在进行数据分析时,免不了要用到pandas库,网上关于pandas的操作说明已经是很全了,在这里不再赘述。
我将记录一下今天下午在进行数据集的读取时,遇到的一些小问题,进行相关的记录,望后来者不再犯相同的错误,也是给自己的一个小小的总结。
1.(.csv)文件;
2.工具:Jupyter Notebook(简称jp) ,Pycharm(简称pc);
3.使用anconda中的pandas库;
一、问题描述
当我在利用jp进行.csv文件的读取时出现了下面这种现象:

这个其实是很常见的问题,那是因为我们常常会忘记先执行之前的代码,而是先执行了后面的代码,导致pandas库实际上是没有被import的。
很快我也发现了这个问题,这都是粗心导致的,小伙伴们需要警惕这些小错误!
这个问题被解决了,不幸的是,出现了另一个问题,如下图所示:

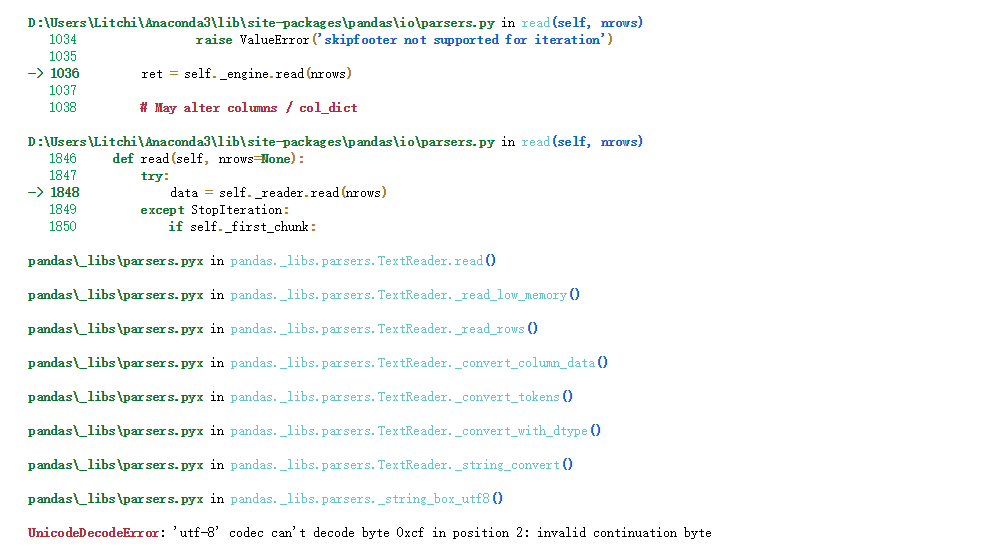
看到这一长串错误,作为一个上手没多久的小白来说心里难免会心慌,这问题处在哪里呢?
二、思考错误来源
强行让自己冷静下来,想一想我在这些操作中哪里会出现问题?百度了一番,我有以下3个怀疑对象:
1.代码写错了?(不可能啊,一共就两行代码,校对了100遍也看不出什么错误,排除!)
2.这是我第一次使用jp,是不是这个编译器出现问题了?(应该不会吧,其它加减乘除都可以的呀,路径/环境从错误中可以看出也没有问题,为确保万无一失,
我在cmd中查看我的pandas库是否安装,种种迹象表明应该不是编译器的问题,但我还是不放心,由于我多次使用且运行pc(pycharm)是没有问题的,我把这
两行代码放到pc上是不是可以正常运行,但是实践告诉我也出错了,也排除了jp的错误,冤枉它了,对不起!)
3.有可能是我读取的数据集有问题,因为错误的最后是:'utf-8' codec can't decode byte 0xcf in position 2: invalid continuation byte ,这让我想起数据集一般都不
是utf-8的格式,因此我另存为了utf-8格式的.csv数据集,然后进行数据的读取操作,终于正常了!
三、反思
这一个可能对于有经验的程序员来说可能几分钟或者几秒钟就解决了,而我花了将近一个小时进行思考、错误定位、实践检验等,这其中有我的不仔细造成的错误,
也有原先我并不知道的错误,现将这些错误整理一下,为将来的自己或者读者遇到类似的问题可以参考,也是对自己的一种反思、警戒!
2019.05.19