题目
https://leetcode.com/problems/regular-expression-matching/
题意
给出一个模式串P,和一个字符串S。判断字符串S是否符合模式串P。
P和S要么是空串,要么是小写字母组成的串。
Example 1:
Input:
s = "aa"
p = "a"
Output: false
Explanation: "a" does not match the entire string "aa".Example 2:
Input:
s = "aa"
p = "a*"
Output: true
Explanation: '*' means zero or more of the precedeng element, 'a'. Therefore, by repeating 'a' once, it becomes "aa".Example 3:
Input:
s = "ab"
p = ".*"
Output: true
Explanation: ".*" means "zero or more (*) of any character (.)".Example 4:
Input:
s = "aab"
p = "c*a*b"
Output: true
Explanation: c can be repeated 0 times, a can be repeated 1 time. Therefore it matches "aab".Example 5:
Input:
s = "mississippi"
p = "mis*is*p*."
Output: false思路
author's blog == http://www.cnblogs.com/toulanboy/
(1) 这个题目非常有意思。对于这个题目,其实可以用形式语言与自动机的知识解决。
因为我们可以把模式串S对应的NFA(不确定的有穷状态自动机)画出来。
然后将字符串P代入到这个NFA,假如能到达自动机的终点,那么说明该字符串符合该模式串。
(2)进一步的,我们可以把NFA看成一张图,这个图代表着状态空间,第i层代表前i个模式字符能代表的字符串,每一个状态都是代表一种类型字符的集合。若是我们的字符串S符合模式串P,那么我们通过深搜到第P.length()层时,S所用的字符数应该是P.length()。 状态空间简图如下:
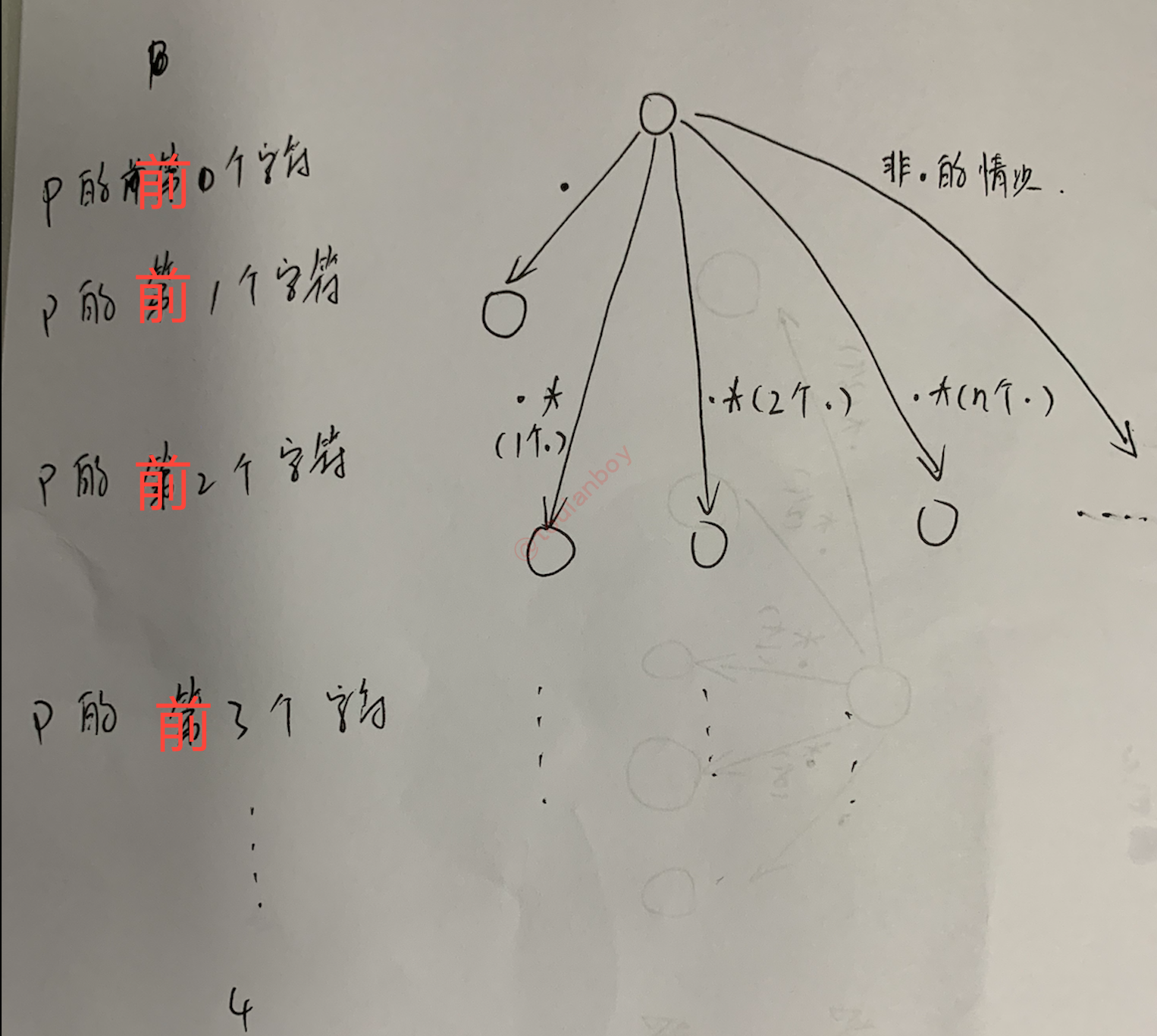
(3)字符串P代入到这个NFA的过程就等同于在该图中进行深度优先搜索。首先从第1层开始,这时候有新的模式串字符,当字符串P的对应字符和当前模式串字符对应时,则继续往下一层走。依次类推,不停地深度搜索,如果发现这个分支不行,则回退到上一层。如果能走到最后一层,且当前字符串也用完了所有字符,则说明该字符串符合该模式串。
在遇到新模式串字符时,我们要判断是.还是其他字母。
(3.1)若是.,则判断后面有无*。若有*则说明任意字符在这里出现多次(注意是0次以上,包含0次)。
(3.2)若是其他字母,也判断后面有无*。若有*则说明该字符在这里出现多次(注意是0次以上,包含0次)。
星号的存在意味着某字符出现0次或以上,所以会在该状态产生很多分支。
我们可以把模式串P的第i个字符看成层次。每一条边都代表模式串的一次状态转移。
状态空间是模式串的每一个状态。
代码
//author's blog == http://www.cnblogs.com/toulanboy/
class Solution {
public:
bool dfs(string s, string p, int i, int j){
if(i == p.length() && j == s.length())
return true;
if(i >= p.length() || j > s.length())
return false;
//(1)如果遇到.
if(p[i] == '.'){
//(1.1) .后没有字符了 或者 .后不是*
if(i+1 == p.length() || p[i+1] != '*'){
return dfs(s, p, i+1, j+1);
}
//(1.2) .后是*
else if(p[i+1] == '*'){
//.可以出现0次或多次,所有这里有很多分支
while(j <= s.length()){
if(dfs(s, p, i+2, j))
return true;
j++;
}
return false;
}
}
///(2)如果不是.
//author's blog == http://www.cnblogs.com/toulanboy/
else if(p[i] != '.'){
//(2.1) 该字符后面没有字符了 或者 该字符后面不是*
if(i+1 == p.length() || p[i+1] != '*'){
if(p[i] == s[j]){
return dfs(s, p, i+1, j+1);
}
else
return false;
}
//(2.2) 该字符后面是*
else if(p[i+1] == '*'){
//该字符出现0次的情况
if(dfs(s, p, i+2, j))
return true;
//该字符出现1次以上的情况
while(j < s.length() && p[i] == s[j]){
j++;
if(dfs(s, p, i+2, j))
return true;
}
return false;
}
}
return false;
}
bool isMatch(string s, string p) {
if(p.length() == 0)
return !s.length();
return dfs(s, p, 0, 0);
}
};运行结果
Runtime: 656 ms
Memory Usage: 166.7 MB