深入浅出MySQL读书笔记(一)
前言
在某大神童靴的强烈安利下最近阅读了深入浅出MySQL一书,这本书的第三部分,介绍了MySQL数据库的一些优化方法,非常值得一读,推荐大家如果有时间都可以阅读一下,下面博客的主要内容实际是个人的读书笔记。主要内容包括以下方面:
- 索引相关内容
- 常见SQL的优化方法
- MySQL排序的基础知识
- 深分页的两种优化方法
本系列博文的主要针对对象是开发人员,而非DBA,有些内容不会进行详细介绍。
准备工作
我们的的实践主要是在MySQL提供的测试数据sakila上,测试数据的下载地址
下载地址,下载好数据后解压,进入目录通过MySQL运行命令source sakila-mv-schema.sql和source sakila-mv-data.sql,就可以将数据导入到MySQL数据库中。
这里一定要在文件夹下进行数据导入,否则会有报错。
优化SQL语句你需要知道的几个命令
说起优化SQL语句,首先我们需要知道哪些SQL语句的效率是有问题的,我们要能够在生产环境排查出有问题的SQL语句,这样才能对SQL进行优化,所以,我们先来介绍几个查看SQL语句执行效率方面的命令。
- 查看SQL执行频率
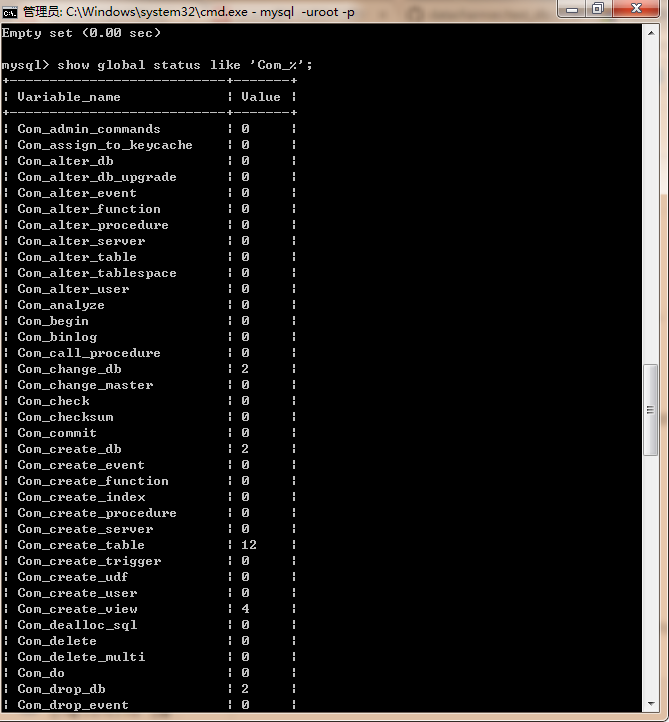
我们可以通过show global status like "Com%"命令来查看这个数据库从启动到现在为止所有SQL类型的执行频率。同时可以将global更改为local,来查询当前session的SQL执行频率。
- 慢查询日志定位慢SQL
MySQL提供了一种日志叫做慢查询日志,通过这个日志,我们可以定位那些执行效率较低的SQL,这种方式一般由DBA管理,这里不做详细介绍,如果想要了解可以自行上网查找相关介绍。
- 通过explain分析低效SQL的执行计划
当我们怀疑某个SQL有低效的问题,我们就可以通过explain命令来分析其执行计划,找出低效的原因。
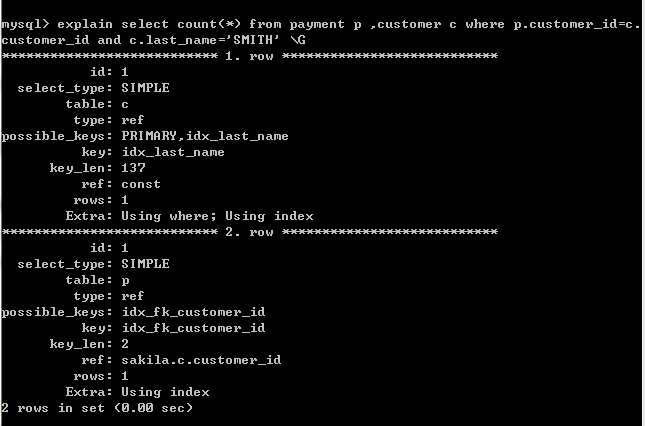
下面解释一下每列的含义:
1) select_type : 表示select类型,simple(简单表,不需要表连接或子查询),primary(主查询,即外层的查询,主要指的是嵌套查询中的最外层,表连接中最前面的select语句),union(表连接中的第二个或后面的select语句),subquery(子查询中的第一个select)等。
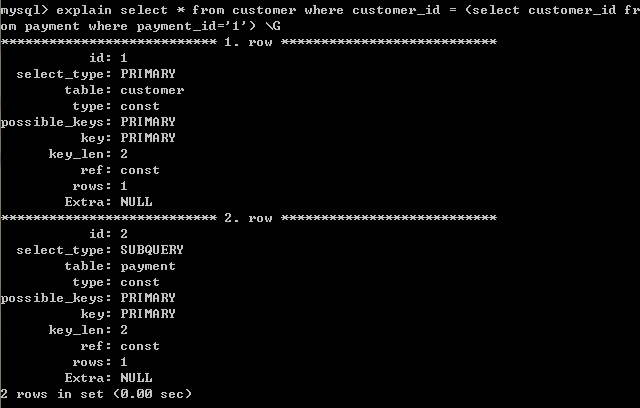
2) table : 输出结果集的表
3) type : 表示表的连接类型,是一个重要的部分,性能由好到差分别为system、const、eq_ref、ref、 ref_or_null、index_merge、unique_subquery、index_subquery、range、index、all
4) possible_keys : 查询时可能用到的索引
5) key : 最终实际使用的索引
6) key_len : 索引字段的长度
7) rows : 扫描行的数量,越少越好
8) extra : 执行情况的额外说明
通过sql的执行计划我们可以等到SQL实际的执行顺序,使用的索引,当我们的查询没有使用到索引时,我们的查询就会很慢,所以我们可以通过执行计划来适当修改或新建索引。
索引介绍
这部分我们来介绍索引的一些知识,包括建立索引需要考虑的一些点以及索引的一些基础知识。
索引的分类
MySQL中的索引主要有四种,分别B树索引、哈希索引、全文索引和R-tree索引,所有的存储引擎都支持B树索引,哈希索引只有MEMORY引擎支持,全文索引只有MyISAM引擎支持,MyISAM引擎支持R-tree索引,但使用较少
前缀索引
MyISAM和InnoDB默认创建的都是BTREE索引,索引实际上也是需要占用存储,所以,如果我们在一个很大的表上建立联合索引,那么索引数据会增长的十分快,这个时候我们可以考虑使用前缀索引,只对索引字段的前N个字符创建索引,这样可以有效减少索引的大小。
前缀索引同样存在缺点,在排序ORDER BY和分组GROUP BY时无法使用,因此需要根据实际情况处理。

HASH索引与BTEE索引
在默认情况下,Memory存储引擎默认使用HASH索引,但也支持BTREE索引。
两种不同的索引有其不同的适用范围,HASH索引的适用范围较小,需要注意。
- 只用于=或<=>操作符等式比较
- 无法加速ORDER BY操作
- 只能用整个关键字来搜索一行
- 当需要适用范围查询时需要建立BTREE索引
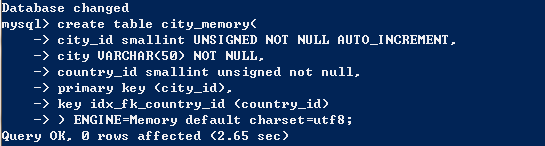
下面给出例子,首先创建一个Memory引擎的表。
范围搜索实际不能适用hash索引,见下图
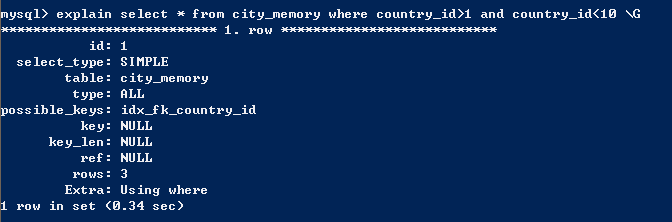
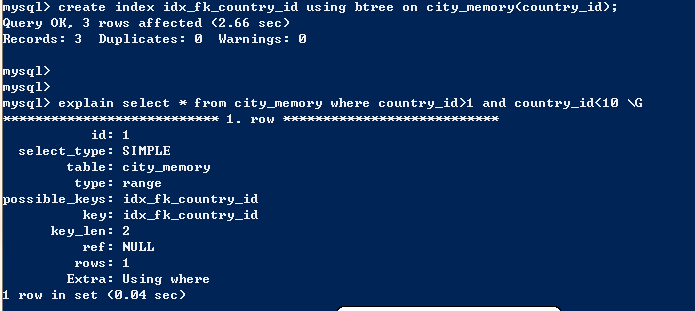
将hash索引改为btree索引再查看,发现搜索过程中成功使用索引。

设计原则
- 最适合创建索引的是where语句后出现的字段
- 创建索引的列的值尽量是多样性的,基数越大索引效果越好。例如,如果在记录性别的列上创建索引,那么对此列索引没有多大用处,因为不管搜索那个值,都会得到大约一半的行。
- 使用短索引。如果对字符创索引,而字符串的长度有比较长,那么就尽量使用前缀索引,方便节省空间,同时也会让查询更快。
- 利用最左前缀。当创建组合索引(a,b,c)时,该索引可以被a,(ab),(abc)等查询利用到,但是不能够被b,(bc)利用。这个原则是最左匹配原则。后面还会做详细介绍。
- 不要过度索引,索引是需要占用磁盘空间的,当我们设计索引的时候一定要选择最合适的索引,而不是什么都索引,这样可能导致无法选中最佳索引。
对于InnoDB引擎的表,最好指定主键,并且尽量选择较短的数据作为主键。因为InnoDB表的记录默认会按照一定顺序存储,如果有明确主键,则会安札主键顺序保存,如果没有主键,但是有唯一索引,那么会按照唯一索引顺序保存,如果两者都没有,那么表会自动生成一个内部列,按照这个顺序保存,按照主键或内部列进行访问时最快的。
能够使用索引的经典场景
匹配全值,对索引中所有列都指定具体值。type字段为const,表示是常量。

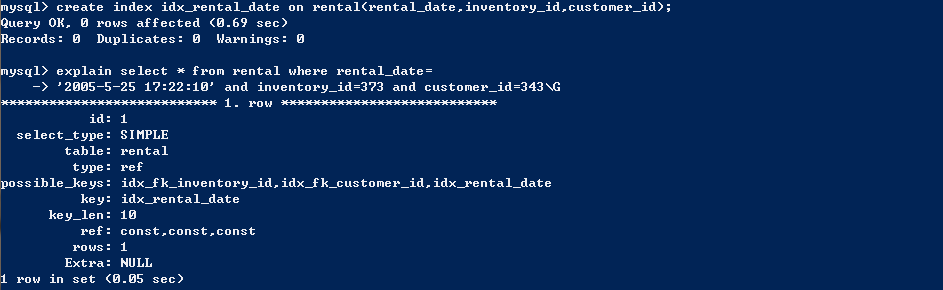
- 匹配值的范围查询,对索引的值进行范围查找。type字段为range,表示范围。
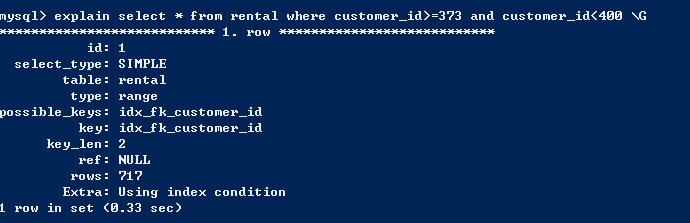
- 匹配最左前缀,这个实际就是前面介绍过的最左前缀原则。
这里给出两个例子。

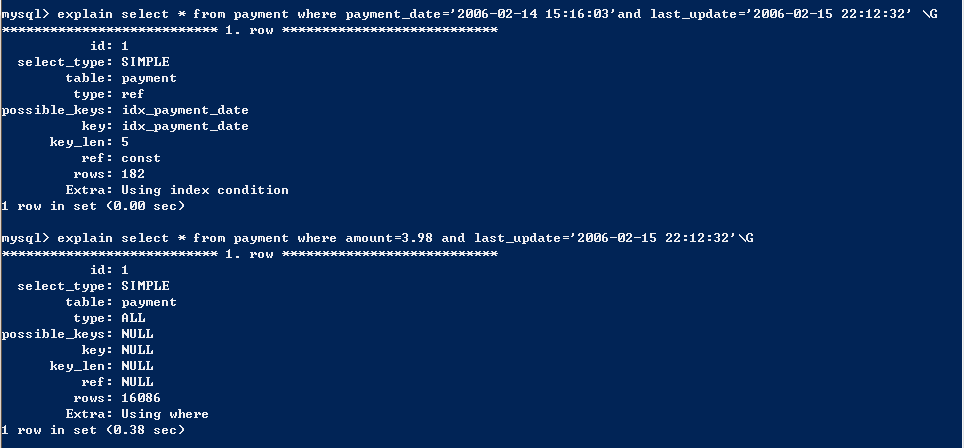
- 仅仅对索引进行查询,当查询的所有列都在索引字段中时,查询效率更高。
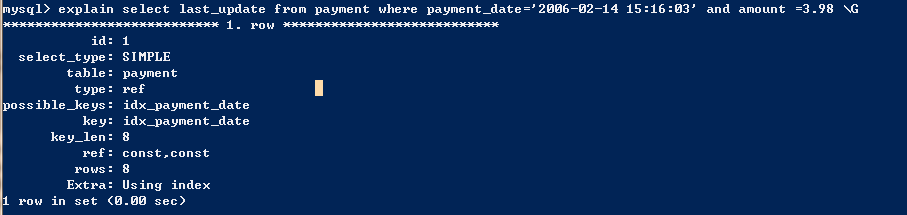
当查询是仅对索引进行查询时,extra字段为using index,即覆盖索引扫描。 - 仅匹配列前缀,这里想要说明的是extra的另外一种,值为using where,表示优化器需要通过索引回表查询数据。由于我们创建的索引是前缀索引,同时我们查询的还是前缀索引的字段,所以使用索引后依然要回表中去查询数据。
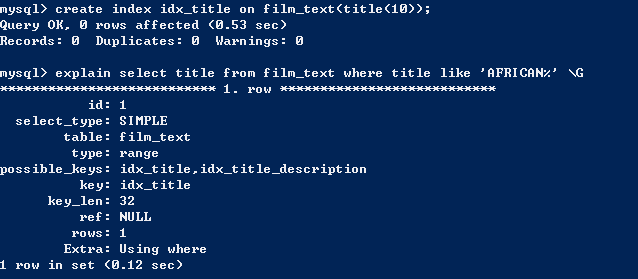
- 索引匹配部分精确而其他部分进行范围匹配。范围匹配不能通过索引确定唯一,仍需使用using where过滤元组
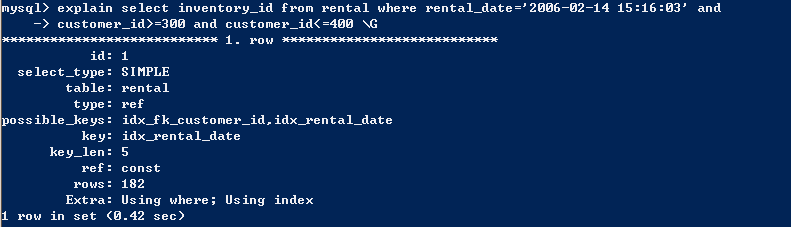
- 如果列名是索引,那么使用列名为null查询也会使用索引。
MySQL的ICP特性,优化了查询,将某些情况下的过滤操作下放到存储引擎,也就是说当我们在低版本的MySQL上有些查询最终可能是using where,但是到高版本上,相同的查询,因为ICP特性就变成了using index condition,这也是MySQL的优化,降低了不必要的IO操作。
几种需要注意的不会使用索引的情况
下面介绍几种优化器不会使用索引的情况,我们在写SQL语句和设计索引的时候应该尽量避免这些情况,提高效率。
- 第一个就是以%开头的like查询,所以我们应该尽量不要写这样的语句。这种全文检索问题尽量使用全文索引来解决。
- 当数据类型出现隐式转换时。例如列类型时字符串,但是where条件中没有将其用引号括起来,这样即便列上有索引,也无法使用。
- 复合索引时,SQL语句不符合最左前缀原则。
- 当MySQL估计使用索引比全表扫描更慢时,就不会使用索引。例如查询“S”开头的电影,这种返回记录较多的情况。
- or分割开的条件必须每列都有索引,才会走索引。因为如果有没有索引的列,那么最终肯定也要做全表扫描,那么不如直接一次全表扫描过滤条件,避免无用的IO。
常用SQL的优化
有关查询的SQL通常的优化方法就是通过索引来进行优化,这些在上面已经介绍的差不多了,那么还有一些其他常用SQL的优化将在下面介绍。
大批量插入数据
当使用InnoDB引擎时,尽量关闭唯一性校验,当导入结束后再打开,同时插入的数据应尽量按照主键顺序排列,并且关闭自动提交,当导入数据结束后再打开。
相关命名如下
set UNIQUE_CHECK=0;
set SUTOCOMMIT=0;当使用MyISAM引擎时,我们应该尽量关闭索引更新。
命令如下
alter table tbl_name disable keys;ORDER BY 语句
MySQL中两种排序方式
首先先了解一下customer表上的索引,方便后面的介绍。
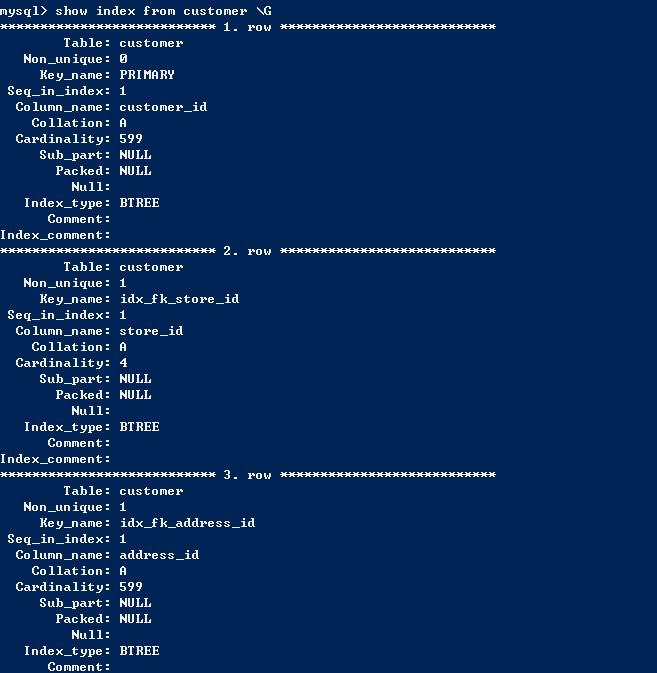
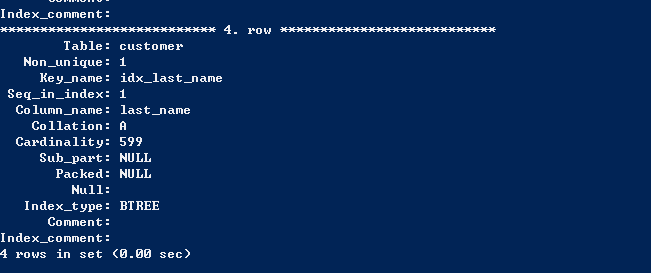
首先介绍第一种,就是using index,通过查询有序索引返回有序结果。
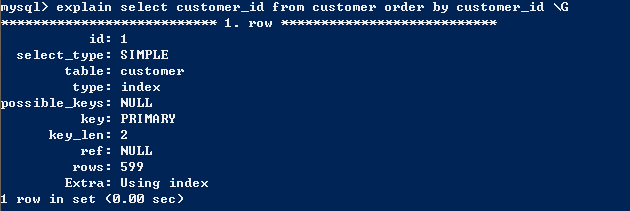
第二种就是using filesort,这种情况表示进行了额外的排序工作,这种情况并不表示使用了磁盘文件进行排序操作,这只是表示进行了额外的排序操作,至于排序操作时如何进行的,则取决于MySQL的决定。
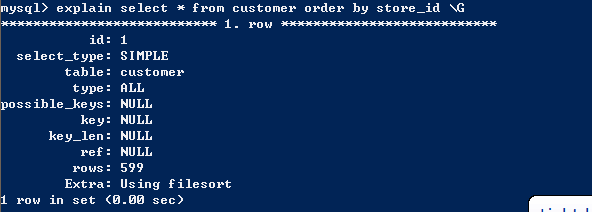
下面这个例子可以清晰的表明这种情况,即使所有的数据都在索引中,依然有using filesort
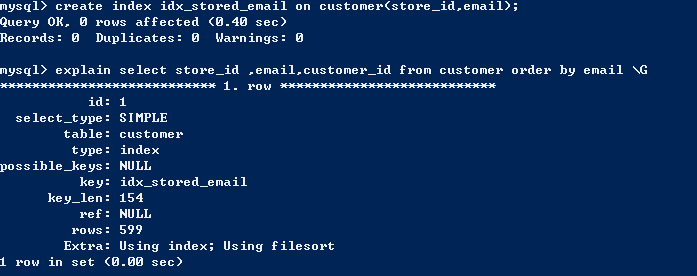
FileSort
filesort是通过排序算法,将数据在sort_buffer_size系统变量设置的内存排序区中进行排序,如果排序区放不下,那么会将磁盘上的数据进行分块,再分别进行排序,最后合并为有序的结果集。这个排序区是线程独占的,同一时刻,MySQL中可能存在多个。
优化
那么,现在优化主要有两个方法,一种是减少额外的排序,通过索引直接返回有序数据,一种是优化filesort。
首先介绍第一种。WHERE条件和ORDER BY条件使用的索引是同一个,并且索引顺序和ORDER BY的顺序是相同的时,并且ORDER BY 字段都是升序或降序。如果不满足以上三个条件,那么肯定要进行额外的排序,就会出现filesort。因此,我们写ORDER BY的时候尽量满足。
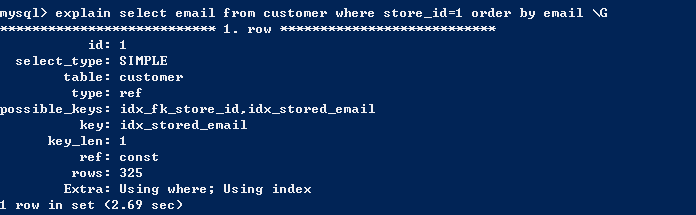
有时,就算完全满足条件,也不能确保不出现filesort,例如:
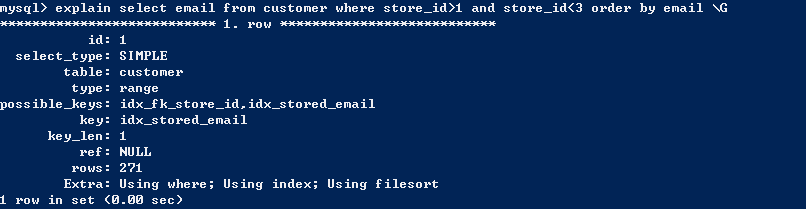
因此,这里又涉及到filesort的优化。
filesort有两种排序算法。
- 两次扫描算法:根据条件取出排序字段和行指针信息,在排序区中进行排序,如果排序区不够,那么就在临时表中先存储结果,当完成后,在根据行指针回表取数据,这样就涉及了两次扫描,其中第二次扫描可能十分耗时,毕竟存在大量的随机IO操作。
- 一次扫描算法:根据条件一次性取出所有字段和行指针信息,在排序区进行排序。排序效率高于两次扫描算法。
两种算法的选择是通过max_length_for_sort_data的大小和query语句取出字段总大小来决定的。因此,通过增大max_length_for_sort_data的值,可以让更多的排序可以采用一次扫描排序,但是,需要注意,这个值也不能过大,否则反而会造成效率降低。
同时,我们也可以增大排序区sort_buffer_size的大小,让排序更多的在内存中完成,提高效率,同样,也不可以过大,因为这个区域是线程独占。
同样的,我们也可以通过减少query中的字段来达到加快排序的目的。因此select语句尽量不适用select *,直接写出需要的字段。
GROUP BY 优化
GROUP BY 语句实际上会对后面的字段进行排序,隐含操作ORDER BY,因此,当我们不需要进行排序时,我们可以增加字句ORDER BY NULL来禁止排序。
优化嵌套查询
SQL的子查询可以一次性完成很多逻辑上很多步骤才能完成的SQL操作,同时可以避免事物或表死锁,写起来也十分容易。但是,有些时候其效率较连接查询更低。所以一般使用join来优化子查询操作。
实际上子查询的过程中产生了临时表,因此相比join操作多了临时变的建立和销毁,同时临时变中的数据无法使用索引,更进一步降低了速度,所以,当我们的SQL可以使用join时,尽量不要使用子查询。
下面的例子给出同一个查询数据的不同实现
select * from customer where customer_id not in (select customer_id from payment)
select * from customer c left join payment p on c.customer_id = p.customer_id where p.customer_id is nullOR条件的优化
其实,OR条件的优化,在前面已经提到过了,只有当OR连接的每一列都有索引时,才会使用索引,因此,在写SQL的时候尽量让每列都有索引,这样速度会大大加快。
分页查询的两种优化方法
一般分页查询的时候,我们都会通过创建覆盖索引的方式提高性能。但是有些时候,我们的数据较多,会发生深分页,也就是limit 1000,10,这种情况,此时查询了1010条记录,排序后却只需要返回1001到1010的10条记录,造成了很大的浪费。
针对这种情况,我们给出两种通用做法。
{kind=link}
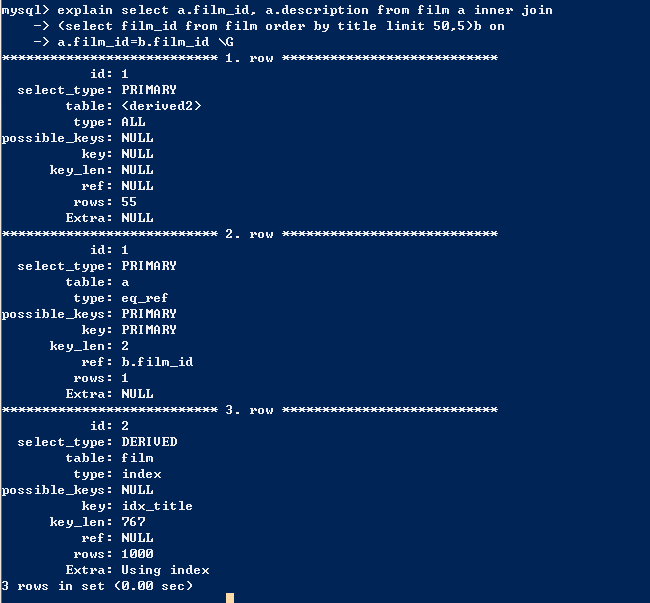
优化后我们按照索引分页改写SQL后,已经看不到全表扫描了。这里需要注意,我们的前提是已经建立了title上的索引。
- 第二种优化思路
第二种思路其实是将limit查询操作转化为某个位置的查询。每次查询后都记录查询结果的最后一个,下次查询直接查询该记录后的n个结果就可以了。
给出优化前的sql
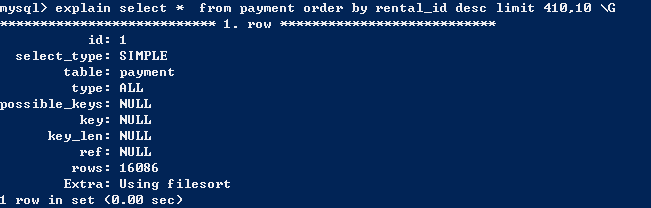
可以看出这个查询使用全表扫描。
优化后
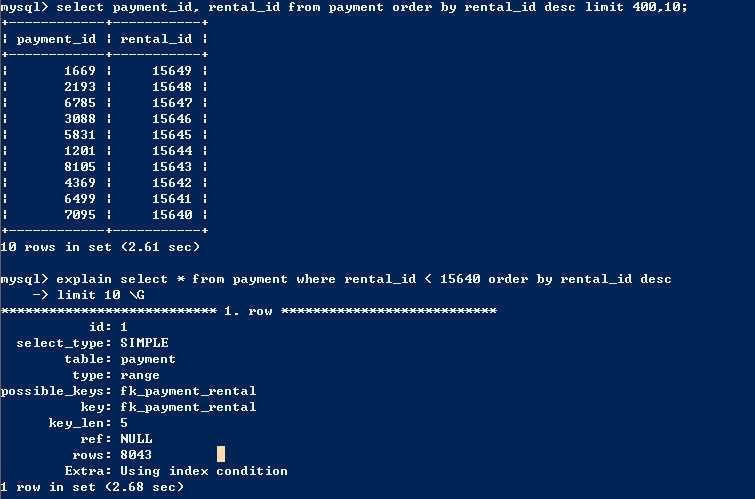
这种优化方法比较简便,但是这种方法有一定的局限性。当排序字段存在重复元素时,这种方法会出现错误,遗漏数据。因此我们需要根据情况比较如何选择。