一、问题说明
共享单车在国内发展时间虽然不算长,但是在国外已经发展不算短了。单车共享系统是一种租赁自行车的方法,使用者租车及还车是通过各个站点网络自动完成,便利大家的生活,本数据来源于Kaggle比赛,本文的目的在于记录数据分析的学习历程。
数据变量说明:
- datatime 日期+时间
- season 1=春 2=夏 3=秋 4=冬
- holiday 1=节假日 0=非节假日
- workingday 1=工作日 0=周末
- weather 1=晴天多云 2=雾天阴天 3=小雪小雨 4=大雨大雪大雾
- temp 气温摄氏度
- atemp 体感温度
- humidity 湿度
- windspeed 风速
- casual 非注册用户个数
- registered 注册用户个数
- count 给定日期时间(每小时)总租车人数
二、数据准备
导入必要的数据包:
1 #导入处理数据包 2 import numpy as np 3 import pandas as pd 4 from datetime import datetime 5 import matplotlib.pyplot as plt 6 import seaborn as sns
导入数据:
1 train=pd.read_csv('train_bike.csv') 2 test=pd.read_csv('test_bike.csv')
这里采用的是相对路径,若是在不同的文件夹下,需使用绝对路径。
查看数据的整体情况:
#数据集大小 print("train:",train.shape) print("test:",test.shape) #查看数据集整体确实情况 print(train.info()) print(test.info())
train: (10886, 12) test: (6493, 9) <class 'pandas.core.frame.DataFrame'> RangeIndex: 10886 entries, 0 to 10885 Data columns (total 12 columns): datetime 10886 non-null object season 10886 non-null int64 holiday 10886 non-null int64 workingday 10886 non-null int64 weather 10886 non-null int64 temp 10886 non-null float64 atemp 10886 non-null float64 humidity 10886 non-null int64 windspeed 10886 non-null float64 casual 10886 non-null int64 registered 10886 non-null int64 count 10886 non-null int64 dtypes: float64(3), int64(8), object(1) memory usage: 1020.6+ KB None <class 'pandas.core.frame.DataFrame'> RangeIndex: 6493 entries, 0 to 6492 Data columns (total 9 columns): datetime 6493 non-null object season 6493 non-null int64 holiday 6493 non-null int64 workingday 6493 non-null int64 weather 6493 non-null int64 temp 6493 non-null float64 atemp 6493 non-null float64 humidity 6493 non-null int64 windspeed 6493 non-null float64 dtypes: float64(3), int64(5), object(1) memory usage: 456.6+ KB None
#查看数据整体情况 train.describe()
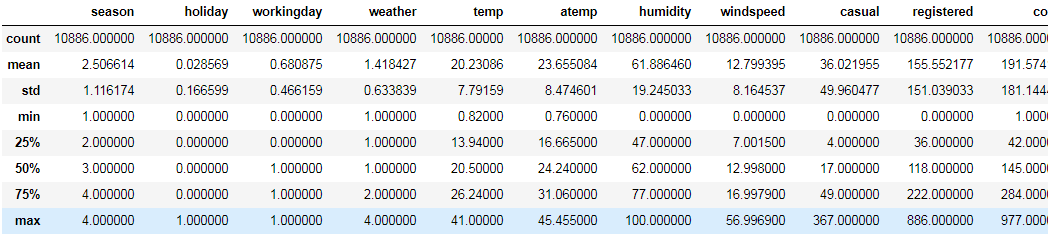
可以看到,count,registered数值分布差异比较大,通过画图来直观的看看数据的分布情况:
#观察数密度分布 fig = plt.figure() ax = fig.add_subplot(1, 1, 1) fig.set_size_inches(5,4) sns.distplot(train['count'],color="g") ax.set(xlabel='count',title='Distribution of count') sns.set_style("dark") ax.grid() plt.savefig('count.jpg') plt.show()

1 #观察数密度分布 2 fig = plt.figure() 3 ax = fig.add_subplot(1, 1, 1) 4 fig.set_size_inches(5,4) 5 sns.distplot(train['registered'],color="red") 6 ax.set(xlabel='registered',title='Distribution of registered') 7 sns.set_style("dark") 8 ax.grid() 9 plt.savefig('reg.jpg') 10 plt.show()
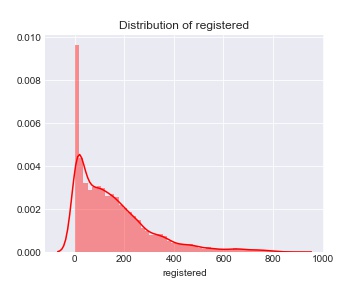
数据偏斜比较严重,去掉3倍标准差以外的数据:
1 #去掉3倍标准差以外的数据 2 train_1 = train[np.abs(train['count']-train['count'].mean())<=(3*train['count'].std())] 3 train_1 .shape 4 #去掉3倍标准差以外的数据 5 train_2 = train_1[np.abs(train['registered']-train['registered'].mean())<=(3*train['registered'].std())] 6 train_2 .shape
(10739, 12)
(10648, 12)
处理之后,我们看看数据的分布情况
1 #处理前后对比 2 fig = plt.figure() 3 ax1 = fig.add_subplot(1, 2, 1) 4 ax2 = fig.add_subplot(1, 2, 2) 5 fig.set_size_inches(10,6) 6 7 sns.distplot(train['count'],ax=ax1) 8 sns.distplot(train_2['count'],ax=ax2) 9 10 ax1.set(title='Distribution of count without outliers',) 11 ax2.set(title='Distribution of count') 12 plt.savefig('reg.jpg') 13 plt.show()

数据仍有很大程度的偏移,通常采用对数化来处理:
1 #进行对对数化 2 train_2count=train_2['count'] 3 train_2count_log=np.log(train_2count) 4 sns.distplot(train_2count_log) 5 plt.show()
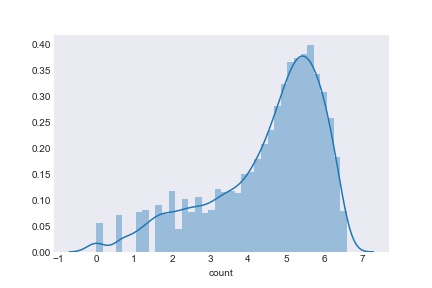
经过对数变换后数据分布更均匀,大小差异也缩小了,使用这样的标签对训练模型是有益的
接下来对其余的数值型数据进行处理,为方便后续分析,我们对时间进行拆分:
#date def get_date(x): dateStr=x.split()[0] dateDT=datetime.strptime(dateStr,"%Y/%m/%d") return dateDT train_2['Date']=train_2.datetime.apply(get_date) #年 def get_Year(x): year=x.split('/')[0] return year train_2['Year']=train_2.datetime.apply(get_Year) #月份 def get_month(x): Month=x.split('/')[1] return Month train_2['Month']=train_2.datetime.apply(get_month) #日 def get_day(x): dateStr=x.split()[0] dateDT=datetime.strptime(dateStr,"%Y/%m/%d") day=dateDT return day train_2['Day']=train_2.datetime.apply(get_day) #小时 def get_hour(x): hour=x.split()[1].split(':')[0] return hour train_2['Hour']=train_2.datetime.apply(get_hour) #星期 def get_weekday(x): date=x.split()[0] date_=datetime.strptime(date,"%Y/%m/%d") weekday=date_.weekday() return weekday train_2['Weekday']=train_2.datetime.apply(get_weekday) print(train_2.head()) print(train_2.info())
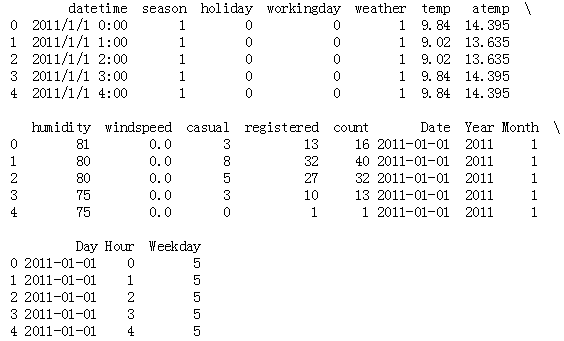
<class 'pandas.core.frame.DataFrame'> Int64Index: 10575 entries, 0 to 10885 Data columns (total 18 columns): datetime 10575 non-null object season 10575 non-null int64 holiday 10575 non-null int64 workingday 10575 non-null int64 weather 10575 non-null int64 temp 10575 non-null float64 atemp 10575 non-null float64 humidity 10575 non-null int64 windspeed 10575 non-null float64 casual 10575 non-null int64 registered 10575 non-null int64 count 10575 non-null int64 Date 10575 non-null datetime64[ns] Year 10575 non-null object Month 10575 non-null object Day 10575 non-null datetime64[ns] Hour 10575 non-null object Weekday 10575 non-null int64 dtypes: datetime64[ns](2), float64(3), int64(9), object(4) memory usage: 1.5+ MB None
我们看到分离的Year,Month,Hour都是object类型,这里将其转变为数值型:
train_2[['Year','Month','Hour']]=train_2[['Year','Month','Hour']].astype(int) print(train_2.info())
然后删掉时间列,同时进行相关性分析
1 #删除datetime列 2 train_2.drop('datetime',axis=1,inplace=True) 3 cor=train_2.corr() 4 5 fig=plt.figure(figsize=(12,12)) 6 sns.set(style='white') 7 sns.heatmap(cor,vmax=0.8,square=True,annot=True) 8 plt.xticks(fontsize=15,color='black',rotation=45) 9 plt.yticks(fontsize=15,color='black') 10 plt.savefig('test2.jpg') 11 plt.show()
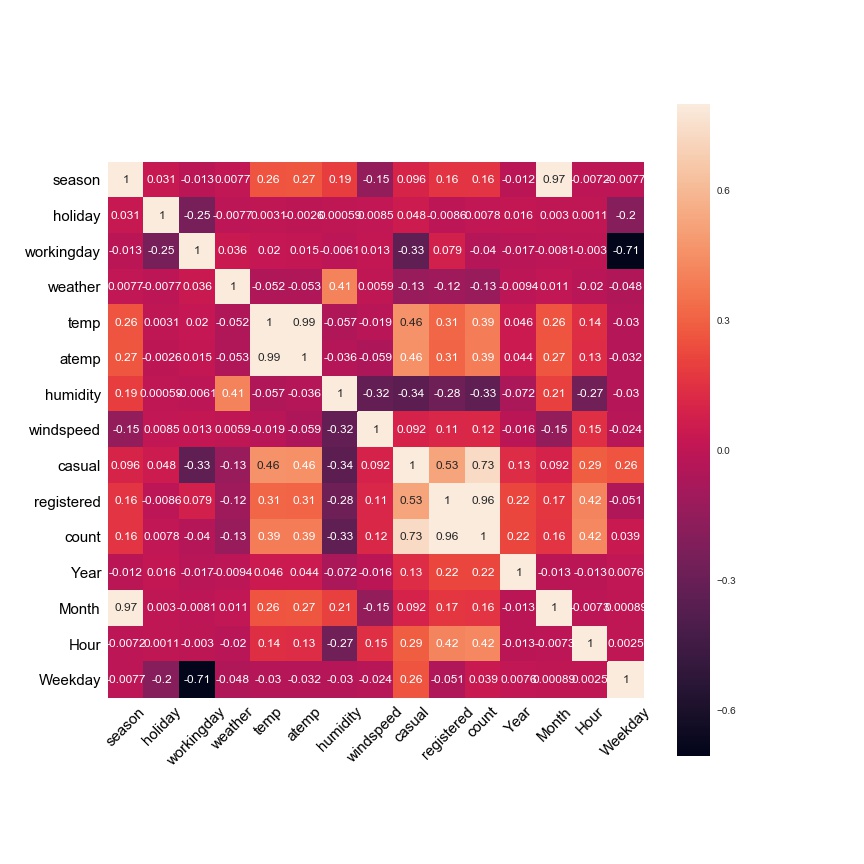
对租赁数量影响进行排序:
cor['count'].sort_values(ascending=False)
count 1.000000 registered 0.964736 casual 0.731193 Hour 0.424267 temp 0.393600 atemp 0.389744 Year 0.218463 Month 0.163407 season 0.159659 windspeed 0.115110 Weekday 0.038969 holiday 0.007783 workingday -0.040445 weather -0.134168 humidity -0.333237 Name: count, dtype: float64
可以看到对租赁数量的影响因素中:时段>温度>湿度>年份>月份等。
下一分部将用可视化对租赁的影响进行进一步分析。