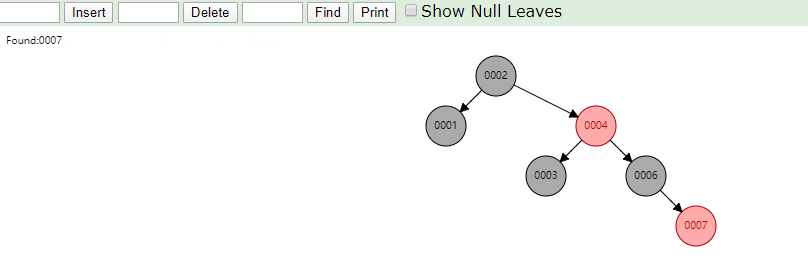
很显然我们使用红黑树之后相对于二叉树来说,这棵树更加平衡,搜索数据也更快,MySQL仍然不用该数据结构来维护索引数据是为什么?下边来分析一下,彻底搞定
红黑树弊端
- 目前表中有6条数据,所以需要将这六列存储起来使用红黑树维护,那么这棵树的高度h=4,分别为2、4、6、7四个节点,这里没有问题吧
- 我们实际项目中数据不可能只有几条,都是百万条,千万条数据,如果红黑树要维护百万条,千万条数据,那么这可红黑树的高度h=?,很好计算,如果我们要想表中存储100W条数据,也就是有100W个红黑节点,每个节点有2个分支,将整棵树撑满2^n=1000000,n就是h深度,自己算一下吧
- 通过上边的分析,我们发现使用红黑树维护索引数据,这棵树的深度太深,太深就~~~
- 如果你要查找的数据在叶子节点,那么查询的次数也是蛮多的
通过上边的红黑树我们可以发现数据越多数高度就越高,树越高查询数据需要的次数就越多,我们控制住树的高度,就可以控制查询的次数,这就是我们的B树要来完成的伟业,所以大家不妨喝杯茶,思考一下在红黑树的基础上将树的高度控制在3-5层,进而存储千万条数据,若是你,将如何?
B树
二叉树和红黑树都是一个节点上存储一个数据,而B数是在红黑树的基础上一个节点上存储多个数据,所谓的B-Tree,BTree,B树说的都是同一个东西,全称Balance-tree译为平衡多路查找树,平衡为左边和右边分布均匀。·多路为相对于二叉树而言,二叉树就是二路查找树,查找时只有两条路,而B-tree有多条路,即父节点有多个子节点,看图说话

哦,是这张
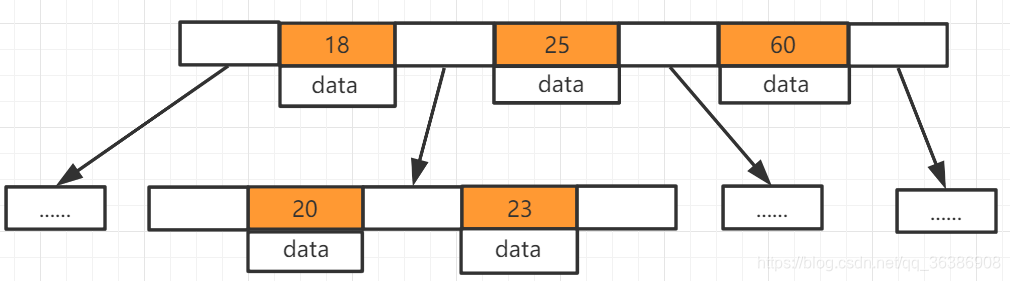
- 上边18、25、60是一个节点,20、23是一个节点,同一个节点上存储多个数据
- data是在该节点上存储的数据,如果是mysql中使用B树存储的就是数据的磁盘地址,就是我们要查找的那行数据在磁盘上的位置
- 到索引中找到对应的节点,在节点中找到对应的数据,再获取磁盘地址就可以找到这行数据
看看B树存数据,存完之后一共有四个节点,2、4存一个节点,1一个节点,3一个节点,6、7一个节点,1比2小所以1在2的左侧,3比2大比4小,所以在2右侧4的左侧,2、4就在同一个节点上存储,6、7都比4大,所以存储在一个节点上在4的右侧
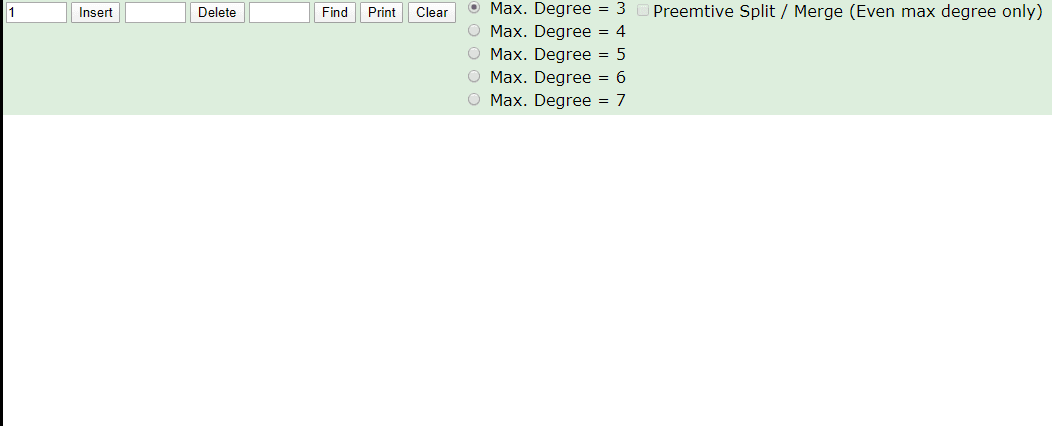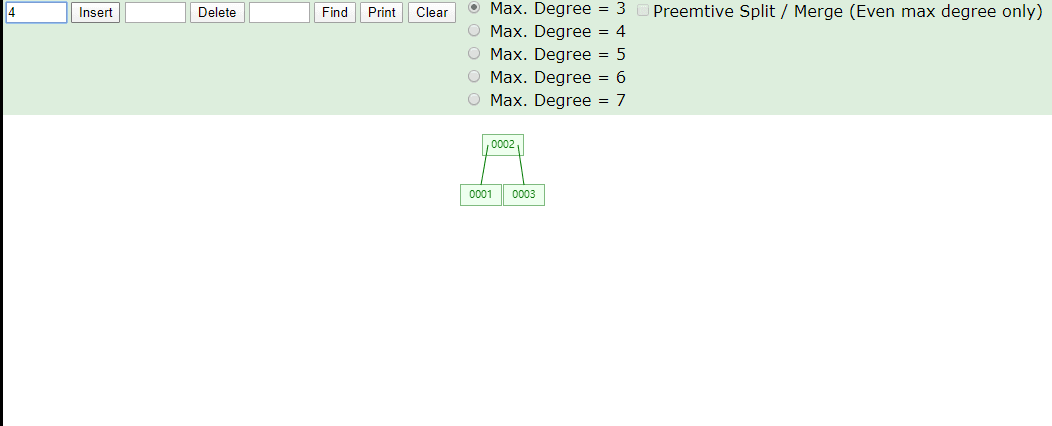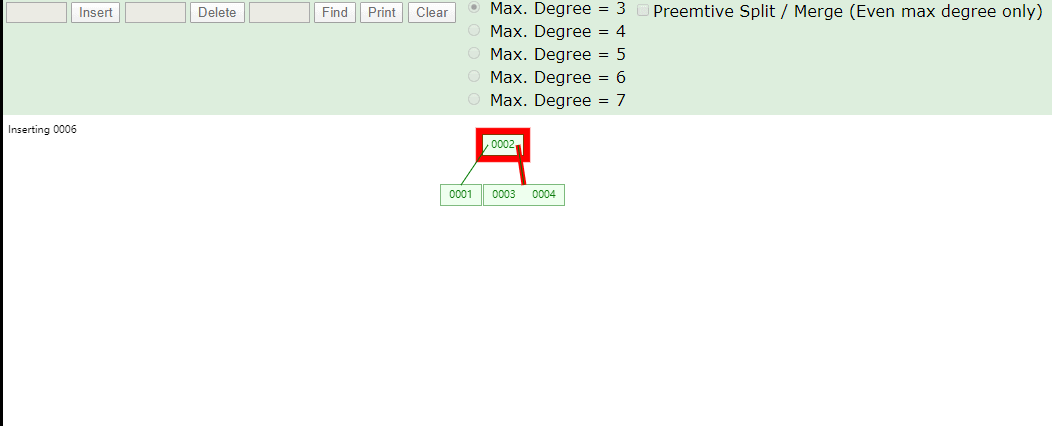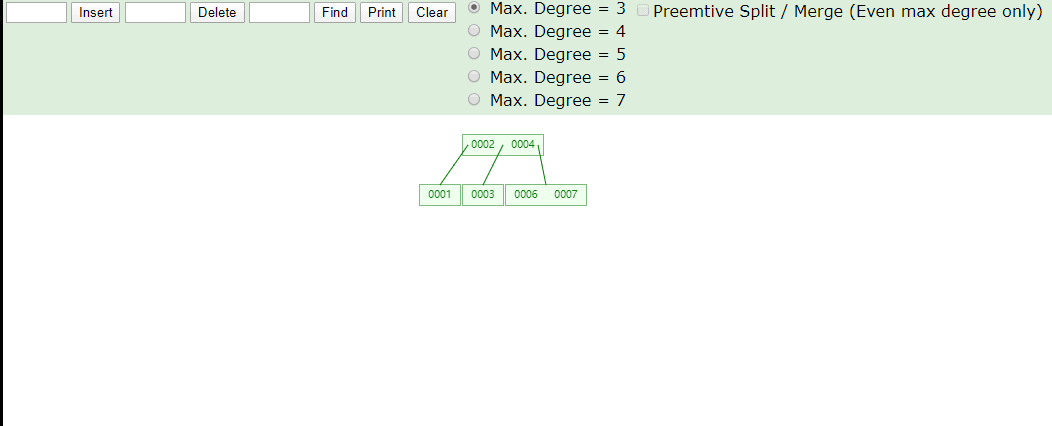
在看看B树取数据,我们第一次取4根节点直接找到数据,第二次取7,找两次确定所在节点
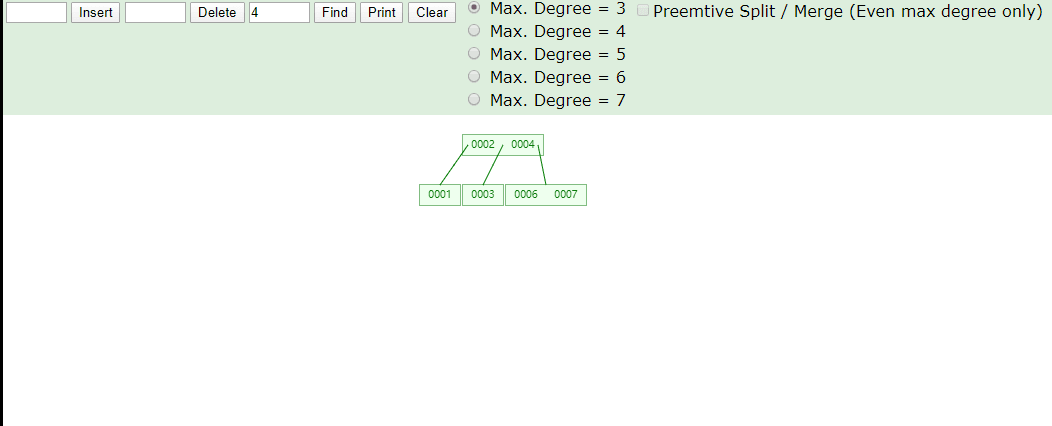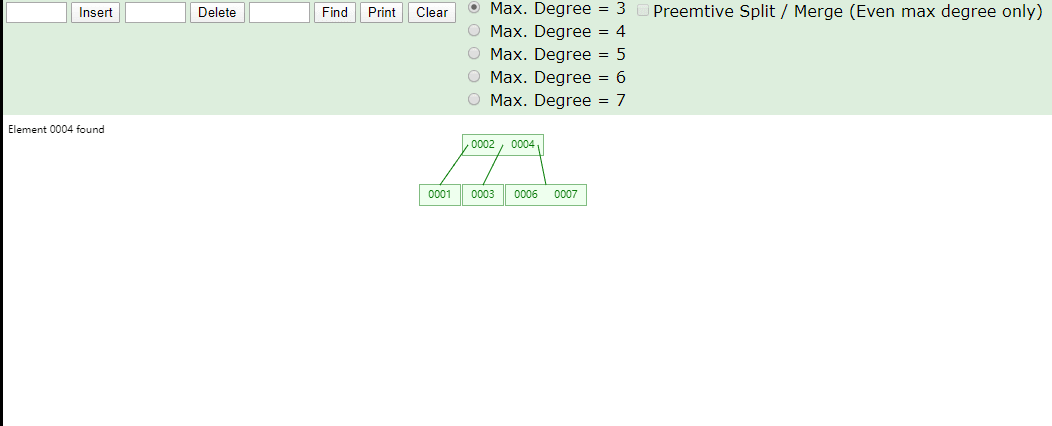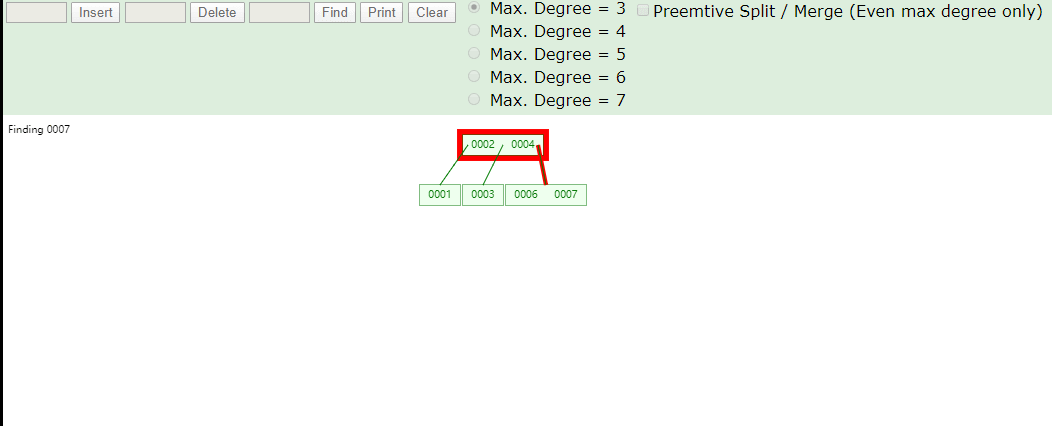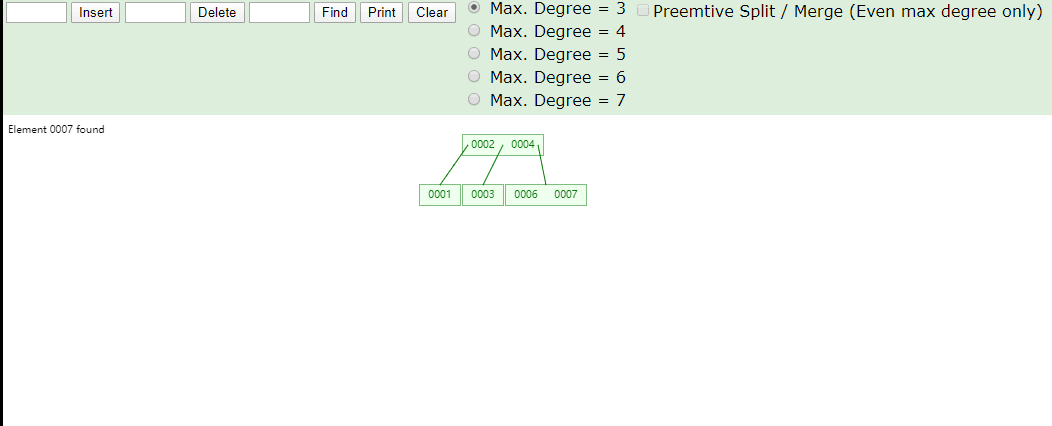
B树特点
- B-Tree可以显著减少定位记录时所经历的中间过程,从而加快存取速度。这个数据结构一般用于数据库的索引,综合效率较高
- 关键字集合分布在整颗树中,任何一个关键字出现且只出现在一个结点中
- 节点中的数据从左到右依次排序
- 搜索有可能在非叶子结点结束,
叶子结点就是出度为0的结点就是没有子结点的结点 - B-树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为空,或已经是叶子结点
B+Tree
B+Tree是B-Tree的变种,MySQL就是使用B+Tree作为索引数据结构,上图
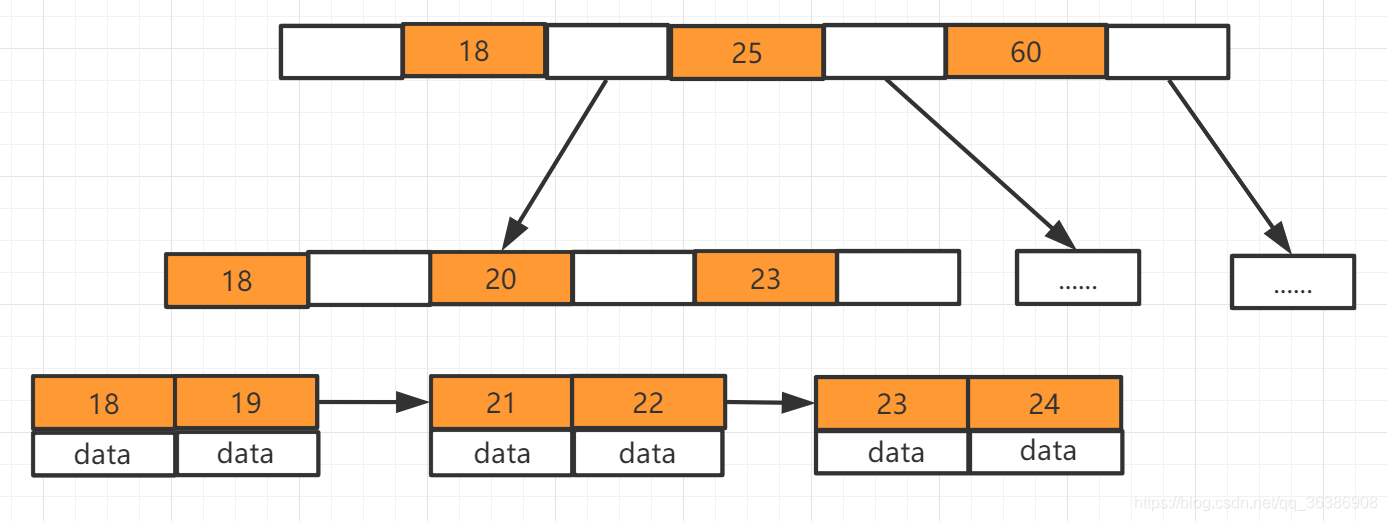
- 非叶子节点并不存储数据
- 节点冗余,叶子结点包含所有的非叶子节点
- 数据在叶子结点存储,而且叶子结点之间有箭头指向
B+Tree存数据
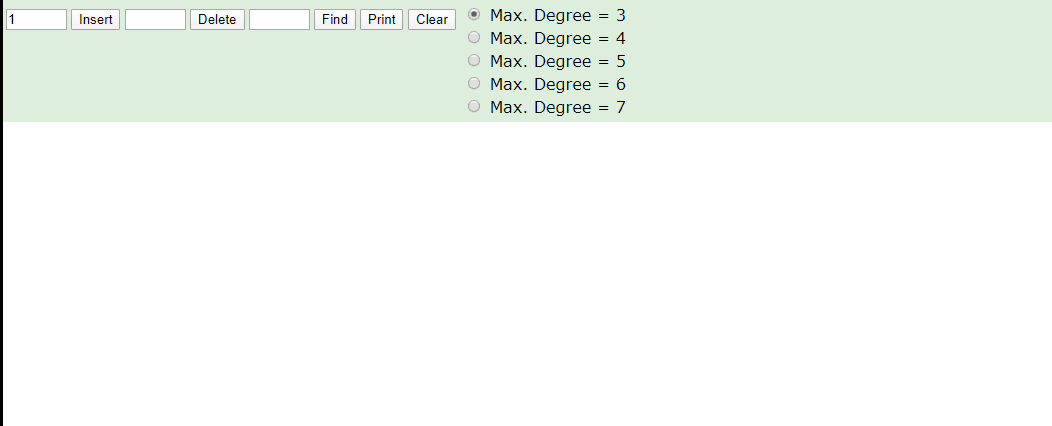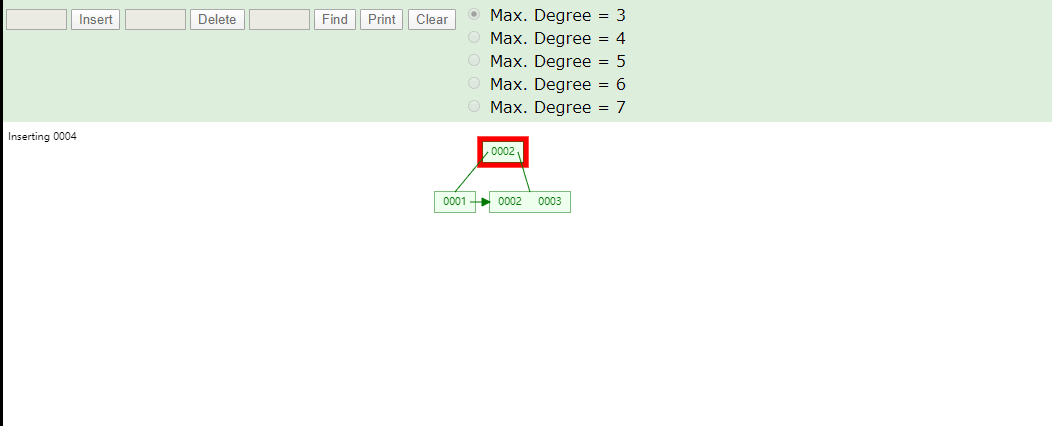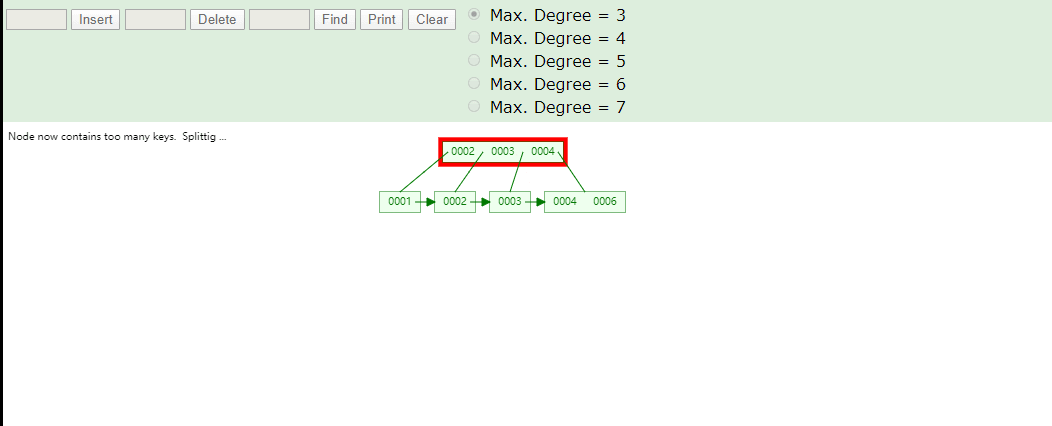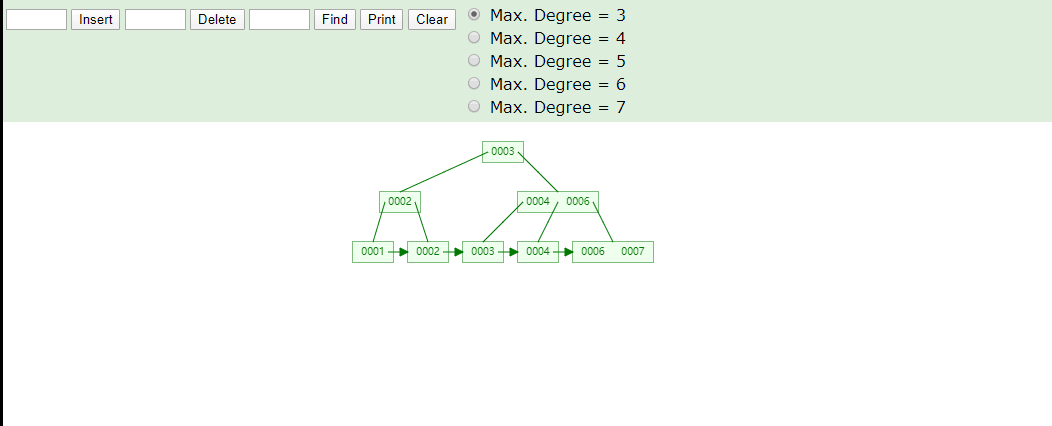
B+Tree取数据
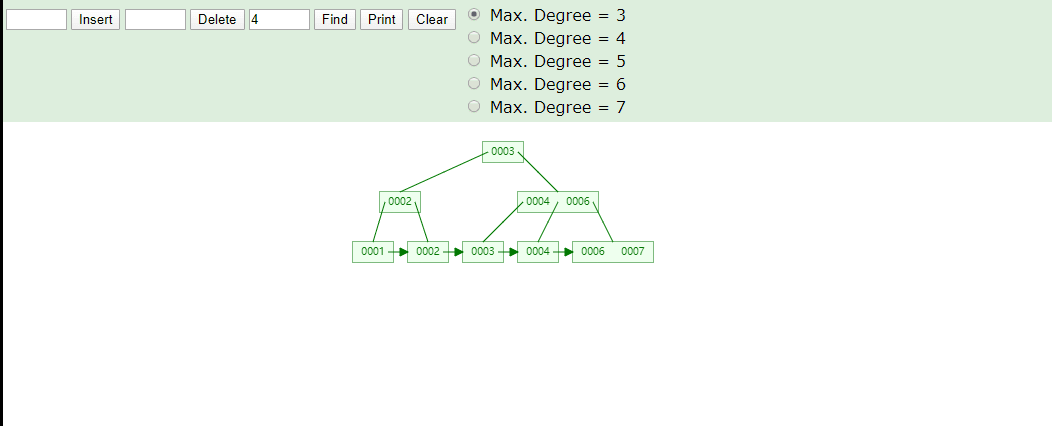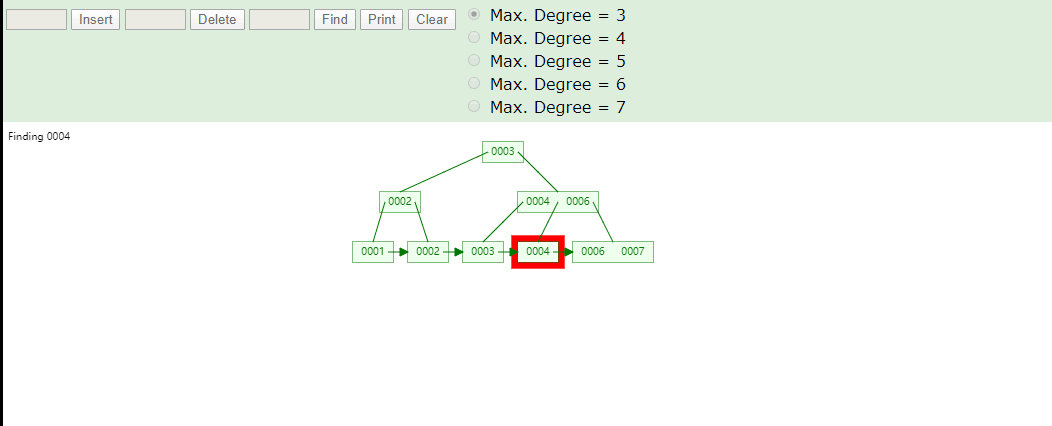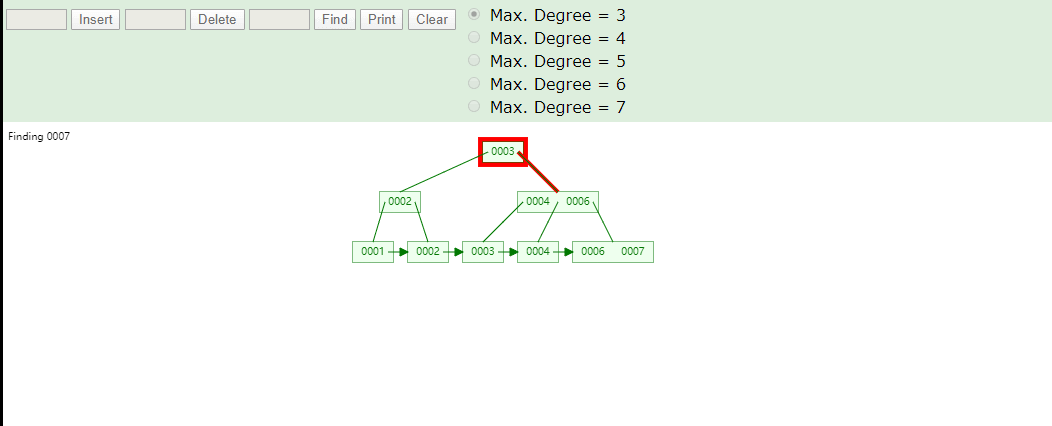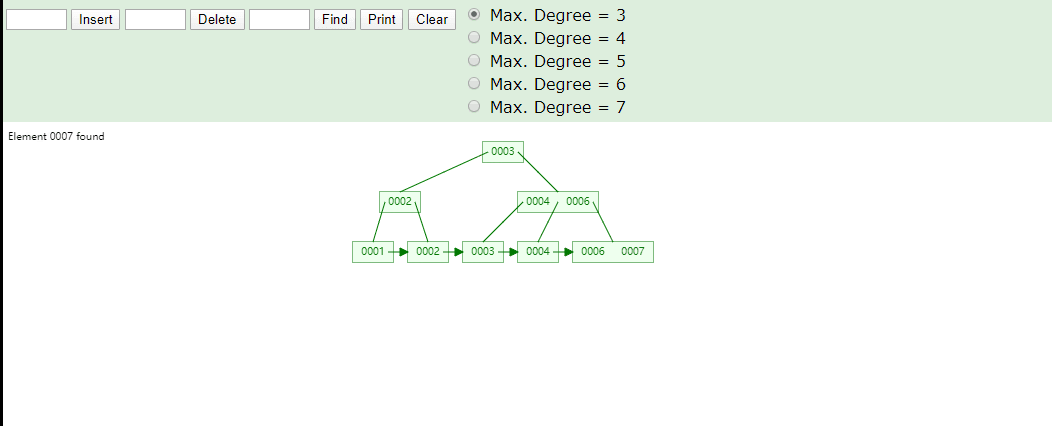
B+Tree为什么将数据存储到叶子结点进行冗余
data和节点都需要空间存储,如果将data移除,可以存出更多节点,MySQL中使用的B+Tree每一节点可以存储最多16KB数据可以通过SHOW GLOBAL STATUS LIKE 'InnoDb_page_size';这条SQL查询,在16KB的情况下MySQL使用B+Tree可以存储更多的索引元素,若表中id使用bigint当做索引占8Byte,同时使用6Byte记录该节点子节点位置那么一个索引字段占8+6=14Byte,16KB/14Byte=1170,每一个节点可以存储1170个元素

B+Tree存满可以存储多少数据
上边我们计算出每一个节点可以存储1170个元素,每一个节点还有子节点,假如树高为3每一个索引占1KB大小,这个1KB已经不小了,那么它可以存储1170*1170*16=2190W条数据,完全满足我们千万级别数据表的查询
B+Tree叶子结点剪头是干嘛的
B+树中的非叶子节点会冗余一份在叶子节点中,并且叶子节点之间用指针相连,最开始的Hash不支持范围查询,二叉树树高很高,只有B树跟B+有的一比,B树一个节点可以存储多个元素,相对于红黑树整体的树高降低了,磁盘IO效率提高了。而B+树是B树的升级版,只是把非叶子节点冗余一下,这么做的好处是为了提高范围查找的效率。提高了的原因也无非是会有指针指向下一个节点的叶子节点
B+Tree特点
- 所有关键字都出现在叶子节点的链表中(稠密索引),且链表中的关键字恰好有序
- 在B-树基础上,为叶子节点增加链表指针,所有关键字都在叶子节点中出现,非叶子节点作为叶子节点的索引;
- B+树总是到叶子节点才命中数据不可能在非叶子节点命中
- 更适合文件索引系统
- 单一节点存储的元素更多,使得查询的IO次数更少,所以也就使得它更适合做为数据库MySQL的底层数据结构
到这我们介绍了Hash、二叉树、红黑树、B-Tree、B+Tree每种数据结构,并且得出结论Mysql使用B+Tree作为维护索引的数据结构,可以提高查询索引时的磁盘IO效率,并且可以提高范围查询的效率,并且B+树里的元素也是有序的,接下来我们就说说Mysql中常见的两种存储引擎具体如何使用索引
Myisam存储引擎索引实现
创建表最后一行ENGINE=MyISAM
CREATE TABLE `tb_myisam` (
`id` int(11) NOT NULL,
`col1` varchar(255) DEFAULT NULL,
`col2` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
磁盘存储
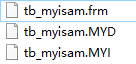
一个myisam表创建之后在磁盘上会有三个文件
frm,MYD,MYI维护
frm:存储表结构
MYD:存储表数据
MYI:存储表中索引
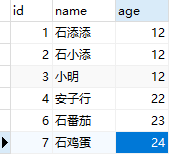
添加数据
insert into tb_myisam (id,col1,col2) VALUES
(2,"测试数据2","测试数据22"),
(4,"测试数据4","测试数据44"),
(5,"测试数据5","测试数据55"),
(7,"测试数据7","测试数据77"),
(1,"测试数据1","测试数据11"),
(3,"测试数据3","测试数据33"),
(6,"测试数据6","测试数据66");
查看数据
SELECT id,col1,col2 FROM tb_myisam
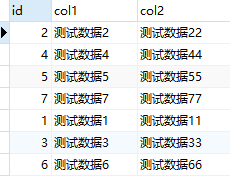
可以看到数据排序方式按照插入顺序排序
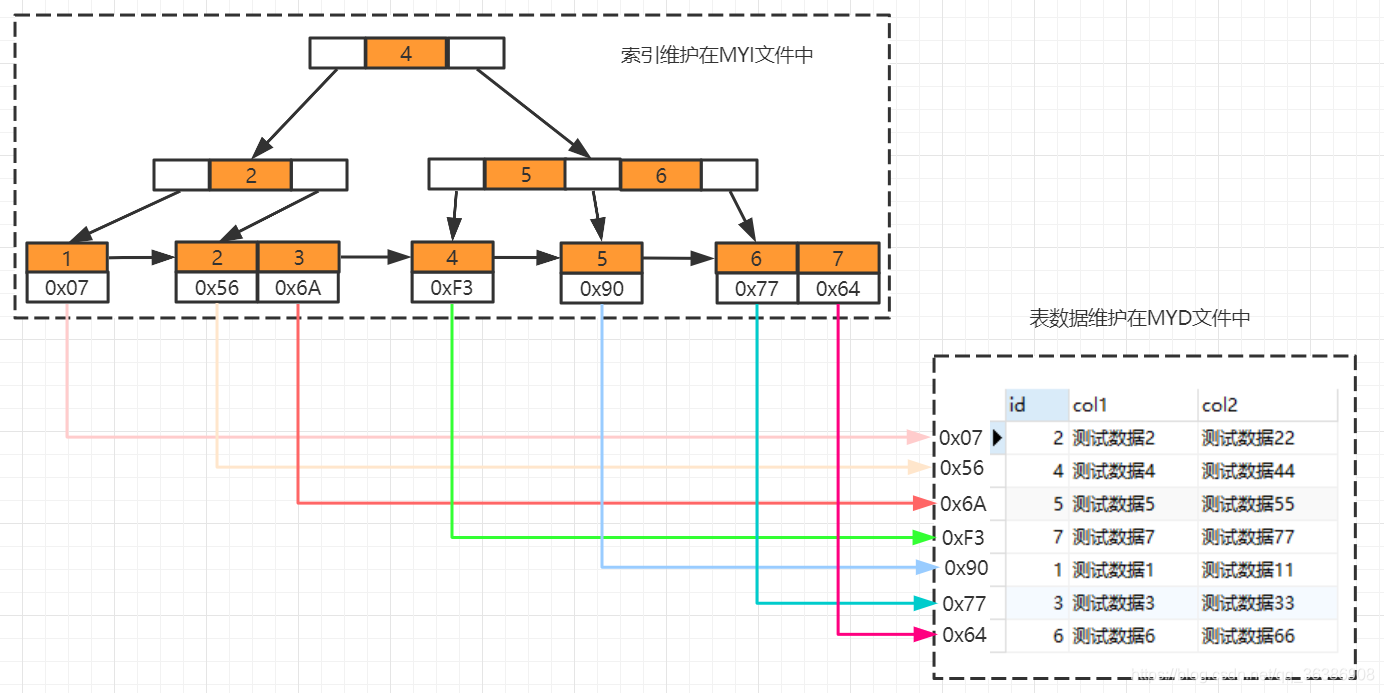
Myisam索引维护
在id列创建索引,左上角为数据维护在B+Tree中结构,右下角为数据表数据,B+Tree叶子结点下方的data存储的就是该行数据对应的磁盘地址,加入有一条
SELECT id FROM tb_myisam WHERE id=3会先到索引文件中找3这个节点,再取出对应磁盘地址,到MYD文件中找到这一行数据实现查询。
InnoDB存储引擎索引实现
创建表
CREATE TABLE `tb_innodb` (
`id` int(11) NOT NULL,
`col1` varchar(255) DEFAULT NULL,
`col2` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
磁盘存储
一个InnoDB表创建之后在磁盘上会有两个文件
frm,ibd维护
frm:存储表结构
ibd:存储表索引和数据
添加数据
insert into tb_innodb (id,col1,col2) VALUES
(2,"测试数据2","测试数据22"),
(4,"测试数据4","测试数据44"),
(5,"测试数据5","测试数据55"),
(7,"测试数据7","测试数据77"),
(1,"测试数据1","测试数据11"),
(3,"测试数据3","测试数据33"),
(6,"测试数据6","测试数据66");
查询数据
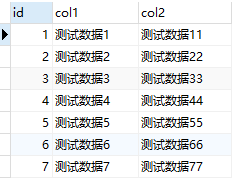
mysql主键自动创建索引,innodb搜索引擎按照主键排序
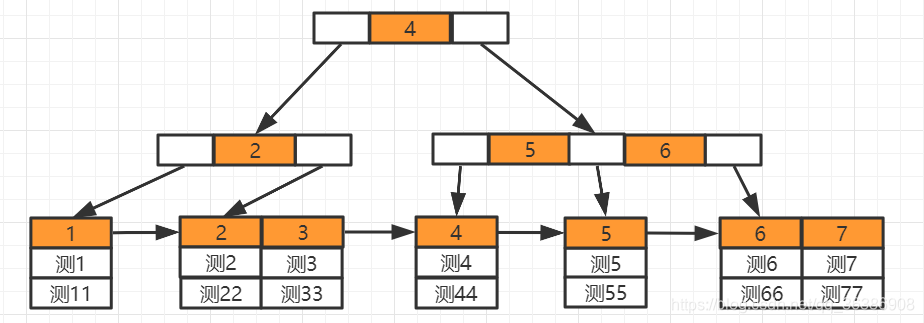
InnoDB索引维护
InnoDB存储引擎,表数据文件也就是ibd文件本身就是按照B+Tree组织的索引结构文件,叶节点包含了完整的数据记录
如果我们InnoDB没有索引怎么办,数据就无法存储了吗?
大家应该通过一句话InnoDB表必须有主键,并且这个主键建议使用整型自动递增的,如果你表中有主键那么会在主键上添加索引来维护,如果你创建表时没有指定主键,数据库会在你的表中找到唯一数据那列去维护,如果找不到这样的列,数据库默认会自己增加一列来维护。
推荐使用整型原因首先整型存储所占空间较小,而且比较排序时较快,可能有些公司在使用UUID当做主键等,UUID是一个随机的字符串,在比较时需要先转换再比较而且占用空间大,所以不推荐使用
推荐自动递增是因为我们叶子结点数据从左到右依次递增排序,在做范围查询时比较方便,如果你的数值是随机的就有可能修改树原有的结构,导致分裂,裂开造成性能影响,可以看下图举例,我们最后添加8进来看变化
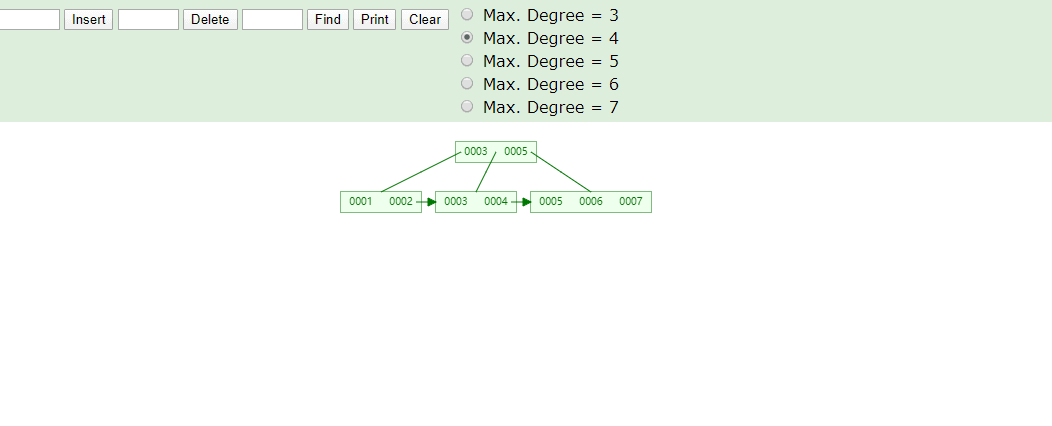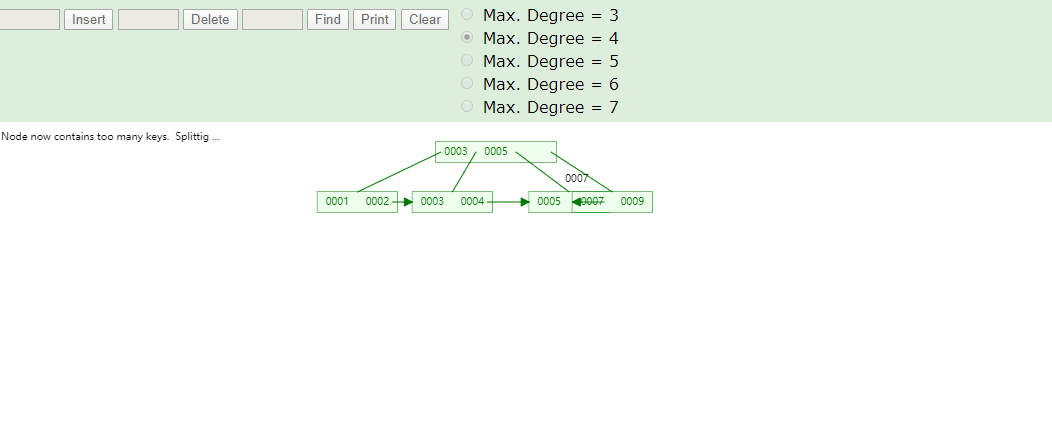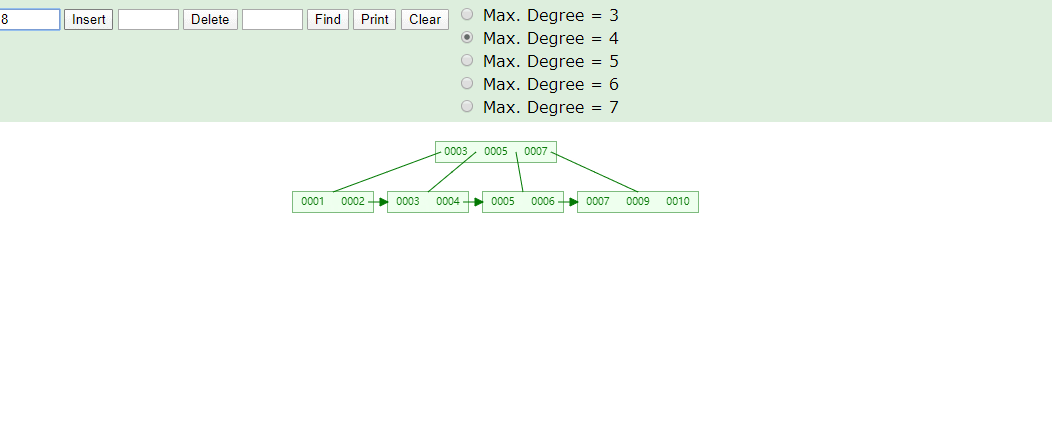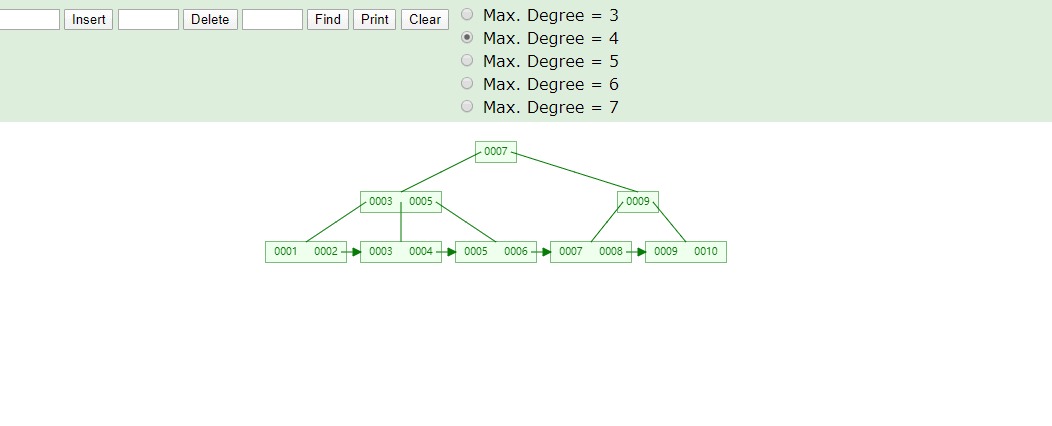
联合索引长什么样?
我们在开发项目时一般不创建单列索引,而是多个键创建联合索引,现在只要你把联合索引底层原理整明白,网上看的那些MySQL索引优化原则你就可以在底层原理上去理解,而不用再去背,我是很讨厌背东西的,背完马上忘没意思,下图就是联合索引长相

假设我们联合索引为(col1,col2,col3),分别为上图绿色方格中的三行数据,分别根据col1,col2,col3三列排序,紫色为其他非索引字段,这里要明白的是联合索引是按照什么排序的,
最左前缀法则,为什么索引会失效,以及网上的索引优化文章为什么要求你这么写,我想经过你的思考应该都明白!一定要勤于思考!
文章思路
《高性能MySQL》
《MySQL技术内幕:InnoDB存储引擎》
一点真实想法快来围观
首先很感谢读者关心本工具人内心想法,谢谢这么关心我抹眼泪,拉倒吧就是好奇,谢谢各位的关注和点赞。其次就是一些想法,这篇文章确实花费了不少时间和精力,底层原理的东西越研究越发现自己知之甚少,为了写好这篇文章让大家看懂这也是加入动图的第一篇文章,动图制作软件费了点功夫,学习看书的时间咱就不说了也是学到了自己身上嘛哈哈,之前写的博客都是在技术的使用上,因为我想着大家在我的博客中一个技术就可以从小白入门到高手进阶一条龙,但是发现确实精力有限,而且技术入门使用网上比比皆是,而且大家想看到的应该也是一些原理层,思想层方面的文章来提升自己进入大厂收割Offer,不仅仅是停留在初级阶段,我们需要快速成长,所以后边的文章专注写原理层,思想层,产品,学习路线等方面文章,入门小白可以看学习路线系列文章,工作1-3年朋友可以看原理层,思想,架构方面文章,5年左右朋友可以看看产品,从宏观上认识如何设计好一个好的产品,在高级的我暂时能力有限也怼不出来,好羞耻。
创作不易,码字辛苦,有时候真的会写到头晕没有思路,但一直在坚持,希望喜欢有帮助的朋友**【不要白嫖】**,记得点赞,有问题底下留言或者关注公众号添加微信好友,QQ好友等相互探讨,一起成长不再迷茫原地踏步,不再被同事按到地上摩擦,不再仰慕他人,而成为他人焦点
在这里给大家准备学习资料,直接贴出链接会被博客运营小姐姐通知,想成为风景线的老铁关注公众号,回复【资料】即可!
加行字吧,两张图在一起太突兀,扫描下方二维码关注公众号,回复【资料】获取资源

总结
本篇讲解N中数据结构,MySQL索引底层原理,本咸鱼准备转换博客更新方向,世间唯一不变的便是变化,他信不如自信,一起学习翻身做另一面的咸鱼
路漫漫其修远兮,吾将上下而求索
