对抗攻击(adversarial attacks)汇总
参考论文:Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey
对抗攻击概念
当前的深度网络极易受到对抗攻击的影响,这种攻击的形式是使人类视觉系统(几乎)无法察觉的图像的小干扰,然而却会让神经网络分类器完全改变它对图像的预测。更糟糕的是,被攻击的模型对错误预测有很高的自信心,此外,同样的图像干扰可以欺骗多种网络分类器。
攻击分类:
- 黑盒攻击(black-box attack)和白盒攻击(white-box attack)
- 通用扰动(universal perturbations)和特定图像攻击扰动(image-specific adversarial perturbations)
- 目标攻击(targeted attacks)和无目标攻击(non-targeted attacks)
- 一次到位方法(One-shot/one-step methods) 和迭代方法( iterative methods)
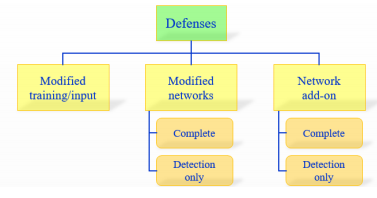
防御分类:
- 修正训练&修正输入(modified training/input),修正网络(Modifying networks)和增加网络(network add-on)
- 完全防御(complete defense)和只检测防御(detection only)
攻击性能:
- 愚弄比(fooling ratio/rate)
- 可转移性(Transferability)
- 扰动量(Disturbance quantity)
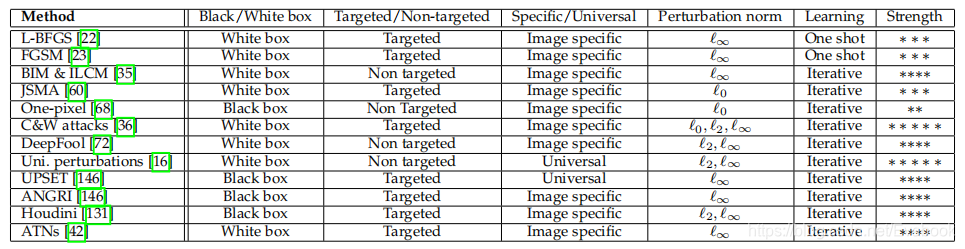
常见对抗攻击方法
Box-constrained L-BFGS link
Fast Gradient Sign Method (FGSM) link
Basic & Least-Likely-Class Iterative Methods
Jacobian-based Saliency Map Attack (JSMA)
One Pixel Attack
Carlini and Wagner Attacks (C&W)
DeepFool
Universal Adversarial Perturbations
性能:攻击性能,针对目标,攻击优势及缺点,运算复杂度,算法对比等等。
GAN相关
- PGGAN link
对抗攻击原理探讨
深度学习对抗样本的八个误解与事实
1、原文及译文 link