数据转换
1. 去除重复数据
首先创建一个含有重复项的DataFrame,

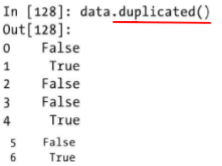
判断数据是否重复——duplicated方法
判断是否为重复项的方法是duplicated方法,
去除重复项——drop_duplicates方法
1)基本使用
官方文档中drop_duplicates方法的定义,
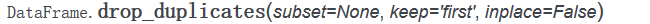

2)subset参数
默认是全部列进行去重,也可以使用字符串或者列表指定对某一列或者某几列进行去重。
3)keep参数
依据官方文档,keep参数有三个可选项,

2. 将映射用于数据转换——series对象map方法
pandas中的数据对象可以使用map方法,


现在要在这一基础上添加一列,这一列用于记录food给哪种动物吃,


3. 替换值——replace方法
除了使用fillna方法替换缺失值,还可以使用 replace方法的替换效果更好,
1)一个值替换为另一个值


2)多个值替换为一个值
只需要将要被替换的值以Python列表的形式传入函数即可,


3)一次性替换多个值
列表形式

字典形式

4. 索引重命名
index对象的map方法(原数据上改动)
index对象与Series对象一样可以使用map方法对其进行操作,

无论是Series还是Dataframe的索引对象都是可以修改的,


index对象rename方法(保证原数据不变)
1)方法及参数解读
DataFrame的操作相比Series更复杂,因为包含行索引和列索引,

参数说明,

2)基本使用
index和column参数
对DataFrame的列索引进行rename操作,columns参数传入作用到列索引上的方法;而对行索引的rename操作,index参数传入作用到行索引上的方法,
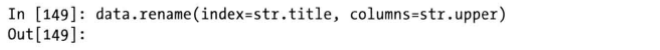
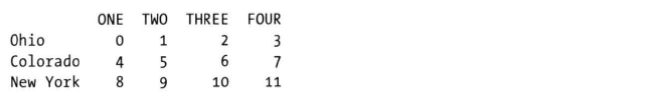
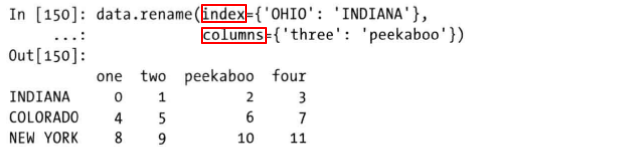
rename方法可以通过index和columns参数对指定的索引和列名进行修改,
5. 离散化和面元划分
cut方法
离散化、面元化是将连续的数据变成离散数据,比如说分割为不同的区间,使用的是pandas的cut方法,
1)参数说明


2)bins参数
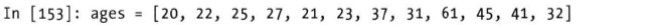
将ages中的年龄分入不同的bins中,
bins参数是一个列表,即人为指定一个区间,

bins参数是一个整数,此时会将整个值的区间进行等分,
官方文档提供的cut方法使用,

3)label参数

需要注意的是cut方法返回的是一个Categories对象,该对象有两个属性,一个是labels属性,另一个是levels属性,再有就是常常使用pandas的 value_counts方法,对其进行操作,


qcut方法
1)参数说明
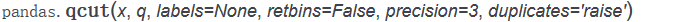

2)q参数
q参数可以是数值也可以是四分位数的数组,

qcut方法也支持自定义分位数,

上方的代码传入的序列是自定义的分位数值。
6. 异常值处理
异常值,也叫孤立点或离群值,其过滤和变换很大程度上是数组运算。
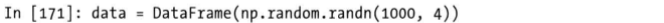

取出某列中绝对值大于某个值的数,

取出列索引为3的列中绝对值大于3的数。
含有大于某个值的所有的行,

所有的存在绝对值大于3的数的行。
7. 排列和随机采样
使用numpy的random模块permutation方法可以实现对Series和Dataframe的重排序,且这一重排序是随机的。
回顾permutation方法的使用,

在此基础上将permutation方法运用在Dataframe上,

返回结果的类型是一个 numpy数组,permutation方法只是在 axis=0,即行索引个维度上进行重排序。
8. 计算指标/哑变量——get_dummpies方法
在统计建模和机器学习中常常将分类变量转化为哑变量,使用的是pandas的 get_dummpies方法,
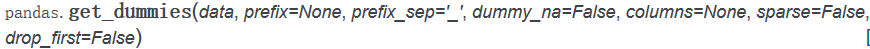
这个方法尤其是在分类问题时很重要,
离散变量
对于离散特征的编码分为两种情况:
1、离散特征的取值之间没有大小的意义,比如color:[red,blue],那么就使用one-hot编码
2、离散特征的取值有大小的意义,比如size:[X,XL,XXL],那么就使用数值的映射{X:1,XL:2,XXL:3}
使用pandas可以很方便的对离散型特征进行one-hot编码。


连续变量
对于连续型变量而言,可以使用 get_dummpies方法与 cut方法的结合使用将其转换为哑变量,
