谷歌大脑(Google Brain)最近的研究表明,任何机器学习分类器都可能被欺骗,给出不正确的预测。Google Brain是Google内部用于训练大规模深度神经网络的构架,它为用户提供了方便的API。用户能够很容易的在大规模机群上训练神经网络模型。现在的应用几乎遍及Google的所有领域,包括android的语音识别系统,广告推荐系统,图像识别系统,自动驾驶系统。
目前人工智能和机器学习技术被广泛应用在人机交互,推荐系统,安全防护等各个领域。具体场景包括语音,图像识别,信用评估,防止欺诈,过滤恶意邮件,抵抗恶意代码攻击,网络攻击等等。攻击者也试图通过各种手段绕过,或直接对机器学习模型进行攻击达到对抗目的。特别是在人机交互这一环节,随着语音、图像作为新兴的人机输入手段,其便捷和实用性被大众所欢迎。同时随着移动设备的普及,以及移动设备对这些新兴的输入手段的集成,使得这项技术被大多数人所亲身体验。而语音、图像的识别的准确性对机器理解并执行用户指令的有效性至关重要。与此同时,这一环节也是最容易被攻击者利用,通过对数据源的细微修改,达到用户感知不到,而机器接受了该数据后做出错误的后续操作的目的。
什么是对抗攻击?
由于机器学习算法的输入形式是一种数值型向量(numeric vectors),所以攻击者就会通过设计一种有针对性的数值型向量从而让机器学习模型做出误判,这便被称为对抗性攻击。
和其他攻击不同,对抗性攻击主要发生在构造对抗性数据的时候,之后该对抗性数据就如正常数据一样输入机器学习模型并得到欺骗的识别结果。在构造对抗性数据的过程中,无论是图像识别系统还是语音识别系统,根据攻击者掌握机器学习模型信息的多少,可以分为如下两种情况:
白盒攻击
攻击者能够获知机器学习所使用的算法,以及算法所使用的参数。攻击者在产生对抗性攻击数据的过程中能够与机器学习的系统有所交互。
黑盒攻击
攻击者并不知道机器学习所使用的算法和参数,但攻击者仍能与机器学习的系统有所交互,比如可以通过传入任意输入观察输出,判断输出。
应该说到目前为止机器学习模型是最好的预防风险的一种手段,几乎接近完美,不过就像上文说的,攻击者如果进行细微的数据修改则一样可以发起攻击。
下面就以Inception v3为例,介绍一下如何使用白盒模型来攻击Google的Inception v3 ImageNet分类器:
我使用谷歌Inception v3作为目标图像识别模型,并选取ImageNet中的50000个验证图像针对Inception v3构造出相对应的对抗性图像。在实验中,将所有的对抗性图片和原始图片都打印出来,并手动用一个Nexus 5智能手机进行拍照,然后将手机里的图像输入Inception v3模型进行识别。现场结果表明,87%的对抗性图像在经过外界环境转化后仍能成功欺骗机器。
你可以将经过训练的神经网络看作一组单元格,而同一单元格利的每个点(比如本文中就代表图像)都与同一个类相关联。不过,这些单元格过度线性化,就很容易对细微的变化不敏感,而攻击者恰恰是抓住了这一点。
理想情况下,每次对抗攻击都对应一个经过修改的输入,其背后的原理就是为图像的每一个类进行一次细微的干扰。在本文中,我会将原始图像称为“Source”,将我添加的干扰称为“Noise”。
那现在,我所需要的如何从初始点(Source)移动这些图片的粒度。
对抗性图像攻击是攻击者构造一张对抗性图像,使人眼和图像识别机器识别的类型不同。比如攻击者可以针对使用图像识别的无人车,构造出一个图片,在人眼看来是一个停车标志,但是在汽车看来是一个限速60的标志。
逐步分解对抗过程
使用快速梯度逐步算法(Fast Gradient Step Method ,FGSM)可以分解对抗过程。这个方法的关键就是在每一步分析的过程中加入少量Noise,让预测结果朝目标类别偏移。有时候我需要限制Noise的振幅以使得攻击更加隐蔽, 一方被反侦察。在本文中,Noise的振幅意味着像素通道的强度,这意味着限制振幅可以确保Noise几乎无法察觉,最理想的情况就是,经过Noise的图片看起来仅像一个压缩的jpeg文件。
应该说是一个纯粹的最优化问题,不过在本文中,我优化Noise强度的目的是为了使攻击最大化。由于你可以获取神经网络的原始输出信息, 所以你可以直接测量误差以及计算梯度。
但如果你没有完整的原始输出信息怎么办,比如你只有一个分类结果,这就是黑客攻击模型。
这时,你要做的就是从相同的方向进行Noise。首先你需要生成Noise并加到图片上, 然后将图片输入分类器, 并不断重复这个过程直到机器出错。不管你是否限制Noise强度的大小,重复到某个时刻,你都不会再看到正确的分类结果。此时你需要做的事就是找到能得到相同错误结果的最弱Noise,用一个简单的二分搜索就可以做到。
让我来看看为什么这个方法可行。由于图片空间由不同横截面构成,所以重要的是你要向哪个方向移动,根据FGSM的定义,是要沿梯度方向逐步移动的,FGSM会使你移动到真实类别和某个错误类别的边界上, 如下图所示就是一个对抗方向和随机方向的横截面图集,横坐标是快速梯度方向即对抗方向,纵坐标是垂直梯度方向的随机值代表随机方向:
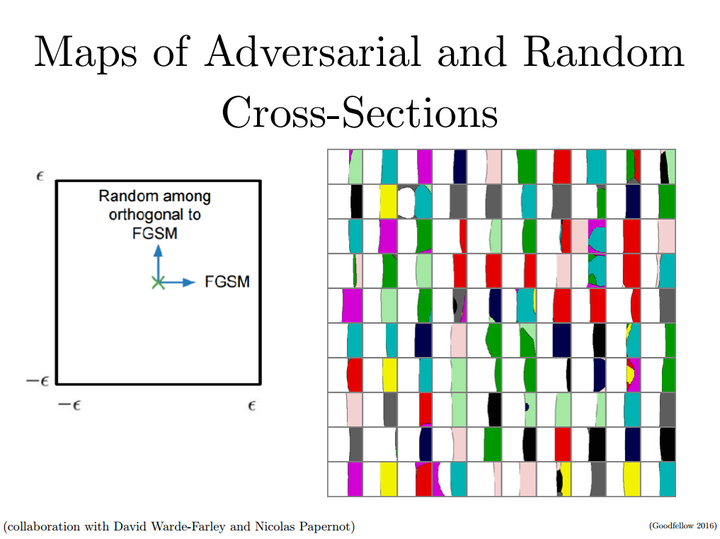
由于边界几乎是线性的,所以并无固定的“真”“假”之分,这样我就从中得到两个结论:
一方面,如果你沿着梯度的方向进行计算, 一旦碰到了预测的类别改变的区域, 就可以确认攻击成功了。
另一方面,决策函数的结构远比大多数研究者想象的容易。
由于这个方法简单实用,如果没有对应的防护措施,这个方法几乎可以攻击所有的机器学习算法。
下面就让我来执行一个黑盒攻击

让跑车秒变面包机
在这个测试中,我将使用PyTorch和torchvision包中的预训练分类器Inception_v3模型。
首先,我需要选择一组图像,将它转化为对抗样本。为了简单方便起见,我将使用NIPS 2017对抗攻击挑战赛中的数据集(development set),点此下载所有的脚本:
import torch
from torch import nn
from torch.autograd import Variable
from torch.autograd.gradcheck import zero_gradients
import torchvision.transforms as T
from torchvision.models.inception import inception_v3
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
定义主要的设置,并初始化神经网络:
classes = eval(open('classes.txt').read())
trans = T.Compose([T.ToTensor(), T.Lambda(lambda t: t.unsqueeze(0))])
reverse_trans = lambda x: np.asarray(T.ToPILImage()(x))
现在,我除了将PIL(Python Imaging Library)图片转换为Torch张量,还需要输出numpy矩阵的反向转换,这样是为了重新转化为一张图片。
eps = 2 * 8 / 225.
steps = 40
norm = float('inf')
step_alpha = 0.0001
model = inception_v3(pretrained=True, transform_input=True).cuda()
loss = nn.CrossEntropyLoss()
model.eval();
由于这是一个预训练神经网络,所以本文中的所有操作都是在GPU上运行的,如果你不想使用GPU,只需要将代码中所有的“.cuda()”调用和“.cpu()”调用删除即可。
除此之外,我还定义了一个损失函数(Loss Function),之后会在此基础上进行梯度下降。
为了使攻击更加隐蔽,我需要为添加的Noise做一些限制。比如将Noise的L-无限范数(即绝对值)限制在一定值,通过这种方法,图像就不会显得过亮或过暗,因为像素点数值的绝对值正代表了图片在某一RBG通道的亮度。
在编写攻击代码之前,让我先添加这个可以进行可视化的函数:
def load_image(img_path):
img = trans(Image.open(img_path).convert('RGB'))
return img
load_image简单清晰,我正在从磁盘读取图像,并将其转换为神经网络能接受的格式。
def get_class(img):
x = Variable(img, volatile=True).cuda()
cls = model(x).data.max(1)[1].cpu().numpy()[0]
return classes[cls]
默认情况下,分类器只给我一个类的数字标识,因为该方法既能完成统计推断,也能给出最可能的分类结果。
def draw_result(img, noise, adv_img):
fig, ax = plt.subplots(1, 3, figsize=(15, 10))
orig_class, attack_class = get_class(img), get_class(adv_img)
ax[0].imshow(reverse_trans(img[0]))
ax[0].set_title('Original image: {}'.format(orig_class.split(',')[0]))
ax[1].imshow(noise[0].cpu().numpy().transpose(1, 2, 0))
ax[1].set_title('Attacking noise')
ax[2].imshow(reverse_trans(adv_img[0]))
ax[2].set_title('Adversarial example: {}'.format(attack_class))
for i in range(3):
ax[i].set_axis_off()
plt.tight_layout()
plt.show()
所以,我的FGSM攻击将取决于三个参数:
1.最大强度(这不应超过16),
2.梯度步数,
3.步长。
经过一系列繁琐的试验后,我将梯度步数限制在了10-20,将步长定为0.001。之所以不把步长设置的太大,就是保持结果的稳定。这个过程和普通梯度下降是一样的。
def non_targeted_attack(img):
img = img.cuda()
label = torch.zeros(1, 1).cuda()
x, y = Variable(img, requires_grad=True), Variable(label)
for step in range(steps):
zero_gradients(x)
out = model(x)
y.data = out.data.max(1)[1]
_loss = loss(out, y)
_loss.backward()
normed_grad = step_alpha * torch.sign(x.grad.data)
step_adv = x.data + normed_grad
adv = step_adv - img
adv = torch.clamp(adv, -eps, eps)
result = img + adv
result = torch.clamp(result, 0.0, 1.0)
x.data = result
return result.cpu(), adv.cpu()
通过对原始图像进行修改,分类器对图像的判断也会越来越不靠谱。这可以通过两个“维度”中的细化程度来决定:
1.我用参数eps控制Noise的幅度,参数越小,输出图片的变动也就越小。
2.我通过参数step_alpha来控制攻击的稳定性,如果把它设置得太高,很可能会找不到损失函数的极值点。
如果我不限制攻击的幅度,结果则可能类似于目标类中的平均图像,如下所示:

在所有的实验中,使用最小的eps也有很好的对抗结果,很小的改动就能让分类器犯错。为了证明这点,我会将Noise调大。
img = load_image('input.png')
adv_img, noise = non_targeted_attack(img)
draw_result(img, noise, adv_img)

如果我想要神经网络输出某个特定的类别怎么办?很简单,只需要对攻击代码做一些小调整就可以了:
def targeted_attack(img, label):
img = img.cuda()
label = torch.Tensor([label]).long().cuda()
x, y = Variable(img, requires_grad=True), Variable(label)
for step in range(steps):
zero_gradients(x)
out = model(x)
_loss = loss(out, y)
_loss.backward()
normed_grad = step_alpha * torch.sign(x.grad.data)
step_adv = x.data - normed_grad
adv = step_adv - img
adv = torch.clamp(adv, -eps, eps)
result = img + adv
result = torch.clamp(result, 0.0, 1.0)
x.data = result
return result.cpu(), adv.cpu()
这里最主要的改变是梯度符号的改变。在黑客攻击不同,在白盒攻击中,我会假设目标模型总是正确的,实现偏差最小化。
step_adv = x.data - normed_grad
对Google的FaceNet进行对抗攻击
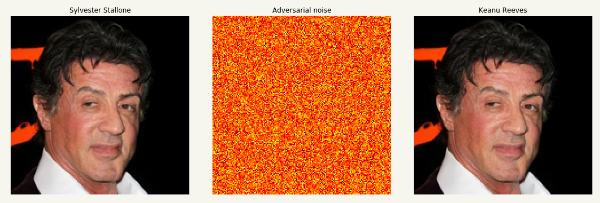
本文中,FaceNet是一个拥有密集层(dense layer)的Inception_v3特征提取器,可以识别图片中的人。我采用户外脸部检测数据集(Labeled Faces in the Wild,LFW)来进行测试,Inception_v3的扩展网络与另一个分类器结合一起,使用LFW数据集的500张最常见的人脸进行训练。

攻击的目标是使数据集中每一个人都被分到“Keanu Reeves”这一类,由于图片很多,我可以把攻击设置成只要一次攻击成果,攻击即可停止。实际攻击中,该停止攻击方法可以显著提高运行速度,如下图所示的攻击过程中,分类损失函数值会随着梯度下降步数逐渐减小。
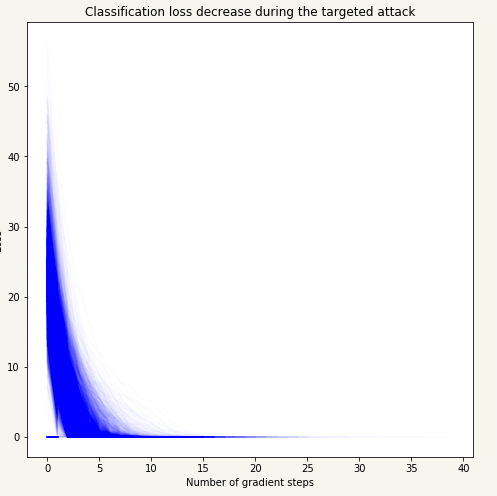
既然最优化问题这么容易解决,我就可以很容易推断边界是个很简单的函数,很可能是线性函数。
这意味着,第一,神经网络中的类相距很近。第二,如果你仅仅输入一些随机Noise,分类器仍会输出一些预测结果,这并不总是一件好事。
如下图所示:
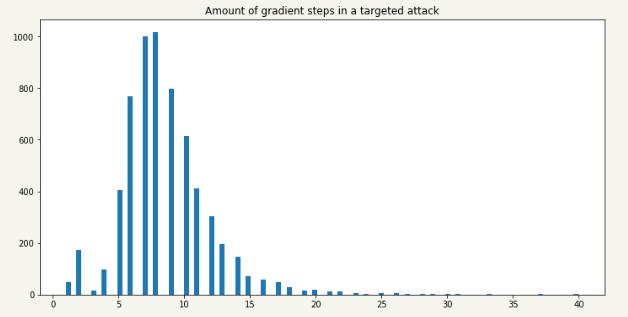
振幅降低的Noise使得原图和修改后的图片用肉眼无法分辨:
防御策略
黑盒攻击防御策略:训练其他的分类器来检测对抗输入。
白盒攻击防御策略:实行对抗训练程序。
黑盒攻击防御策略不仅可以帮助防止过度拟合,让分类器的鲁棒性变强,还可以让你的模型加速收敛。但是根据最近的研究结果,这也不能消除所有对抗攻击带来的问题。而且,增加一个分类器也会大大降低分类效率,实现这两个分类器也要求你具备更多GANs的经验,因此这种解决方案都不是最优的。
如何在分类器上实行对抗训练
未来研究者很可能训练出一个不仅能预测对抗标签,还能辨别你是不是在实施欺骗的神经网络。
本文翻译自: http://blog.ycombinator.com/how-adversarial-attacks-work/ ,如若转载,请注明原文地址: http://www.4hou.com/vulnerable/8322.html 更多内容请关注“嘶吼专业版”——Pro4hou