struts2运行原理
1、tomcat 启动的时候会加载 web.xml 、核心控制器 (老版)FilterDispatcher、(新版)StrutsPrepareAndExecuteFilter 会加载并解析 struts.xml
2、客户端会发送一个请求到 action 、StrutsPrepareAndExecuteFilter(新版) 会根据后缀名进行拦截
3、FilterDispatcher根据 struts.xml 的配置文件信息 找到 某个action 对应的某个类里的指定方法
4、执行相关的业务逻辑最后返回 一个String
5、<action/> 里配置 <result/> name的属性值与返回的String 进行匹配,跳转到指定的jsp 页面
mybatis # $ 区别
1. #将传入的数据都当成一个字符串,会对自动传入的数据加一个双引号。如:order by #user_id#,如果传入的值是111,那 么 解析成sql时的值为order by "111", 如果传入的值是id,则解析成的sql为order by "id"
2. $将传入的数据直接显示生成在sql中。如:order by $user_id$,如果传入的值是111,那么解析成sql时的值为order by user_id, 如果传入的值是id,则解析成的sql为order by id.
3. #方式能够很大程度防止sql注入。
4.$方式无法防止Sql注入
5.$方式一般用于传入数据库对象,例如传入表名
6.一般能用#的就别用$
MyBatis排序时使用order by 动态参数时需要注意,用$而不是#
redis数据如何更新的

mybatis项目中怎么查询,怎么配置,怎么整合
1.导入mybatis的pom节点
2.配置数据源
3.spring配置文件中配置扫描mapper层xml位置
4.编写xml里面的sql
5.把接口层查询跟xml文件中每个mybatis标签的id属性值保持一致,然后调用查询
mongodb介绍
1. 我们主要用mongodb来存储我们项目里面的操作日志(银行的付款转账记录,角色权限的变动日志),我们主要是结 合aop来使用的,首先我们来配置一个aop的切面类,再给aop的使用规则,哪个类里面的哪个方法使用当前切面类,利 用后置通 知类获取当前方法的操作日志,将操作日志存储到mongodb,然后进行分类管理查看。利用后置通知传到数据 库。
2. 我们在项目中使用它来存储电商产品详情页的评论信息(评论id,商品id,标题,评分,内容,评论人信息,评论的发布 时间,评论标签组)并且为了提高可用性和高并发用了3台服务器做了mongodb的副本集,其中一台作为主节点,另外 两台作为副本节点,这样在任何一台mongodb服务器宕机时就会自动进行故障转移,不会影响应用程序对mongodb的操 作,为了减轻主节点的读写压力过大的问题,我还对mongodb副本集做了读写分离,使写操作在主节点进行,读取操作 在副本节点进行。为了控制 留言,我们留言的界面设置在了订单状态,只有状态为5,也就是交易成功收货后才能评 论, 并在评论成功后将订单状态改为6
【补充:如果问到副本集是怎么搭建的,就说我们有专门的运维人员来负责搭建,我只负责用Java程序去进行操作】
Spring和mongodb整合步骤:
1. 添加依赖的jar包
要想整合Spring和Mongodb必须下载相应的jar,这里主要是用到两种jar一种是spring-data-document和spring-data-commons两种类型的jar
2.定义实体类
3.Spring配置
新建application.xml配置文件
这个必须要的引入mongodb标签xmlns:mongo="http://www.springframework.org/schema/data/mongo"
在配置文件中加入链接mongodb客服端
<mongo:mongo host="localhost" port="27017">
</mongo:mongo>
注入mogondb的bean对象
<bean id="mongoTemplate" class="org.springframework.data.document.mongodb.MongoTemp">
<constructor-arg ref="mongo"/>
<constructor-arg name="databaseName" value="db"/>
<constructor-arg name="defaultCollectionName" value="person" />
</bean>
<bean id="personRepository" class="com.mongo.repository.PersonRepository">
<property name="mongoTemplate" ref="mongoTemplate"></property>
</bean>
4.然后编写操作mongodb增删查改的接口
public interface AbstractRepository {
public void insert(Person person);
public Person findOne(String id);
public List<Person> findAll();
public List<Person> findByRegex(String regex);
public void removeOne(String id);
public void removeAll();
public void findAndModify(String id);
}
再写对应接口的实现类:
import java.util.List;
import java.util.regex.Pattern;
import org.springframework.data.document.mongodb.MongoTemplate;
import org.springframework.data.document.mongodb.query.Criteria;
import org.springframework.data.document.mongodb.query.Query;
import org.springframework.data.document.mongodb.query.Update;
import com.mongo.entity.Person;
import com.mongo.intf.AbstractRepository;
public class PersonRepository implements AbstractRepository{
private MongoTemplate mongoTemplate;
@Override
public List<Person> findAll() {
return getMongoTemplate().find(new Query(), Person.class);
}
@Override
public void findAndModify(String id) {
getMongoTemplate().updateFirst(new Query(Criteria.where("id").is(id)), nw Update().inc("age", 3));
}
@Override
public List<Person> findByRegex(String regex) {
Pattern pattern = Pattern.compile(regex,Pattern.CASE_INSENSITIVE);
Criteria criteria = new Criteria("name").regex(pattern.toString()); return getMongoTemplate().find(new Query(criteria), Person.class); }
@Override
public Person findOne(String id) {
return getMongoTemplate().findOne(new Query(Criteria.where("id").is(id)), Person.class);
}
@Override
public void insert(Person person) {
getMongoTemplate().insert(person);
}
@Override
public void removeAll() {
List<Person> list = this.findAll();
if(list != null){
for(Person person : list){
getMongoTemplate().remove(person);
}
}
}
@Override
public void removeOne(String id){
Criteria criteria = Criteria.where("id").in(id);
if(criteria == null){
Query query = new Query(criteria);
if(query != null && getMongoTemplate().findOne(query, Person.class) != null)
getMongoTemplate().remove(getMongoTemplate().findOne(query, Person.class)); }
}
public MongoTemplate getMongoTemplate() {
return mongoTemplate;
}
public void setMongoTemplate(MongoTemplate mongoTemplate) {
this.mongoTemplate = mongoTemplate;
}
}
5.实现类注入到service层调用
dubbo + zk 介绍
Duboo是一个分布式框架,zookeeper是duboo生产者暴露服务的注册中心。起一个调度和协调功能,当然注册中心也可以用redis 或者duboo自带的Multicast(mo ti ka si te) 来注册。
Duboo 通信方式采用长链接方式,所以当spring启动后链接就接通,duboo的消费者和生产者就可以直接调用。性能上高于其他http协议的请求。当时是为了解决单个服务器站点的压力,将项目拆分成页面加controller属于消费者,service+dao属于生产者,所有生产者暴露的端口都注册在zookeeper里面。这时候,消费者要调用生产者去zookeeper中取就可以了。所以我们部署了多套生产者,所有的消费者的请求可以由多个生产者去提供,具体由哪个生产者提供可以由zookeeper的配置去决定。如果某个生产者挂掉,zookeeper会将压力导向其他生产者,当这个生产者恢复状态的时候。Zookeeper会重新启用它。如果想让单个tomcat执行的action---service—dao 请求由多个tomcat来执行就可以使用 zookeeper+duboo 这时候一般是一个tomcat里面部署的是jsp+action所有的service接口都注册到了zookeeper里面,action去zookeeper里面通过duboo去调用哪个 service+dao 的组合。而且service+dao的组合可以配置多套。一套挂了其他的service+dao组合可以继续使用
dubbo框架的体系结构有5个核心组成部分,分别是提供者provider(普发一的),它的作用是为消费者提供数据。注册中心registry(ruai几丝追),它的作用是用来注册和发现服务。消费者consumer(肯酥么儿),它的作用是调用远程提供者提供的服务。监控中心Monitor(嘛呢de er)用来统计服务的调用次数以及调用时间,还有container(肯提呢er)用来充当容器来加载,运行服务提供者。
新建dubbo-provider(普发一的).xml配置文件,通过dubbo:application配置提供者应用名,通过dubbo:registry(ruai几丝追)配置注册中心的地址,通过dubbo:protocol(pro to ka)配置协议,以及通过dubbo:service来暴露要发布的接口。
最后我们在需要使用dubbo接口的项目中配置消费者信息,新建dubbo-consumer(肯酥么儿).xml文件,通过dubbo:application配置消费者应用名,通过dubbo:registry(ruai几丝追)指明要订阅的注册中心地址,通过dubbo:reference(ruai fu 让 ci)指定要订阅的服务接口。
配置dubbo集群来提高健壮性以及可用性。dubbo默认的集群容错机制是Failover(飞漏发)即失败自动切换,默认的重试次数为2,可以通过retries(为 chua aisi)调整。dubbo默认的负载均衡策略是Random随机,可以按权重设置随机概率。我们在写完dubbo提供者之后,为了测试接口的正确性,我们会进行直连测试。首先会在提供者端,通过将dubbo:registry(ruai几丝追)的register(ruai ji si te )设置为false,使其只订阅服务而不注册现在正在开发的服务;在消费者端,通过设置dubbo:reference(ruai fu 让 ci)的url,直连提供者进行测试。
mybatis 查询如何把接口与xml对应
通过接口中方法名称与xml文件中的id属性值保持一致
poi导入导出
package demo;
import java.io.FileOutputStream;
import java.io.IOException;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import org.apache.poi.hssf.usermodel.HSSFCell;
import org.apache.poi.hssf.usermodel.HSSFCellStyle;
import org.apache.poi.hssf.usermodel.HSSFDataFormat;
import org.apache.poi.hssf.usermodel.HSSFRow;
import org.apache.poi.hssf.usermodel.HSSFSheet;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import org.apache.poi.hssf.util.Region;
import org.apache.poi.ss.usermodel.Font;
import entity.Student;
public class Export_demo {
public static void main(String[] args) {
export();
}
public static void export(){
List<Student> studens=new ArrayList<Student>();
for (int i = 1; i <=20; i++) {
Student s=new Student(i, "a"+i, 20+i-20, "三年级");
studens.add(s);
}
HSSFWorkbook wb = new HSSFWorkbook();//创建一个excel文件
HSSFSheet sheet=wb.createSheet("学生信息");//创建一个工作薄
sheet.setColumnWidth((short)3, 20* 256); //---》设置单元格宽度,因为一个单元格宽度定了那么下面多有的单元格高度都确定了所以这个方法是sheet的
sheet.setColumnWidth((short)4, 20* 256); //--->第一个参数是指哪个单元格,第二个参数是单元格的宽度
sheet.setDefaultRowHeight((short)300); // ---->有得时候你想设置统一单元格的高度,就用这个方法
HSSFDataFormat format= wb.createDataFormat(); //--->单元格内容格式
HSSFRow row1 = sheet.createRow(0); //--->创建一行
// 四个参数分别是:起始行,起始列,结束行,结束列 (单个单元格)
sheet.addMergedRegion(new Region(0, (short) 0, 0, (short)5));//可以有合并的作用
HSSFCell cell1 = row1.createCell((short)0); //--->创建一个单元格
cell1.setCellValue("学生信息总览");
sheet.addMergedRegion(new Region(1, (short) 0, 1, (short)0));
HSSFRow row2= sheet.createRow(1); ////创建第二列 标题
HSSFCell fen = row2.createCell((short)0); //--->创建一个单元格
fen.setCellValue("编号/属性 ");
HSSFCell no = row2.createCell((short)1); //--->创建一个单元格
no.setCellValue("姓名 ");
HSSFCell age = row2.createCell((short)2); //--->创建一个单元格
age.setCellValue("年龄 ");
HSSFCell grage = row2.createCell((short)3); //--->创建一个单元格
grage.setCellValue("年级 ");
for (int i = 0; i <studens .size(); i++) {
sheet.addMergedRegion(new Region(1+i+1, (short) 0, 1+i+1, (short)0));
HSSFRow rows= sheet.createRow(1+i+1); ////创建第二列 标题
HSSFCell fens = rows.createCell((short)0); //--->创建一个单元格
fens.setCellValue(studens.get(i).getNo());
HSSFCell nos = rows.createCell((short)1); //--->创建一个单元格
nos.setCellValue(studens.get(i).getName());
HSSFCell ages = rows.createCell((short)2); //--->创建一个单元格
ages.setCellValue(studens.get(i).getAge());
HSSFCell grages = rows.createCell((short)3); //--->创建一个单元格
grages.setCellValue(studens.get(i).getGrage());
}
FileOutputStream fileOut = null;
try{
fileOut = new FileOutputStream("d:\\studens.xls");
wb.write(fileOut);
//fileOut.close();
System.out.print("OK");
}catch(Exception e){
e.printStackTrace();
}
finally{
if(fileOut != null){
try {
fileOut.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
递归5的阶乘
/*
* 题目:利用递归方法求5!的阶乘。
* 分析:
* 首先明确什么是递归? 递归:
*/
public class DiGuiQiuJieCheng {
public static void main(String[] args) {
System.out.println(DiGui(5));
}
//构造递归函数
public static int DiGui(int n) {
if(n==1) {
return 1;
}else {
return DiGui(n-1)*n;
}
}
}
设计模式
设计模式分为三大类:
创建型模式:工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式
结构型模式:适配器模式、装饰者模式、代理模式、外观模式、桥接模式、组合模式、享元模式
行为型模式:策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式
还有两类:并发型模式和线程池模式。
参考文档:https://www.cnblogs.com/tongkey/p/7170826.html
https://blog.csdn.net/jason0539/article/details/44956775
还有什么想问的吗
1.职位空缺的原因
2.公司怎么保证人才不流式
3.试用期时间和通过试用期的标准
4.大概的工作内容
HashMap hashTable的区别
HashMap和Hashtable都实现了Map接口,但决定用哪一个之前先要弄清楚它们之间的分别。主要的区别有:线程安全性,同步(synchronization),以及速度。
- HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。
- HashMap是非synchronized,而Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
- 另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
- 由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
- HashMap不能保证随着时间的推移Map中的元素次序是不变的。
前端JS熟悉吗?
熟悉,也经常在用,就是把数据库数据拿出来放到页面上展示,基本上前端的东西都能写,有时候还偶尔写一些js特效
Mybatis的xml中如何让sql变得干净 整洁
可以通过一些动态标签来整理sql 有if where sql片段 foreach 等等
Mongodb如果主机当掉怎么办
结合业务说,在存储数据之前,先把存数据的消息放到队列中,如果数据库挂掉,可以从队列中回复数据。
springMVC和spring的区别
spring 是是一个开源框架,是为了解决企业应用程序开发,功能如下
◆目的:解决企业应用开发的复杂性
◆功能:使用基本的JavaBean代替EJB,并提供了更多的企业应用功能
◆范围:任何Java应用
简单来说,Spring是一个轻量级的控制反转(IoC)和面向切面(AOP)的容器框架。
◆轻量——从大小与开销两方面而言Spring都是轻量的。完整的Spring框架可以在一个大小只有1MB多的JAR文件里发布。并且Spring所需的处理开销也是微不足道的。此外,Spring是非侵入式的:典型地,Spring应用中的对象不依赖于Spring的特定类。
◆控制反转——Spring通过一种称作控制反转(IoC)的技术促进了松耦合。当应用了IoC,一个对象依赖的其它对象会通过被动的方式传递进来,而不是这个对象自己创建或者查找依赖对象。你可以认为IoC与JNDI相反——不是对象从容器中查找依赖,而是容器在对象初始化时不等对象请求就主动将依赖传递给它。
◆面向切面——Spring提供了面向切面编程的丰富支持,允许通过分离应用的业务逻辑与系统级服务(例如审计(auditing)和事务(transaction)管理)进行内聚性的开发。应用对象只实现它们应该做的——完成业务逻辑——仅此而已。它们并不负责(甚至是意识)其它的系统级关注点,例如日志或事务支持。
◆容器——Spring包含并管理应用对象的配置和生命周期,在这个意义上它是一种容器,你可以配置你的每个bean如何被创建——基于一个可配置原型(prototype),你的bean可以创建一个单独的实例或者每次需要时都生成一个新的实例——以及它们是如何相互关联的。然而,Spring不应该被混同于传统的重量级的EJB容器,它们经常是庞大与笨重的,难以使用。
◆框架——Spring可以将简单的组件配置、组合成为复杂的应用。在Spring中,应用对象被声明式地组合,典型地是在一个XML文件里。Spring也提供了很多基础功能(事务管理、持久化框架集成等等),将应用逻辑的开发留给了你。
所有Spring的这些特征使你能够编写更干净、更可管理、并且更易于测试的代码。它们也为Spring中的各种模块提供了基础支持。
Spring的两大核心AOP与IOC,可以单独用于任何应用,包括与Struts等MVC框架与Hibernate等ORM框架的集成,目前很多公司所谓的轻量级开发就是用 Spring + Struts(2)+Hibernate。
Spring MVC就是一个MVC框架,个人觉得Spring MVC annotation式的开发比Struts2方便,可以直接代替上面的Struts(当然Struts的做为一个非常成熟的MVC,功能上感觉还是比Spring强一点,不过Spring MVC已经足够用了)。当然spring mvc的执行效率比struts高,是因为struts的值栈影响效率
spring mvc类似于struts的一个MVC开框架,其实都是属于spring,spring mvc需要有spring的架包作为支撑才能跑起来
git和svn的区别
1) 最核心的区别Git是分布式的,而Svn不是分布的。能理解这点,上手会很容易,声明一点Git并不是目前唯一的分布式版本控制系统,还有比如Mercurial等,所以说它们差不许多。话说回来Git跟Svn一样有自己的集中式版本库和Server端,但Git更倾向于分布式开发,因为每一个开发人员的电脑上都有一个Local Repository,所以即使没有网络也一样可以Commit,查看历史版本记录,创建项 目分支等操作,等网络再次连接上Push到Server端。
从上面看GIt真的很棒,但是GIt adds Complexity,刚开始使用会有些疑惑,因为需要建两个Repositories(Local Repositories & Remote Repositories),指令很多,除此之外你需要知道哪些指令在Local Repository,哪些指令在Remote Repository。
2)Git把内容按元数据方式存储,而SVN是按文件:因为,.git目录是处于你的机器上的一个克隆版的版本库,它拥有中心版本库上所有的东西,例如标签,分支,版本记录等。.git目录的体积大小跟.svn比较,你会发现它们差距很大。
3) Git没有一个全局版本号,而SVN有:目前为止这是跟SVN相比Git缺少的最大的一个特征。
4) Git的内容的完整性要优于SVN: GIT的内容存储使用的是SHA-1哈希算法。这能确保代码内容的完整性,确保在遇到磁盘故障和网络问题时降低对版本库的破坏。
5) Git下载下来后,在OffLine状态下可以看到所有的Log,SVN不可以。
6) 刚开始用时很狗血的一点,SVN必须先Update才能Commit,忘记了合并时就会出现一些错误,git还是比较少的出现这种情况。
7) 克隆一份全新的目录以同样拥有五个分支来说,SVN是同时复製5个版本的文件,也就是说重复五次同样的动作。而Git只是获取文件的每个版本的 元素,然后只载入主要的分支(master)在我的经验,克隆一个拥有将近一万个提交(commit),五个分支,每个分支有大约1500个文件的 SVN,耗了将近一个小时!而Git只用了区区的1分钟!
8) 版本库(repository):SVN只能有一个指定中央版本库。当这个中央版本库有问题时,所有工作成员都一起瘫痪直到版本库维修完毕或者新的版本库设立完成。而 Git可以有无限个版本库。或者,更正确的说法,每一个Git都是一个版本库,区别是它们是否拥有活跃目录(Git Working Tree)。如果主要版本库(例如:置於GitHub的版本库)发生了什麼事,工作成员仍然可以在自己的本地版本库(local repository)提交,等待主要版本库恢复即可。工作成员也可以提交到其他的版本库!
9)分支(Branch)在SVN,分支是一个完整的目录。且这个目录拥有完整的实际文件。如果工作成员想要开啟新的分支,那将会影响“全世界”!每个人都会拥有和你一样的分支。如果你的分支是用来进行破坏工作(安检测试),那将会像传染病一样,你改一个分支,还得让其他人重新切分支重新下载,十分狗血。而 Git,每个工作成员可以任意在自己的本地版本库开啟无限个分支。举例:当我想尝试破坏自己的程序(安检测试),并且想保留这些被修改的文件供日后使用, 我可以开一个分支,做我喜欢的事。完全不需担心妨碍其他工作成员。只要我不合并及提交到主要版本库,没有一个工作成员会被影响。等到我不需要这个分支时, 我只要把它从我的本地版本库删除即可。无痛无痒。
有了git ,svn就是一垃圾
java数据结构
- 枚举(Enumeration)
- 位集合(BitSet)
- 向量(Vector)
- 栈(Stack)
- 字典(Dictionary)
- 哈希表(Hashtable)
- 属性(Properties)
以上这些类是传统遗留的,在Java2中引入了一种新的框架-集合框架(Collection),
springIOC介绍
我认为spring就是一个框架的集成器,通常使用spring来管理action层和DAO层。Spring本身有很多的组件,比如:MVC、IOC、AOP、DaoSupport等等。IOC本身也就是一个容器,它管理了所有的bean和bean之间的依赖关系。IOC也叫作控制反转,核心是BeanFactory。也就意味着IOC是基于工厂模式设计的,同时这个工厂生产的bean默认是单例的。如果想修改单例变成多实例,则需要修改bean的scope属性,值是prototype。在没有使用IOC以前,程序员需要自己在对应的类中new相关依赖的对象。比如UserAction依赖于UserService完成业务操作,而UserService又依赖于UserDAO完成数据库操作。所以需要在action中new servcie,在service中new DAO。这样的方式,是由程序员来管理了对象的生命周期和他们之间的依赖关系,耦合度很高,不利于程序的拓展。所以通过IOC来管理bean和依赖关系,可以解耦合。我们将所有的action、service和dao等类定义成IOC的一个bean组件,此时类的实例化就交给了IOC的beanFactory,由工厂来负责实例化bean的对象。IOC有三种注入方式,属性注入、构造器注入和接口注入。接口注入只是spring提出的设计,并没有具体的实现,所以常用的注入方式是属性注入。属性注入就是在bean的标签中,配置property标签设定注入其他的bean。要求注入的bean在被注入的bean中要存在一个全局的私有变量,并提供set方法。这样就可以实现了依赖关系的注入。如果需要很多的bean,则直接注入就可以。如此操作会导致bean标签的配置比较冗余复杂,所以spring提供了autowried的自动装配方式,可以byName也可以byType。后续的版本中,spring还提供了annotation的方式,不需要再去定义多余的bean标签,而是直接在对应的类上面声明注解就可以了。常用的注解有:@controller、@Service、@Repository、@Component、@AutoWried、@Resource等。除了IOC以外,项目中通常通过AOP来实现事务控制。AOP就是面向切面编程,一般事务我们会控制在service层,因为一个service有可能会调用到多个DAO层的方法,所以只有当一个service方法执行成功后,再提交或者回滚事务。具体的配置方式是:在applicationContext.xml中,配置aop:config标签,指定事务控制在service层。除此还需要配置事务的管理类transactionManager,将这个transactionManager指定给事务管理的bean,并且配置事务的传播特性、隔离级别、回滚策略以及只读事务read-only等等。Spring默认的传播特性是如果当前上下文中存在事务则支持当前事务,如果没有事务,则开启一个新的事务。还有另外一个传播特性是在项目中经常用的,REQUIRES_NEW这个配置,这个属性指的是总是开启一个新的事务,如果当前上下文中存在一个事务,则将当前的事务挂起后开启新的事务。比如说:在一个本来是只读事务的操作中,想加入写操作的时候,就使用REQUIRES_NEW。关于事务的隔离级别,一般使用默认的配置提交读。也就是说,事务提交以后,才能访问这条数据。除了事务控制以外,我们通常还可以使用AOP去完成一些特殊操作,比如日志控制、安全校验等等。这么做的目的就是将功能操作的代码从实际的业务逻辑操作出分离出来。实现的方式是通过代理模式,真正完成操作的不是实际的业务对象而是代理对象。代理模式有静态代理和动态代理,实现的方案也有两种,一种是基于JDK的Proxy代理类,另外一种则通过CGLIB来实现。实现AOP的方式,主要是在applicationContext中定义一个AOP处理类,这就是一个普通的bean,在类中定义要执行的方法。然后去配置一个aop:config标签,在标签中定义aop:aspect切面,在切面中关联刚才定义好的处理类bean。然后在切面标签中配置aop:pointcut切入点,切入点就指的是在哪个类的哪个方法上加入代理事务,然后配置通知模型。AOP的通知模型中包含:前置通知、后置通知、最终通知、异常通知、环绕通知。这几个通知模型表示在方法执行以前、执行以后、最终执行、当遇到异常时执行以及前后都执行。在执行的AOP切面方法中,可以通过JoinPoint连接点来获得当前被代理的对象以及被代理对象要执行的方法和方法的参数。除了IOC和AOP,我们经常还会使用到spring的DaoSupport。主要是spring提供了对hibernate和myBatis等持久型框架的接口。比如HibernateDaoSupport,和sqlSessionDaoSupport。如果DAO继承了HibernateDaoSupport,则需要在对应的bean中注入sessionFactory。而sessionFactory是通过IOC加载的。
hashCode和equse方法的区别
1、当覆盖了equals方法时,比较对象是否相等将通过覆盖后的equals方法进行比较(判断对象的内容是否相等)。
2、hashCode方法只有在set或map集合中用到
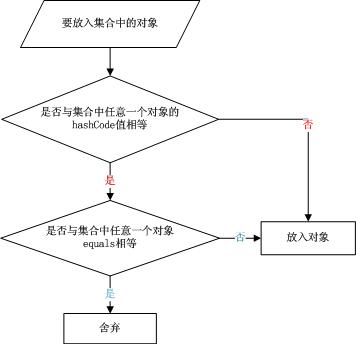
3、将对象放入到集合中时,首先判断要放入对象的hashCode值与集合中的任意一个元素的hashCode值是否相等,
如果不相等直接将该对象放入集合中。如果hashCode值相等,然后再通过equals方法判断要放入对象与集合中的
任意一个对象是否相等,如果equals判断不相等,直接将该元素放入到集合中,否则不放入。
4、将元素放入集合的流程图:
mysql事物的隔离级别
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
| 读未提交(read-uncommitted) | 是 | 是 | 是 |
| 不可重复读(read-committed) | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 否 | 否 | 是 |
| 串行化(serializable) | 否 | 否 | 否 |
mysqlACID属性
1、原子性(Atomicity):事务开始后所有操作,要么全部做完,要么全部不做,不可能停滞在中间环节。事务执行过程中出错,会回滚到事务开始前的状态,所有的操作就像没有发生一样。也就是说事务是一个不可分割的整体,就像化学中学过的原子,是物质构成的基本单位。
2、一致性(Consistency):事务开始前和结束后,数据库的完整性约束没有被破坏 。比如A向B转账,不可能A扣了钱,B却没收到。
3、隔离性(Isolation):同一时间,只允许一个事务请求同一数据,不同的事务之间彼此没有任何干扰。比如A正在从一张银行卡中取钱,在A取钱的过程结束前,B不能向这张卡转账。
4、持久性(Durability):事务完成后,事务对数据库的所有更新将被保存到数据库,不能回滚。
sql优化
二、SQL优化的一些方法
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num=0
3.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
4.应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or num=20
可以这样查询:
select id from t where num=10
union all
select id from t where num=20
5.in 和 not in 也要慎用,否则会导致全表扫描,如:
select id from t where num in(1,2,3)
对于连续的数值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3
6.下面的查询也将导致全表扫描:
select id from t where name like '%abc%'
7.应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where num/2=100
应改为:
select id from t where num=100*2
8.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where substring(name,1,3)='abc'--name以abc开头的id
应改为:
select id from t where name like 'abc%'
9.不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
10.在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,
否则该索引将不会被使用,并且应尽可能的让字段顺序与索引顺序相一致。
11.不要写一些没有意义的查询,如需要生成一个空表结构:
select col1,col2 into #t from t where 1=0
这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样:
create table #t(...)
12.很多时候用 exists 代替 in 是一个好的选择:
select num from a where num in(select num from b)
用下面的语句替换:
select num from a where exists(select 1 from b where num=a.num)
13.并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引,
如一表中有字段sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用。
14.索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,
因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。
一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
15.尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。
这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
16.尽可能的使用 varchar 代替 char ,因为首先变长字段存储空间小,可以节省存储空间,
其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
17.任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
18.避免频繁创建和删除临时表,以减少系统表资源的消耗。
19.临时表并不是不可使用,适当地使用它们可以使某些例程更有效,例如,当需要重复引用大型表或常用表中的某个数据集时。但是,对于一次性事件,最好使用导出表。
20.在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log ,
以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert。
21.如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。
22.尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。
23.使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效。
24.与临时表一样,游标并不是不可使用。对小型数据集使用 FAST_FORWARD 游标通常要优于其他逐行处理方法,尤其是在必须引用几个表才能获得所需的数据时。
在结果集中包括“合计”的例程通常要比使用游标执行的速度快。如果开发时间允许,基于游标的方法和基于集的方法都可以尝试一下,看哪一种方法的效果更好。
25.尽量避免大事务操作,提高系统并发能力。
26.尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。
数据库索引
数据库索引好比是一本书前面的目录,能加快数据库的查询速度。索引是对数据库表中一个或多个列(例如,employee 表的姓氏 (lname) 列)的值进行排序的结构。如果想按特定职员的姓来查找他或她,则与在表中搜索所有的行相比,索引有助于更快地获取信息。
优点:
1.大大加快数据的检索速度;
2.创建唯一性索引,保证数据库表中每一行数据的唯一性;
3.加速表和表之间的连接;
4.在使用分组和排序子句进行数据检索时,可以显著减少查询中分组和排序的时间。
缺点: 1.索引需要占用数据表以外的物理存储空间 2.创建索引和维护索引要花费一定的时间 3.当对表进行更新操作时,索引需要被重建,这样降低了数据的维护速度。
Linux命令如何给文件夹设置权限
|
|
命令中各选项的含义为
|
|
操作符号可以是:
|
|
设置mode所表示的权限可用下述字母的任意组合:
|
|
X 只有目标文件对某些用户是可执行的或该目标文件是目录时才追加x 属性。
|
|
实例
修改文件可读写属性的方法
例如:把index.html 文件修改为可写可读可执行:
|
|
要修改目录下所有文件属性可写可读可执行:
|
|
把文件夹名称与后缀名用*来代替就可以了。
比如:修改所有htm文件的属性:
|
|
修改文件夹属性的方法
把目录 /images/xiao 修改为可写可读可执行
|
|
Linux查看本地日志
linux查看日志文件内容命令tail、cat、tac、head、echo
tail -f test.log
你会看到屏幕不断有内容被打印出来. 这时候中断第一个进程Ctrl-C,
---------------------------
linux 如何显示一个文件的某几行(中间几行)
从第3000行开始,显示1000行。即显示3000~3999行
cat filename | tail -n +3000 | head -n 1000
显示1000行到3000行
cat filename| head -n 3000 | tail -n +1000
*注意两种方法的顺序
分解:
tail -n 1000:显示最后1000行
tail -n +1000:从1000行开始显示,显示1000行以后的
head -n 1000:显示前面1000行
用sed命令
sed -n '5,10p' filename 这样你就可以只查看文件的第5行到第10行。
例:cat mylog.log | tail -n 1000 #输出mylog.log 文件最后一千行
---------------------------
cat主要有三大功能:
1.一次显示整个文件。$ cat filename
2.从键盘创建一个文件。$ cat > filename
只能创建新文件,不能编辑已有文件.
3.将几个文件合并为一个文件: $cat file1 file2 > file
参数:
-n 或 --number 由 1 开始对所有输出的行数编号
-b 或 --number-nonblank 和 -n 相似,只不过对于空白行不编号
-s 或 --squeeze-blank 当遇到有连续两行以上的空白行,就代换为一行的空白行
-v 或 --show-nonprinting
例:
把 textfile1 的档案内容加上行号后输入 textfile2 这个档案里
cat -n textfile1 > textfile2
把 textfile1 和 textfile2 的档案内容加上行号(空白行不加)之后将内容附加到 textfile3 里。
cat -b textfile1 textfile2 >> textfile3
把test.txt文件扔进垃圾箱,赋空值test.txt
cat /dev/null > /etc/test.txt
注意:>意思是创建,>>是追加。千万不要弄混了。
------------------------------------------
tac (反向列示)
tac 是将 cat 反写过来,所以他的功能就跟 cat 相反, cat 是由第一行到最后一行连续显示在萤幕上,
而 tac 则是由最后一行到第一行反向在萤幕上显示出来!
------------------------------------------
在Linux中echo命令用来在标准输出上显示一段字符,比如:
echo "the echo command test!"
这个就会输出“the echo command test!”这一行文字!
echo "the echo command test!">a.sh
这个就会在a.sh文件中输出“the echo command test!”这一行文字!
该命令的一般格式为: echo [ -n ] 字符串其中选项n表示输出文字后不换行;字符串能加引号,也能不加引号。
用echo命令输出加引号的字符串时,将字符串原样输出;
用echo命令输出不加引号的字符串时,将字符串中的各个单词作为字符串输出,各字符串之间用一个空格分割。
Java常见的线程池
一:newCachedThreadPool
(1)缓存型池子,先查看池中有没有以前建立的线程,如果有,就reuse,如果没有,就建立一个新的线程加入池中;
(2)缓存型池子,通常用于执行一些生存周期很短的异步型任务;因此一些面向连接的daemon型server中用得不多;
(3)能reuse的线程,必须是timeout IDLE内的池中线程,缺省timeout是60s,超过这个IDLE时长,线程实例将被终止及移出池。
(4)注意,放入CachedThreadPool的线程不必担心其结束,超过TIMEOUT不活动,其会自动被终止
二:newFixedThreadPool
(1)newFixedThreadPool与cacheThreadPool差不多,也是能reuse就用,但不能随时建新的线程
(2)其独特之处:任意时间点,最多只能有固定数目的活动线程存在,此时如果有新的线程要建立,只能放在另外的队列中等待,直到当前的线程中某个线程终止直接被移出池子
(3)和cacheThreadPool不同,FixedThreadPool没有IDLE机制(可能也有,但既然文档没提,肯定非常长,类似依赖上层的TCP或UDP IDLE机制之类的),所以FixedThreadPool多数针对一些很稳定很固定的正规并发线程,多用于服务器
(4)从方法的源代码看,cache池和fixed 池调用的是同一个底层池,只不过参数不同:
fixed池线程数固定,并且是0秒IDLE(无IDLE)
cache池线程数支持0-Integer.MAX_VALUE(显然完全没考虑主机的资源承受能力),60秒IDLE
三:ScheduledThreadPool
(1)调度型线程池
(2)这个池子里的线程可以按schedule依次delay执行,或周期执行
四:SingleThreadExecutor
(1)单例线程,任意时间池中只能有一个线程
(2)用的是和cache池和fixed池相同的底层池,但线程数目是1-1,0秒IDLE(无IDLE)