mask rcnn简介
mask rcnn是何凯明基于以往的faster rcnn架构提出的新的卷积网络,一举完成了object instance segmentation. 该方法在有效地目标的同时完成了高质量的语义分割。 文章的主要思路就是把原有的Faster-RCNN进行扩展,添加一个分支使用现有的检测对目标进行并行预测。同时,这个网络结构比较容易实现和训练,速度5fps也算比较快点,可以很方便的应用到其他的领域,像目标检测,分割,和人物关键点检测等。并且比着现有的算法效果都要好,在后面的实验结果部分有展示出来。
场景理解

Mask R-CNN: overview
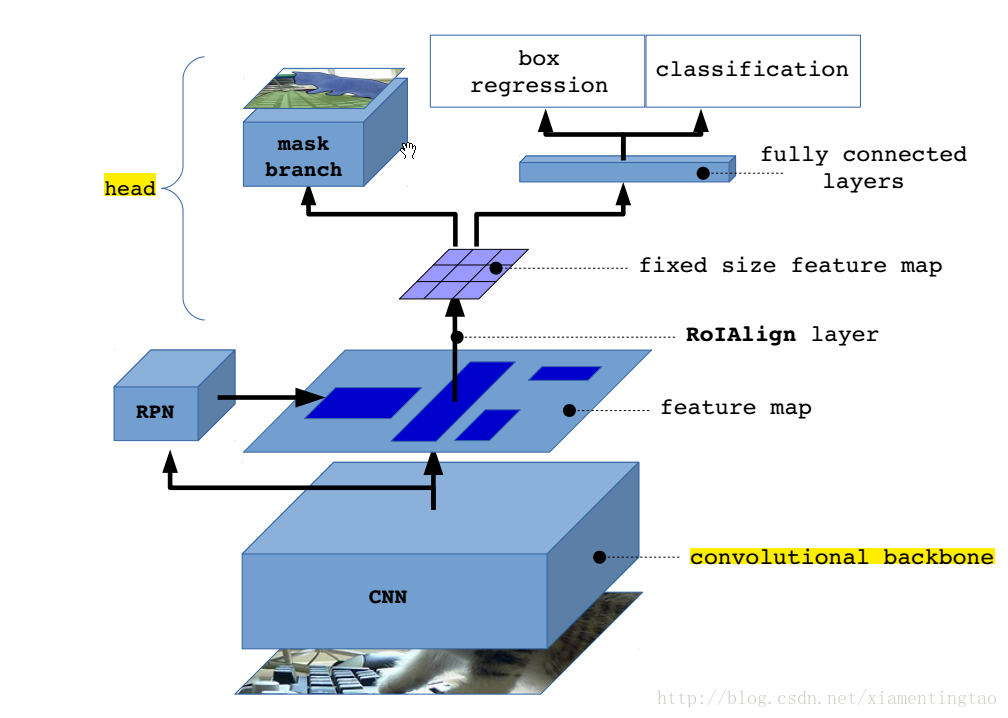
从上面可以知道,mask rcnn主要的贡献在于如下:
1. 强化的基础网络
通过 ResNeXt-101+FPN 用作特征提取网络,达到 state-of-the-art 的效果。
2. ROIAlign解决Misalignment 的问题
3. Loss Function
细节描述
1. resnet +FPN
作者替换了在faster rcnn中使用的vgg网络,转而使用特征表达能力更强的残差网络。
另外为了挖掘多尺度信息,作者还使用了FPN网络。
2. ROIAlign
说到这里,自然要与roi pooling对比。
我们先看看roi pooling的原理,这里我们可以看https://github.com/deepsense-ai/roi-pooling 的动图,一目了然。
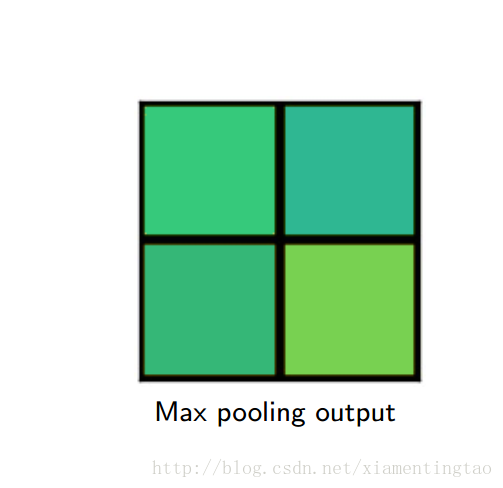
对于roi pooling,经历了两个量化的过程:
第一个:从roi proposal到feature map的映射过程。方法是[x/16],这里x是原始roi的坐标值,而方框代表四舍五入。
第二个:从feature map划分成7*7的bin,每个bin使用max pooling。
这两种情况都会导致证输入和输出之间像素级别上的一一对应(pixel-to-pixel alignment between network input and output)。
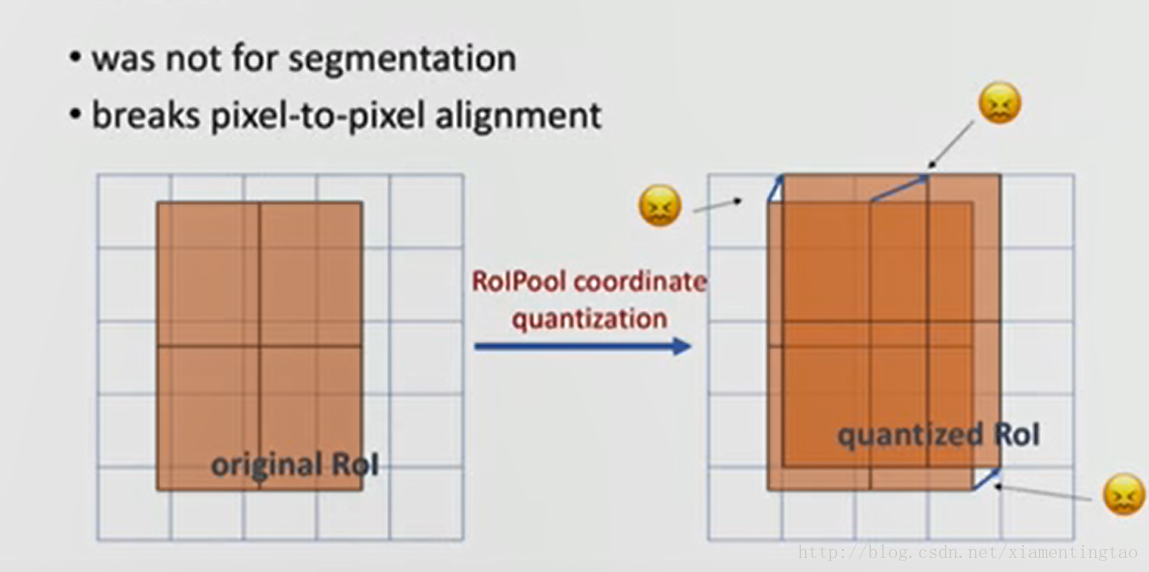
因此作者设计了ROI Align layer。
作者的ROI Align layer想法很简单,就是去掉ROI Pooling过程中所有的量化过程,包括从原图proposal到最后一层feature map映射,以及把feature map划分成m*m的bin过程中的量化。
我们使用何凯明在iccv2017的ppt来说明。可以在百度云盘下载。链接: https://pan.baidu.com/s/1jHRubfK 密码: jh5c

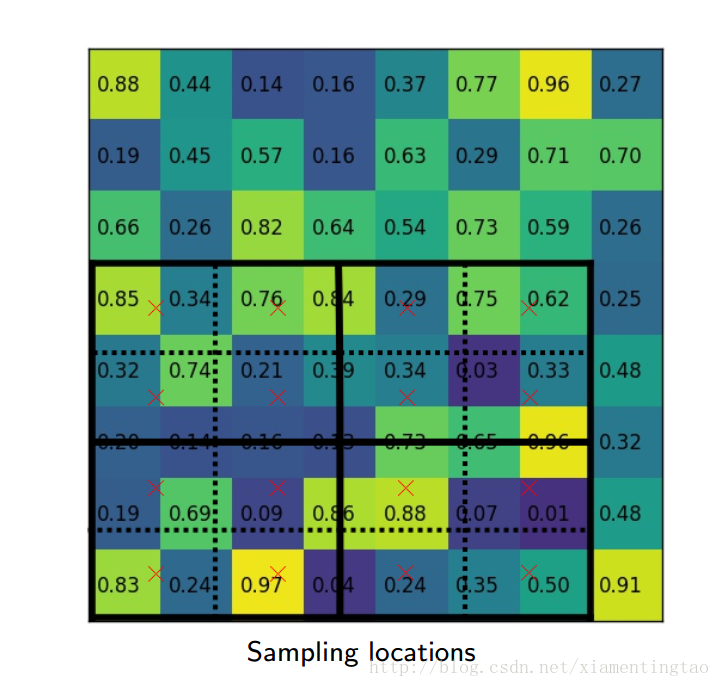
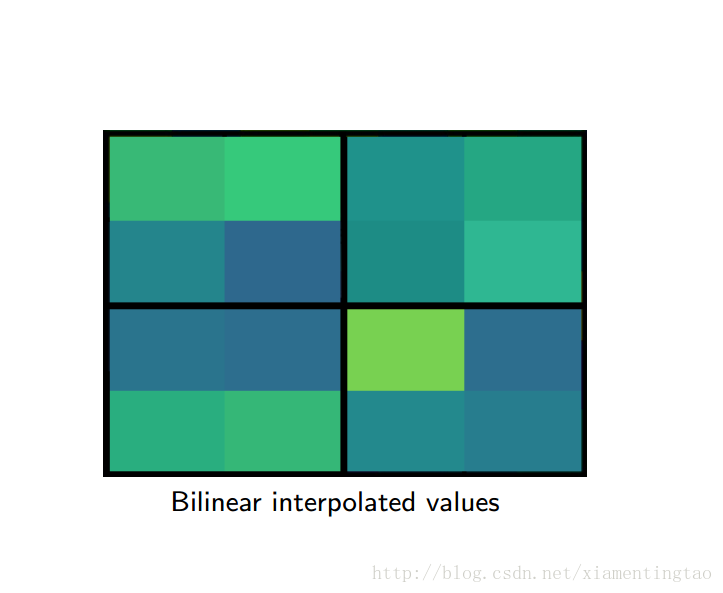
如上,roi映射到feature map后,不再进行四舍五入。然后将候选区域分割成k x k个单元, 在每个单元中计算固定四个坐标位置,用双线性内插的方法计算出这四个位置的值,然后进行最大池化操作。
这里对上述步骤的第三点作一些说明:这个固定位置是指在每一个矩形单元(bin)中按照比例确定的相对位置。比如,如果采样点数是1,那么就是这个单元的中心点。如果采样点数是4,那么就是把这个单元平均分割成四个小方块以后它们分别的中心点。显然这些采样点的坐标通常是浮点数,所以需要使用插值的方法得到它的像素值。在相关实验中,作者发现将采样点设为4会获得最佳性能,甚至直接设为1在性能上也相差无几。事实上,ROI Align 在遍历取样点的数量上没有ROIPooling那么多,但却可以获得更好的性能,这主要归功于解决了misalignment的问题。值得一提的是,在做实验的时候发现,ROI Align在VOC2007数据集上的提升效果并不如在COCO上明显。经过分析为造成这种区别的原因是COCO上小目标的数量更多,而小目标对misalignment问题的影响更为明显(比如,同样是0.5个像素点的偏差,对于较大的目标而言显得微不足道,但是对于小目标,误差的影响就要高很多)
下面摘取上面百度云盘里的一个ppt的插图,更加细致地描述roialign。
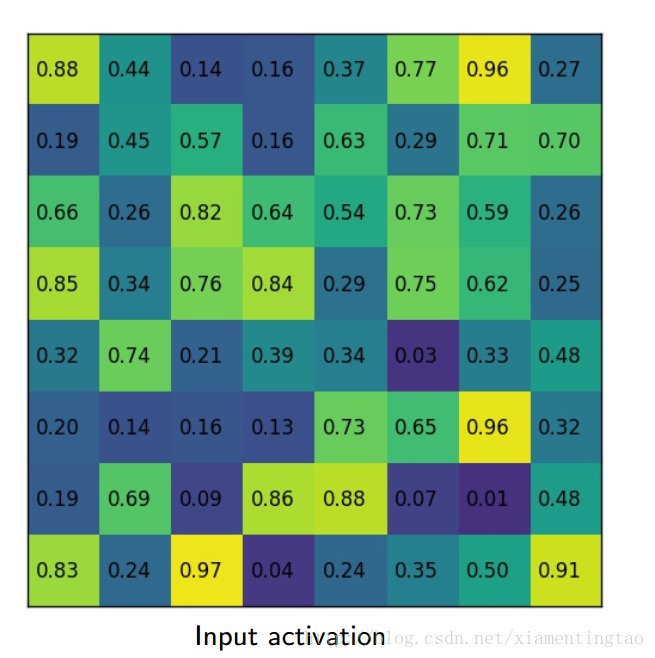
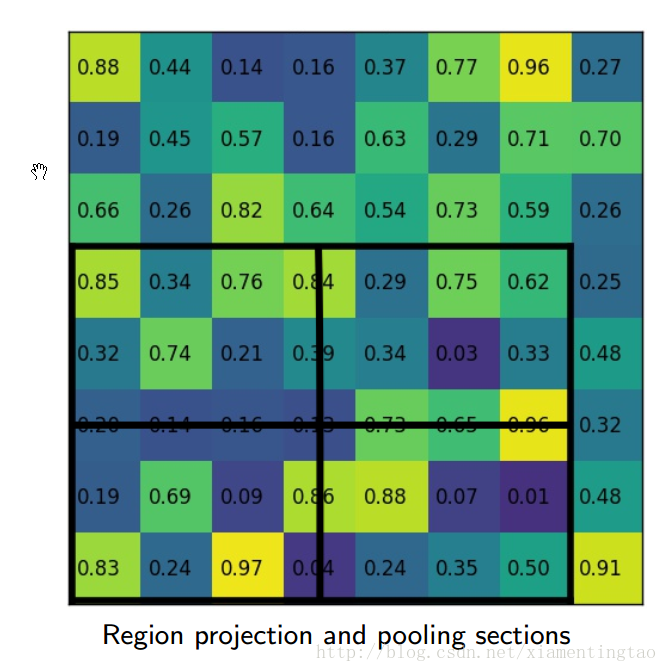
也可以参考:http://blog.leanote.com/post/[email protected]/b5f4f526490b
上面这篇文章还介绍了ROI Align的反向传播算法。
roi pooling的求导可以参考:http://ow680yzep.bkt.clouddn.com/iccv15_tutorial_training_rbg.pdf
下图对比了三种方法的不同,其中roiwarp来自:J. Dai, K. He, and J. Sun. Instance-aware semantic segmentation via multi-task network cascades 
3. loss function
损失函数就是分类,回归加mask预测的损失之和。 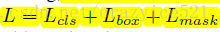
其中,对于mask分支和其他的分类分支一样,使用全卷积网络输出,输出了k类的mask。注意这里mask的输出使用了sigmoid函数。最后可以通过与阈值0.5作比较输出二值mask。这样避免了类间的竞争,将分类的任务交给专业的classification分支。
而Lmask对于每一个像素使用二值的sigmoid交叉熵损失。
参考theano的文档,二值的交叉熵定义如下: 这里的o就是sigmoid输出。

4. 整个网络结构

这里实际上有两个网络结构,一个就是:Mask R-CNN: overview的那副图(或者如上左边)。使用resnet-c4作为前面的卷积网络,将rpn生成的roi映射到C4的输出,并进行roi pooling,最后进行分叉预测三个目标。
另一个网络就是这里的faster rcnn with fpn。
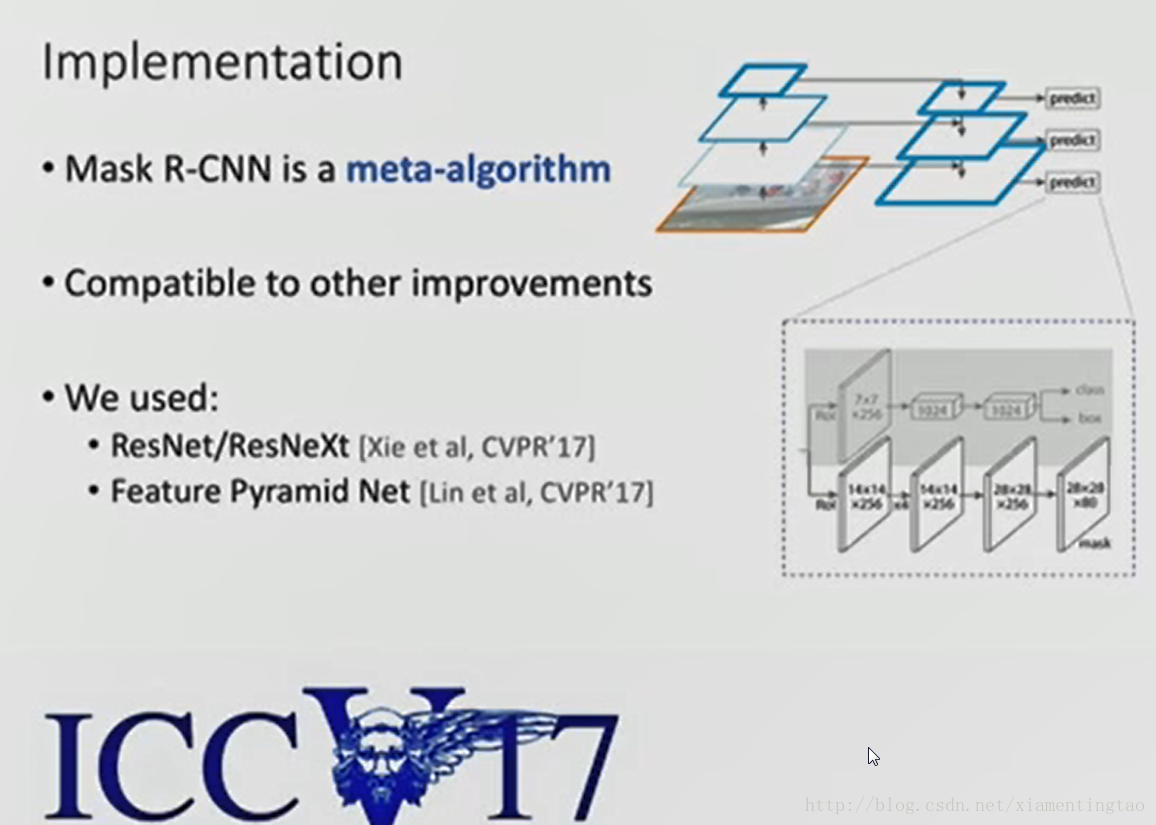
上述图像同样来自何凯明的ICCV2017 ppt
如上,使用fpn网络,每一个阶层连接一个三分支网络。考虑了多尺度信息,因此可以检测更加小的目标。
至于是否像之前的FPN在各阶层共享三分支网络,不太清楚。
总结
mask rcnn的主要贡献其实就是roi align以及加了一个mask分支。
目前开源代码有:
期待官方的源码放出~~