[root@master-1] ~$ top
top - 09:57:41 up 7:49, 2 users, load average: 15.03, 14.70, 14.30
Tasks: 161 total, 6 running, 138 sleeping, 0 stopped, 17 zombie
%Cpu(s): 3.1 us, 53.1 sy, 0.0 ni, 43.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 7493208 total, 3311120 free, 953128 used, 3228960 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 5216800 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
30821 root 20 0 159932 2208 1496 R 6.2 0.0 0:00.01 top
1 root 20 0 128300 6860 4176 D 0.0 0.1 0:43.39 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.01 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:18.12 ksoftirqd/0
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
7 root rt 0 0 0 0 S 0.0 0.0 3:30.43 migration/0
8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh
9 root 20 0 0 0 0 S 0.0 0.0 0:31.71 rcu_sched
10 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 lru-add-drain 常用操作
P:cpu排序
M:内存排序
c:显示完整命令
1、只查看某一个进程的top参数:
top -p pid (pid可以通过pidof命令获取,如pidof falcon-agent ,注意java进程的pid此命令无法获取)
2、top默认显示的所有CPU的平均值,这个时候只需要按下数字1,就可以切换到每个CPU的使用率了。
3、中括号表示这个进程不是使用命令行启动的。这种进程一般是内核进程
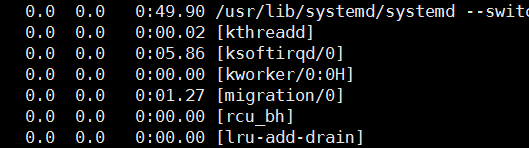
4、关于command的数字的解释
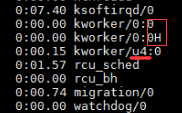
command中k开头的这些由Linux内核创建的工作线程的命名规则是这样的:
kworker/cpu_id:thread_id 。也就是说第一个数字是cpu编号,第二个数字是线程编号或者work_pool工人集合中某个工人的序号ID
u:是unbound的缩写
不带u的就是绑定特定cpu,带着u代表没有绑定特定的CPU
H表示该线程的nice小于0,说明它的优先级很高,所以加了H
https://www.cnblogs.com/embedded-linux/p/8538569.html
关于线程编号的问题,与linux内核的工作队列workqueue有关系
在多核环境里,我们能见到的,CPU使用率的问题,大多是每个CPU的使用率都比较高。进程调度算法的一个最主要目标,就是保证不会有有的人撑死,有的人饿死的情况发生。能影响这种“公平性”的因素有两个,一个是优先级(priority),另外一个是相关性(affinity)。优先级处理的是进程之间,哪个比较重要的问题;相关性处理的是进程需要某一个CPU专门负责的问题。
相关性会引起“闲里偷忙”这种问题是显而易见的。如果一个进程被绑定到某一个CPU,那么如果这个进程持续的做计算,势必会让这一个CPU占用率变高。当前这个问题属于这一类。至于优先级和这类问题的关联,不是那么明显。优先级在一些特殊的状况下,会制造类似的麻烦,有机会我会借助例子来分析。
工作队列
相信观察仔细的同学,会发现第一张图里,kworker进程名字后边跟了24:2这样的标识。这个和大多数其他进程是不一样的。我们先从这两个数字背后的机制,工作队列说起。
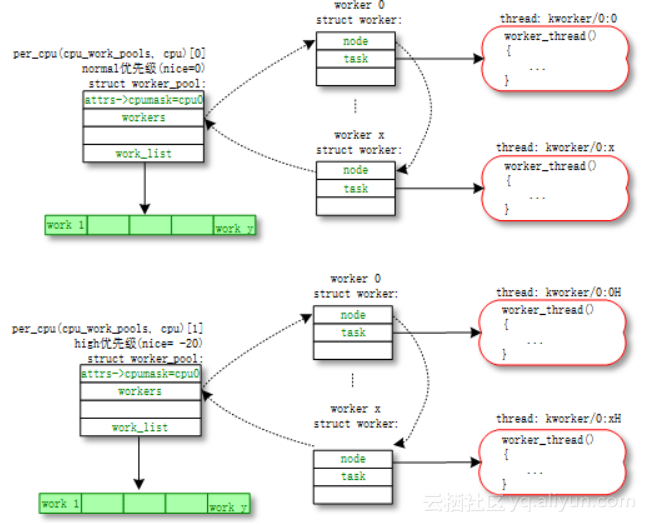
关于工作队列(work queue),这边有五个核心的概念,分别是工作(work,也就是需要做的事情,分装一个函数),工作池(work pool,工作需要一个一个处理,这是一个工作的集合),工人(worker,实现为内核进程),工人小组(worker pool,工人小团队)以及第五个概念,中介。中介是把工作队列和工人小组联系起来的纽带。工作队列这个机制,是为了保证,每一个work,从被放在工作池里,然后经过中介的手,分配给某一个工人小组的某一个工人去处理,这一切都能高效有序的进行。
对每个CPU,系统会创建两个的工作小组,普通优先级组,和高优先级组。系统会根据工作多少,动态管理每个工人小组里,工人的数量。下边是从网上拿的一张图,这张图对应一个CPU的(普通优先级在上、高优先级在下)两个工作小组。我们可以看到,每个worker被实现为一个kworker进程。而kworker后边的两个数字,大家应该可以猜到,第一个代表的是CPU的编号,第二个代表着一个工人在工人小组里的编号。当前这个问题中,kworker是第24个CPU的第2个worker。这也是为什么,在第二张图里,第24个CPU的系统使用率高的。
备注:关于工作队列,我这里其实省略了很多细节,而且work pool这个概念是不存在的,它原本是work queue,为了区分这个概念,和工作队列这个机制本身,我稍微修改了一下。
https://yq.aliyun.com/articles/504369?spm=a2c4e.11155435.0.0.28b06a95Zkd8RM

5、想以进程名来查看的话,比方说我想查进程名称是python的,下面的命令会显示所以command为python的进程的进程号,并换行显示。然后用top -p pid来看
pgrep python想查进程名是以k开头的内核进程,如下。注意top -p进程号的时候,最多指定20个进程号
top -p `pgrep ^k |head -n 20| tr "\\n" "," | sed 's/,$//'`
参数说明
us:user CPU time, 用户空间占用CPU百分比。注意,它不包括下面的 nice 时间,但包括了 guest 时间。为啥不包括见ni的解释。
sy:system CPU time 内核空间占用CPU百分比
用户空间和内核空间是什么?
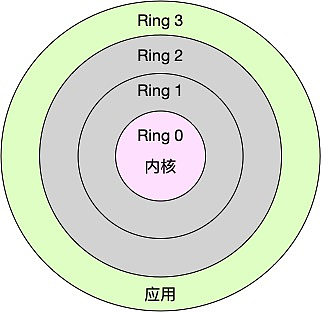
Linux按照特权等级,把进程的运行空间分为内核空间和用户空间,分别对应着下图中,CPU特权等级的Ring 0和Ring 3。
内核空间(Ring 0)具有最高权限,可以直接访问所有资源;
用户空间(Ring 3)只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调用陷入到内核中,才能访问这些特权资源。
换个角度看,也就是说,进程既可以在用户空间运行,又可以在内核空间中运行。进程在用户空间运行时,被称为进程的用户态,而陷入内核空间的时候,被称为进程的内核态。
从用户态到内核态的转变,需要通过系统调用来完成。比如,当我们查看文件内容时,就需要多次系统调用来完成:首先调用open()打开文件,然后调用read()读取文件内容,并调用write()将内容写到标准输出,最后再调用close() 关闭文件。
hi:hardware irq(Interrupt Request),硬中断消耗cpu时间
si:software irq(Interrupt Request)软中断消耗cpu时间
中断是什么?
先打个比方。当一个经理正处理文件时,电话铃响了(中断请求),不得不在文件上做一个记号(返 回地址),暂停工作,去接电话(中断),并指示“按第二方案办”(调中断服务程序),然后,再静下心来(恢复中 断前状态),接着处理文件……。
从概念上讲:中断是CPU处理外部突发事件的一个重要技术。它能使CPU在运行过程中对外部事件发出的中断请求及时地进行处理, 处理完成后又立即返回断点,继续进行CPU原来的工作。
如果程序都没什么问题,那么是没有hi和si的,但是实际上有个硬中断和软中断的概念。比如硬中断,cpu在执行程序的时候,突然外设硬件(比如硬盘出现问题了)机器需要立刻通知cpu进行现场保存工作。这个时候会cpu会出现上下文切换。就是cpu会有一部分时间会被硬中断占用了,这个时间就是hi。相类似,si是软中断的cpu占用时间,软中断是由软件的指令方式触发的。IO密集型系统,无论是网络IO还是磁盘IO,一般都会产生大量的中断,从而导致%sys相对升高,其中磁盘IO密集型系统,对磁盘的读写需要占用大量的CPU,会导致%iowait的值一定比例的升高
-----------------
什么是中断
中断是系统用来响应硬件设备请求的一种机制,它会打断进程的正常调度和执行,然后调用内核中的中断处理程序来响应设备的请求。
软中断就比如说你订了一份外卖,但是不确定外卖什么时候送到,也没有别的方法了解外卖的进度,但是,配送员送外卖是不等人的,到了你这儿没人取的话,就直接走人了。所以你只能苦苦等着,时不时去门口看看外卖送到没,而不能干其他事情。
不过呢,如果在订外卖的时候,你就跟配送员约定好,让他送到后给你打个电话,那你就不用苦苦等待了,就可以去忙别的事情,直到电话一响,接电话、取外卖就可以了。 这里的“打电话”,其实就是一个中断。没接到电话的时候,你可以做其他的事情;只有接到了电话(也就是发生中断),你才要进行另一个动作:取外卖。
中断其实是一种异步的事件处理机制,可以提高系统的并发处理能力。
由于中断处理程序会打断其他进程的运行,所以,为了减少对正常进程运行调度的影响,中断处理程序就需要尽可能快地运行。如果中断本身要做的事情不多,那么处理起来也不会有太大问题;但如果中断要处理的事情很多,中断服务程序就有可能要运行很长时间。
中断处理程序在响应中断时,还会临时关闭中断。这就会导致上一次中断处理完成之前,其他中断都不能响应,也就是说中断有可能会丢失。
那么还是以取外卖为例。假如你订了 2 份外卖,一份主食和一份饮料,并且是由 2 个不同的配送员来配送。这次你不用时时等待着,两份外卖都约定了电话取外卖的方式。
但是,问题又来了。 当第一份外卖送到时,配送员给你打了个长长的电话,商量发票的处理方式。与此同时,第二个配送员也到了,也想给你打电话。 但是很明显,因为电话占线(也就是关闭了中断响应),第二个配送员的电话是打不通的。所以,第二个配送员很可能试几次后就走掉了(也就是丢失了一次中断)
什么是软中断
Linux 中的软中断包括网络收发、定时、调度、RCU 锁等各种类型,可以通过查看 /proc/softirqs 来观察软中断的运行情况。
为了解决中断处理程序执行过长和中断丢失的问题,Linux 将中断处理过程分成了两个阶段,也就是上半部和下半部:
上半部用来快速处理中断, 它在中断禁止模式下运行,主要处理跟硬件紧密相关的或时间敏感的工作。
下半部用来延迟处理上半部未完成的工作,通常以内核线程的方式运行。
举个例子
网卡接收到数据包后,会通过硬件中断的方式,通知内核有新的数据到了。这时,内核就应该调用中断处理程序来响应它。你可以自己先想一下,这种情况下的上半部和下半部分别负责什么工作呢?
对.上半部来说,既然是快速处理,其实就是要把网卡的数据读到内存中,然后更新一下硬件寄存器的状态(表示数据已经读好了),最后再发送一个软中断信号,通知下半部做进-步的处理。
而下半部被软中断信号唤醒后,需要从内存中找到网络数据,再按照网络协议栈,对数据进行逐层解析和处理,直到把它送给应用程序。
所以,这两个阶段你也可以这样理解:
上半部直接处理硬件请求,也就是我们常说的硬中断,特点是快速执行;
而下半部则是由内核触发,也就是我们常说的软中断,特点是延迟执行。
实际上,. 上半部会打断CPU正在执行的任务,然后立即执行中断处理程序。而下半部以内核线程的方式执行,并且每个CPU都对应一个软中断内核线程,名字为“ksoftirqd/CPU编号”,比如说,0号CPU对应的软中断内核线程的名字就是ksoftirqd/0。
不过要注意的是,软中断不只包括了刚刚所讲的硬件设备中断处理程序的下半部,一些内核自定义的事件也属于软中断,比如内核调度和 RCU 锁(Read-Copy Update 的缩写,RCU 是 Linux 内核中最常用的锁之一)等。
查看软中断和内核线程
/proc/softirqs 提供了软中断的运行情况
/proc/interrupts 提供了硬中断的运行情况。
查看/proc/ softirqs文件内容时,特别注意以下这两点。
第一,要注意软中断的类型,也就是这个界面中第- -列的内容。从第一列你可以看到, 软中断包括了10个类别,分别对应不同的工作类型。比如NET_ RX表示网络接收中断,而NET_TX表示网络发送中断。
第二,要注意同一种软中断在不同CPU上的分布情况,也就是同- -行的内容。正常情况下,同一种中断在不同CPU.上的累积次数应该差不多。比如这个界面中,NET_ _RX在CPU0和CPU1上的中断次数基本是同一个数量级,相差不大。
TASKLET 在不同CPU.上的分布并不均匀。TASKLET是最常用的软中断实现机制,每个TASKL ET只运行一次就会结束,并且只在调用它的函数所在的CPU上运行。
因此,使用TASKLET特别简便,当然也会存在一些问题,比如说由于只在一个CPU上运行导致的调度不均衡,再比如因为不能在多个CPU上并行运行带来了性能限制。
ni: nice CPU time,nice值代表一个进程使用Cpu资源的优先程度。nice 可取值范围是 -20 到 19。nice值越高,优先级就越低。ni这个指标,统计的是系统中,所有nice值大于0的用户空间进程的Cpu的使用率。也就是nice 值被调整为 1-19 之间的进程 CPU使用率之和。
一般情况下进程默认的nice值是0,而当有些进程需要更高的执行优先级的时候,我们会减小这些进程的nice值。当然有一些并不需要在高优先级运行的进程,例如我们跑编译程序gcc,去编译一个内核,这个操作预计会花几个小时,那么我们可以增加这个gcc进程的nice值。
linux会把真正的用户模式Cpu使用率拆分成两部分显示,nice值大于0的显示为ni(所以也叫低优先级用户态 CPU 时间),小于等于0的显示为us。
nice值是什么
每个linux进程都有个优先级,优先级高的进程有优先执行的权利,这个叫做pr(进程创建时根据进程所需的资源多少,将要运行的时间长短,进程是什么类型{io/cpu,前台/后台,核心/用户}来确定的一个静态优先级)。进程除了优先级外,还有个优先级的修正值,这就是ni(nice),这个是动态的优先级,当进程使用cpu超过一定时长,或者进程等待一定时长时等等,此时系统会自动分配一个修正值,来改变进程的优先级,除了系统自动分配之外,也可以在手动通过
renice +19 -p $pid命令来指定。 即比如你原先的优先级pr是20,然后修正值ni为-2,那么你最后的进程优先级为18。从20到18,这个进程的优先级被提高了。ni表示的就是被提高优先级的这些用户空间进程(注意有个空户空间)所占用的cpu百分比。那么nice是一个进程的优先级修正值,为什么会占用cpu时间呢?ni是指用做nice加权的进程使用的用户态cpu时间比,我的理解就是一个进程的所谓修正值就意味着多分配一些cpu时间给这个进程的用户态,这个中间所多分配的cpu时间就是我们这里的ni。(这个理解没啥把握,如果有错误麻烦帮忙指出下)
wa:iowait,CPU等待io的时间
就是说前提是要进行IO操作,在进行IO操作的时候,CPU等待时间。比如上面那个程序,最后一步,从系统空间到dst硬盘空间的时候,如果程序是阻塞的,那么这个时候cpu就要等待数据写入磁盘才能完成写操作了。所以这个时候cpu等待的时间就是wa。所以如果一台机器看到wa特别高,那么一般说明是磁盘IO出现问题,可以使用iostat等命令继续进行详细分析。
st: steal time,只对虚拟机有效,当系统运行在虚拟机中的时候,被其他虚拟机占用的 CPU 时间。
id: idle,空闲时间,注意,它不包括等待 I/O 的时间(iowait)。
guest:通过虚拟化运行其他操作系统的时间,也就是运行虚拟机的 CPU 时间。
gnice:以低优先级运行虚拟机的时间。
switches: 上下文切换,意思是 CPU 从一个进程或线程切换到另一个进程或线程
问题
多个进程之间竞争 CPU 的时候并没有真正运行,为什么会导致负载升高?
原因就是 CPU 上下文切换
什么是 CPU 上下文切换
Linux 是一个多任务操作系统,它支持远大于 CPU 数量的任务同时运行。当然,这些任务实际上并不是真的在同时运行,而是因为系统在很短的时间内,将 CPU 轮流分配给它们,造成多任务同时运行的错觉。
而在每个任务运行前,CPU 都需要知道任务从哪里加载、又从哪里开始运行,也就是说,需要系统事先帮它设置好 CPU 寄存器和程序计数器(Program Counter,PC)。
CPU 寄存器,是 CPU 内置的容量小、但速度极快的内存。而程序计数器,则是用来存储 CPU 正在执行的指令位置、或者即将执行的下一条指令位置。它们都是 CPU 在运行任何任务前,必须的依赖环境,因此也被叫做 CPU 上下文。
上下文切换 就是先把前一个任务的 CPU 上线保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指定的新位置,运行任务。而这些保存起来的上下文,会存储在系统内核中,并在任务重新调度执行时再次加载。这样就能保证任务原来的状态不受影响,让任务看起来是连续的。
根据任务的不同,CPU 的上下文切换就可以分为几个不同的场景,也就是 进程上下文切换,线程上下文切换,以及中断上下文切换。
系统调用过程中也会发生上下文切换
CPU寄存器里原来用户态的指令位置,需要先保存起来。接着,为了执行内核态代码,CPU寄存器需要更新为内核态指令的新位置。最后才是跳转到内核态运行内核任务。
而系统调用结束后,CPU寄存器需要恢复原来保存的用户态,然后再切换到用户空间,继续运行进程。所以,一次系统调用的过程,其实是发生了两次CPU上下文切换。
系统调用过程中,并不会涉及到虚拟内存等进程用户态的资源,也不会切换进程。
和进程上下文切换是不一样的:
进程上下文切换,是指从一个进程切换到另一个进程运行。
而系统调用过程中一直是同一个进程在运行。
系统调用过程通常称为特权模式切换,而不是上下文切换。但实际上,系统调用过程中,CPU的上下文切换还是无法避免的。
进程上下文切换跟系统调用又有什么区别呢?
进程是由内核来管理和调度的,进程的切换只能发生在内核态。
进程的上下文不仅包括了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态,。CPU 寄存器里原来用户态的指令位置,需要先保存起来。接着,为了执行内核态代码,CPU 寄存器需要更新为内核态指令的新位置。最后才是跳转到内核态运行内核任务。
进程的上下文切换就比系统调用时多了一步:在保存当前进程的内核状态和 CPU 寄存器之前,需要先把该进程的虚拟内存、栈等保存下来;而加载了下一进程的内核态后,还需要刷新进程的虚拟内存和用户栈。
如下图所示,保存上下文和恢复上下文的过程并不是“免费”的,需要内核在 CPU 上运行才能完成。
进程上下文切换的潜在性能问题
根据 Tsuna 的测试报告,每次上下文切换都需要几十纳秒到数微秒的 CPU 时间。这个时间还是相当可观的,特别是在进程上下文切换次数较多的情况下,很容易导致 CPU 将大量时间耗费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,进而大大缩短了真正运行进程的时间。这也正是导致平均负载升高的一个重要因素。
另外,我们知道, Linux 通过 TLB(Translation Lookaside Buffer)来管理虚拟内存到物理内存的映射关系。当虚拟内存更新后,TLB 也需要刷新,内存的访问也会随之变慢。特别是在多处理器系统上,缓存是被多个处理器共享的,刷新缓存不仅会影响当前处理器的进程,还会影响共享缓存的其他处理器的进程。
发生进程上下文切换的场景
1.为了保证所有进程可以得到公平调度,CPU 时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。这样,当某个进程的时间片耗尽了,就会被系统挂起,切换到其它正在等待 CPU 的进程运行。
2.进程在系统资源不足(比如内存不足)时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行。
3.当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度。
4.当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行
5.发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序。
线程上下文切换
线程与进程最大的区别在于:线程是调度的基本单位,而进程则是资源拥有的基本单位。说白了,所谓内核中的任务调度,实际上的调度对象是线程;而进程只是给线程提供了虚拟内存、全局变量等资源。
所以,对于线程和进程,我们可以这么理解:
- 当进程只有一个线程时,可以认为进程就等于线程。
- 当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源。这些资源在上下文切换时是不需要修改的。
- 另外,线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存的。
发生线程上下文切换的场景
- 前后两个线程属于不同进程。此时,因为资源不共享,所以切换过程就跟进程上下文切换是一样。
- 前后两个线程属于同一个进程。此时,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据
中断上下文切换
为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。而在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行。
跟进程上下文不同,中断上下文切换并不涉及到进程的用户态。所以,即便中断过程打断了一个正处在用户态的进程,也不需要保存和恢复这个进程的虚拟内存、全局变量等用户态资源。中断上下文,其实只包括内核态中断服务程序执行所必需的状态,包括 CPU 寄存器、内核堆栈、硬件中断参数等。
对同一个 CPU 来说,中断处理比进程拥有更高的优先级,所以中断上下文切换并不会与进程上下文切换同时发生。同样道理,由于中断会打断正常进程的调度和执行,所以大部分中断处理程序都短小精悍,以便尽可能快的执行结束。
另外,跟进程上下文切换一样,中断上下文切换也需要消耗 CPU,切换次数过多也会耗费大量的 CPU,甚至严重降低系统的整体性能。所以,当你发现中断次数过多时,就需要注意去排查它是否会给你的系统带来严重的性能问题。
如何查看系统上下文切换情况
vmstat 是一个常用的系统性能分析工具,主要用来分析系统的内存使用情况,也常用来分析 CPU 上下文切换和中断的次数。
root@linux:~# vmstat 5 #表示每5秒输出一组数据 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 5908100 98072 2064032 0 0 4 267 101 190 7 1 91 1 0我们一起来看这个结果,你可以先试着自己解读每列的含义。在这里,我重点强调下,需要特别关注的四列内容:
cs (context switch) 是每秒.上下文切换的次数。
in (interrupt) 则是每秒中断的次数。
r(Running or Runnable) 是就绪队列的长度,也就是正在运行和等待CPU的进程数。
b (Blocked) 则是处于不可中断睡眠状态的进程数。
可以看到,这个例子中的上下文切换次数cs是190次,而系统中断次数in则是101次,而就绪队列长度r和不可中断状态进程数b都是0。
vmstat只给出了系统总体的.上下文切换情况,要想查看每个进程的详细情况,就需要使用我们前面提到过的pidstat了。给它加上-w选项,你就可以查看每个进程上下文切换的情况了。
root@linux:~/sysstat/sysstat# ./pidstat -w 5 # 5秒输出一组数据 Linux 4.4.0-21-generic (linux) 03/26/19 _x86_64_ (4 CPU) 17:21:19 UID PID cswch/s nvcswch/s Command 17:21:24 0 7 2.00 0.00 rcu_sched 17:21:24 0 10 0.20 0.00 watchdog/0这个结果中有两列内容是我们的重点关注对象。一个是 cswch ,表示每秒自愿上下文切换(voluntary context switches)的次数,另一个则是 nvcswch ,表示每秒非自愿上下文切换(non voluntary context switches)的次数。
所谓
自愿上下文切换,是指进程无法获取所需资源,导致的上下文切换。比如说, I/O、内存等系统资源不足时,就会发生自愿上下文切换。 而非自愿上下文切换,则是指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。比如说,大量进程都在争抢 CPU 时,就容易发生非自愿上下文切换。上下文切换多少合适
这个数值其实取决于系统本身的 CPU 性能。如果系统的上下文切换次数比较稳定,那么从数百到一万以内,都应该算是正常的。但当上下文切换次数超过一万次,或者切换次数出现数量级的增长时,就很可能已经出现了性能问题。 这时,你还需要根据上下文切换的类型,再做具体分析。
比方说:
- 自愿上下文切换变多了,说明进程都在等待资源,有可能发生了 I/O 等其他问题;
- 非自愿上下文切换变多了,说明进程都在被强制调度,也就是都在争抢 CPU,说明 CPU 的确成了瓶颈;
- 中断次数变多了,说明 CPU 被中断处理程序占用,还需要通过查看 /proc/interrupts 文件来分析具体的中断类型。
本文整理自极客时间:《Linux性能优化实战》

第三行的 cpu指标相加应该是100%。
即:总得cpu使用率 =%usr + %nice + %sys+ %iowait+ %irq + %soft + %steal + %idle
而我们通常所说的CPU使用率,就是除了空闲时间(idle+iowait)外的其他时间占总CPU时间的百分比
上面这个计算方式是不具备参考意义的,因为总CPU时间是机器开机以来的,事实上,为了计算CPU使用率,性能工具都会取间隔一段时间(比如5秒)的两次值,做差后,再计算出这段时间内的平均CPU使用率
这个公式,就是我们用各种性能工具所看到的 CPU 使用率的实际计算方法。
Linux 也给每个进程提供了运行情况的统计信息,也就是 /proc/[pid]/stat。不过,这个文件包含的数据就比较丰富了,总共有 52 列的数据。
不过需要注意的是,性能分析工具给出的都是间隔一段时间的平均CPU使用率,所以要注意间隔时间的设置,特别是多个工具对比分析时,需要保证它们的间隔时间是相同的。
比如,对比一下top和ps这两个工具报告的CPU使用率,默认的结果可能不一样,因为top默认使用3秒时间间隔,而ps使用的却是进程的整个生命周期。
进程相关
PR:进程的优先级别,由 OS 内核动态调整,用户不能改变,越小优先级越高。取值0-139
NI:nice值。nice值是每个进程的一个属性。它不是进程的优先级,而是一个能影响优先级的数字。
nice是-20~~19之间的整数,默认取中间值0。
用户可以通过renice命令自行调整,负值表示高优先级,正值表示低优先级
ni是nice的意思,nice是什么呢,每个linux进程都有个优先级,优先级高的进程有优先执行的权利,这个叫做pri。进程除了优先级外,还有个优先级的修正值。即比如你原先的优先级是20,然后修正值为-2,那么你最后的进程优先级为18。这个修正值就是nice,这个值为负值且越小 就说明进程的优先级会被提高的越多。
静态优先级:(定义在进程描述符中的:static_prio)
动态优先级:(定义在进程描述符中的:prio)
实时优先级:(定义在进程描述符中的:rt_priority)
静态优先级:
定义:他不随时间改变,内核不会主动修改它,只能通过系统调用nice去修改static_prio
动态优先级:
定义:调度程序通过或减少进程静态优先级来奖励IO消耗型进程或惩罚CPU消耗进程,调整后的优先级为动态优先级(prio)
实时优先级:
实时优先级只对实时进程有效
内存相关
VIRT:进程占用的虚拟内存,只要是进程申请过的内存,即便还没有真正分配物理内存,也会计算在内。
虚拟内存,包括了进程代码段、数据段、共享内存、已经申请的堆内存和已经换出的内存等。这里要注意,已经申请的内存,即使还没有分配物理内存,也算作虚拟内存。
RES:常驻内存的大小,也就是进程实际使用的物理内存大小,但不包括Swap和共享内存。
常驻内存一般会换算成占系统总内存的百分比,也就是进程的内存使用率
SHR:进程使用的共享内存,比如与其他进程共同使用的共享内存、加载的动态链接库以及程序的代码段等。
S:进程的状态。S表示休眠sleep,R表示正在运行running,Z表示僵死状态zombie,N表示该进程优先值为负数
%CPU:进程占用CPU的使用率,
%MEM:进程使用的物理内存与总内存的百分比
使用top 查看内存需要注意:
- 虚拟内存通常并不会全部分配给物理内存
- 共享内存 SHR 并不一定是共享,例如程序的代码段、非共享的动态链接库,也都算在 SHR 里。当然,SHR 也包括了进程间真正共享的内存。所以在计算多个进程的内存使用时,不要把所有进程的 SHR 直接相加得出结果。
TIME+:该进程启动后占用的总的CPU时间,即占用CPU使用时间的累加值。
意思就是你如果有多个CPU,或者是多核CPU的话,那么,进程占用多个cpu的时间是累加起来的。单位是1/100秒。比如3:30.43,从右到左分别是百分之一秒,十分之一秒,秒,十秒,分钟,拿这个说就是3分钟,30秒,0秒,十分之4秒,百分之3秒,是按位来计算的
进程四要素
- 有一段程序供其执行,就好一个演员要有个剧本一样。当然多个进程可以共用同一个剧本。
- 有起码的私有财产,这就是进程专用的系统(内核)空间堆栈。
- 有户口,这就是内核空间中的进程控制块task_struct结构。有了这个户口,内核才能看到它,对它实施调度。同时这个结构又是进程的财产登记卡,记录着进程所占用的各项资源。
- 有独立的用户空间,这就是mm_struct结构。该结构登记在进程的财产登记卡task_struct结构中,字段名称为mm。
进程状态
R:running or runnable (on run queue):表示进程在CPU的就绪队列中,正在运行或者正在等待运行
TASK_RUNNING 状态并不是表示一个进程正在运行,或者是这个进程就是“当前进程”,而是表示这个进程可被调度执行而成为当前进程,是进程表达了希望被调度运行的意愿。当进程处于此状态时,表示进程已经准备就绪或者可以被执行了,内核会将该进程的task_struct结构通过其队列头run_list链入一个“可执行队列”,至于最终调度运行谁,内核会根据调度策略从“可执行队列”中挑选一个进程来调度运行。
S :interruptible sleep (waiting for an event to complete),可中断的睡眠状态,表示进程由于等待某个进程而被系统挂起。当进程等待的事件发生时,它会被唤醒并进入 R 状态。
处在这种睡眠状态的进程是可以通过给它发信号来唤醒的,比如发HUP信号给nginx的master进程可以让nginx重新加载配置文件而不需要重新启动nginx进程。
通过ps命令我们会看到,一般情况下,进程列表中的绝大多数进程都处于s状态。毕竟CPU就这么一两个,进程动辄几十上百个,如果不是绝大多数进程都在睡眠,CPU又怎么响应得过来。
D :uninterruptible sleep (usually IO),不可中断的睡眠状态,一般表示进程正在跟硬件交互,并且过程不允许被其他进程或中断打断。会导致平均负载升高
为什么是简写是D,在内核源码 fs/proc/array.c 里,其文字定义为“ "D (disk sleep)", /* 2 */ ”
为了保护进程数据和硬件的一致性,系统不允许其他进程或中断打断这个进程。进程长时间处于不可中断状态,通常表示系统有 I/O 性能问题。
处于uninterruptible sleep状态的进程通常是在等待IO,比如磁盘IO,网络IO,其他外设IO,如果进程正在等待的IO在较长的时间内都没有响应,那么就很会不幸地被 ps看到了,同时也就意味着很有可能有IO出了问题,可能是外设本身出了故障,也可能是比如挂载的远程文件系统已经不可访问了,我这里遇到的问题就是由 down掉的NFS服务器引起的。
正是因为得不到IO的相应,进程才进入了uninterruptible sleep状态,所以要想使进程从uninterruptible sleep状态恢复,就得使进程等待的IO恢复,比如如果是因为从远程挂载的NFS卷不可访问导致进程进入uninterruptible sleep状态的,那么可以通过恢复该NFS卷的连接来使进程的IO请求得到满足,除此之外,要想干掉处在D状态进程就只能重启整个Linux系统了。
这种状态的进程还处于CPU 的run_queue 里,此时cpu 一般Load 很高。
T (stopped by job control signal),暂停状态或跟踪状态。
向进程发送一个SIGSTOP信号,它就会因响应该信号而进入TASK_STOPPED状态(除非该进程本身处于TASK_UNINTERRUPTIBLE状态而不响应信号)。
对于进程本身来说,TASK_STOPPED和TASK_TRACED状态很类似,都是表示进程暂停下来。
而TASK_TRACED状态相当于在TASK_STOPPED之上多了一层保护,处于TASK_TRACED状态的进程不能响应SIGCONT信号而被唤醒。只能等到调试进程退出,被调试的进程才能恢复TASK_RUNNING状态。
Z (zombie僵尸),僵尸状态,即进程实际上已经结束了,但父进程还没有回收它的资源(如:进程的描述符、PID等)
僵尸进程,是多进程应用很容易碰到的问题。正常情况下,当-一个进程创建了子进程后,它应该通过系统调用wait()或者waitpid()等待子进程结束,回收子进程的资源;而子进程在结束时,会向它的父进程发送SIGCHLD信号,所以,父进程还可以注册SIGCHL .D信号的处理函数,异步回收资源。
如果父进程没这么做,或是子进程执行太快,父进程还没来得及处理子进程状态,子进程就已经,提前退出,那这时的子进程就会变成僵尸进程。换句话说,父亲应该一直对儿子负责,善始善终,如果不作为或者跟不上,都会导致“问题少年”的出现。
通常,僵尸进程持续的时间都比较短,在父进程回收它的资源后就会消亡;或者在父进程退出后,由init进程回收后也会消亡。
一旦父进程没有处理子进程的终止,还一直保持运行状态,那么子进程就会一直处于僵尸状态。大量的僵尸进程会用尽 PID 进程号,导致新进程不能创建,所以这种情况一定要避免。
当子进程比父进程先结束,而父进程又没有回收子进程,释放子进程占用的资源,此时子进程将成为一个僵尸进程。如果父进程先退出 ,子进程被init接管,子进程退出后init会回收其占用的相关资源
进程在退出的过程中,处于TASK_DEAD状态。
在这个退出过程中,进程占有的所有资源将被回收,除了task_struct结构(以及少数资源)以外。于是进程就只剩下task_struct这么个空壳,故称为僵尸。
之所以保留task_struct,是因为task_struct里面保存了进程的退出码、以及一些统计信息。而其父进程很可能会关心这些信息。比如在shell中,$?变量就保存了最后一个退出的前台进程的退出码,而这个退出码往往被作为if语句的判断条件。
进程已经退出,但它的父进程还没有回收子进程占用的资源。短暂的僵尸状态我们通过不必理会,但进程长时间处于僵尸状态,就应该注意了,可能有应用程序没有正常处理子进程的退出。
如果这样的进程很多,也会占用很多系统资源(内存、系统表)
X (exit),退出状态或者死亡状态,进程已经死亡即将被销毁。
意味着接下来的代码立即就会将该进程彻底释放。所以EXIT_DEAD状态是非常短暂的,几乎不可能通过ps命令捕捉到。
参考
https://blog.csdn.net/nilxin/article/details/7437671
https://www.cnblogs.com/yjf512/p/3383915.html
https://www.cnblogs.com/liyongjian5179/p/10167447.html
linux下获取占用CPU资源最多的10个进程
ps aux|head -1;ps aux|grep -v PID|sort -rn -k +3|head
linux下获取占用内存资源最多的10个进程
ps aux|head -1;ps aux|grep -v PID|sort -rn -k +4|head
CPU利用率和cpu负载
CPU负载,是指CPU正在处理以及需要等待CPU处理的任务数,是对CPU使用队列长度的统计信息。通常zabbix等监控系统中的CPU load的监控指标,量化的就是每个核的负载情况。
CPU利用率cpu.util,表明了一段时间内CPU被占用的情况。他是这样计算出来的:执行用户态+系统态的时间除以统计时间。CPU利用率里面包含系统利用率和用户利用率,也就是cpu.util=cpu.sys+cpu.us 通常这个比例维持在7:3左右。比如A进程占用10ms,然后B进程占用30ms,然后空闲60ms,再又是A进程占10ms,B进程占30ms,空闲60ms; 如果在一段时间内都是如此,那么这段时间内的占用率为40%。使用率越高,说明你的机器在这个时间上运行了很多程序,反之较少。
CPU利用率显示的是程序在运行期间实时占用的CPU百分比
而CPU负载显示的是一段时间内正在使用和等待使用CPU的平均任务数。
ksoftirqd/0是干什么的?
您的计算机通过IRQ(中断请求)与连接到它的设备进行通信。当来自设备的中断时,操作系统会暂停它正在执行的操作并开始寻址该中断。
在某些情况下,IRQ一个接一个地非常快,操作系统无法在另一个到达之前完成一个服务。当高速网卡在短时间内收到大量数据包时,就会发生这种情况。
因为操作系统在到达时无法处理IRQ(因为它们一个接一个地到达得太快),操作系统会将它们排队等待稍后由名为
ksoftirqd的特殊内部进程处理。如果
ksoftirqd占用的CPU时间超过一小部分,则表示机器处于严重的中断负载下。
CPU异常排查思路
1、top查不到是哪个进程或者线程消耗了cpu
2、查看监控数据,检查CPU是从什么时候开始出现使用率100%。
现象是不是从某一刻起,CPU突然100%,而且一直没有下降。
3、查看系统命令在最近时间是否有修改过。
stat /usr/bin/top
stat /bin/ps
查看命令的 Change时间,是否是和CPU使用率出现100%的时间点吻合。
4、rpm 验证一下命令是否有被修改。
正常情况应该是查看不到修改信息的
rpm -Vf /bin/ps
rpm -Vf /usr/bin/top
5、观察服务器对外的网络连接情况。
iftop -i eth1 -n -P
是否对外连接一些异常的地址,例如 crypto-pool.fr 之类的异常域名地址
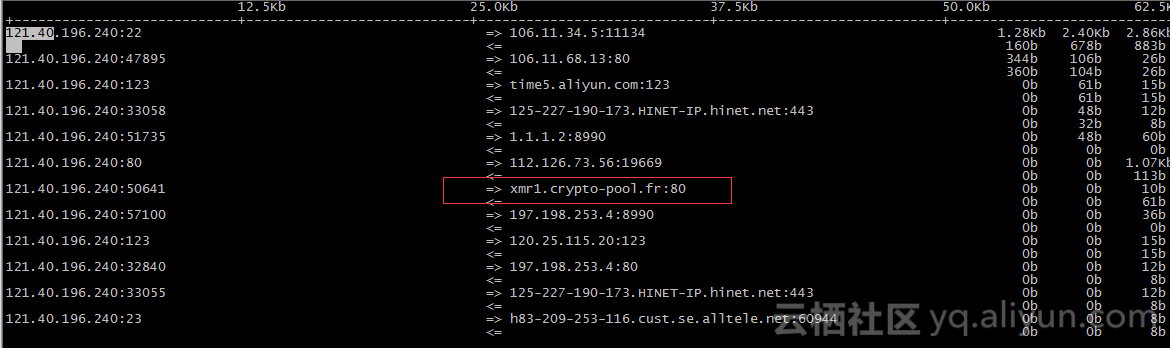
总结:符合以上几个特征,基本可以判定,服务器系统已经中招,中毒了。
尽快备份一下服务器的数据,考虑重装系统,然后加强服务器系统的安全防护。