作者:IT小样
beautifulsoup 可以从HTML或者XML文件中提取数据。
BeautifulSoup基础引用
html_doc = '''
<html><head><title>hello,tester</title></head><body>
<p class="title"><b><h1>Hello,welcome</h1></b></p>
<p class="documentation">Tester, welcome! This is a new partion of your job's life. With python, you can finnish your work easier and faster.How, <a href="http://example.com/easier" class="easier" id="link1"> easier </a> and <a href="http://example.com/faster" class="faster" id = "link2">faster</a> Now, you have a initial impression about python.</p>
<p class="documention">let's go!!!</p>
</body></html>
'''
上面是一段html代码,可以用这段代码来初步了解BeautifulSoup。
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc)
print("html_doc:"soup.prettify())
print("title:"soup.title)
print(soup.title.name)
print(soup.title.string)
print(soup.title.parent.name)
print(soup.p)
print(soup.p['class'])
print(soup.a)
print(soup.find_all('a'))
print(soup.find(id="link2"))
for link in soup.find_all('a'):
print(link.get('href'))
print(soup.get_text())
依次对代码进行解析:soup=BeautifulSoup(html_doc),将html_doc转化为BeautifulSoup对象
soup.prettify(),将html_doc文档规范化输出
soup.title,输出整个title块,如图:

soup.title.name,输出title的名称
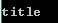
soup.title.string,输出title的内容
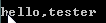
soup.title.parent.name,输出title的上一层的名称
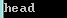
soup.p,输出段落p的整个内容,显示文档中找到的第一个

soup.p[‘class’],输出找到的p的内容的class属性内容:
![soup.p['class']](https://img-blog.csdnimg.cn/20190321143517686.png)
soup.a,输出找到的第一个

soup.find_all(‘a’),以列表形式输出找到的所有

soup.find(id=‘link2’),输出id=‘link2’的元素

for link in soup.find_all(‘a’)
print(link.get(‘href’))
这一个for语句,是找到所有的a元素,并且分别输出每一个的href的内容

soup.get_text(),获取文档中所有的文字内容

以上是初步的BeautifulSoup的入门指导
上一篇:Python学习爬虫(2)–requests库
下一篇:Python学习爬虫(4)–beautifulSoup库Tag对象和NavigableString详细介绍
