项目描述
共享单车用户使用数据:2016年8月1日至8月31日,有16887名用户使用了共享单车,共计102361条数据
分析思路

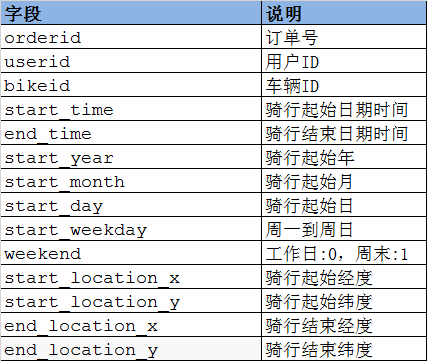
数据字典
读取数据,查看数据情况
data = pd.read_csv('./train.csv',encoding='utf8')
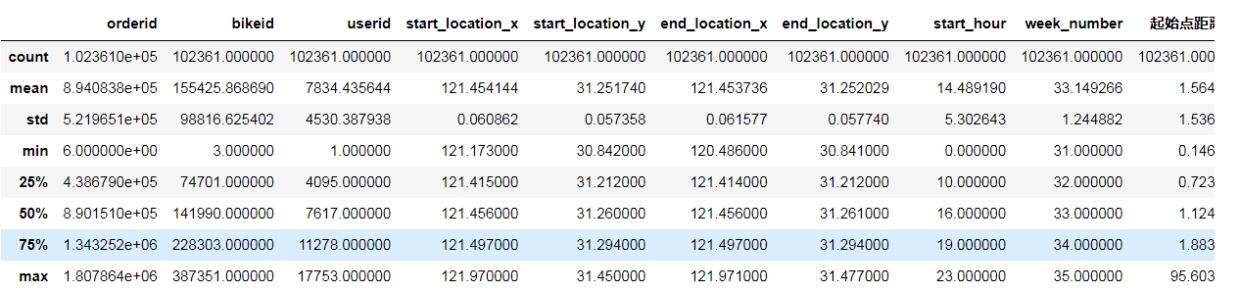
data.describe()
数据处理:
# 将时间列转换一下,加上星期、小时
data.start_time = pd.to_datetime(data.start_time)
data['start_day'] = data.start_time.apply(lambda x:format(x,'%Y-%m-%d'))
data['start_weekday'] = data.start_time.dt.weekday
data['start_hour'] = data.start_time.dt.hour
dict1 = {0:'星期一',1:'星期二',2:'星期三',3:'星期四',4:'星期五',5:'星期六',6:'星期日'}
data['start_weekday'] = data['start_weekday'].map(dict1)
data['week_number'] = data.start_time.dt.week
data['work_day'] = np.where(data['start_time'].dt.weekday<=4,'工作日','周末')
# 将data重新按start_time进行排序
data.sort_values(['start_time'],ascending=True,inplace=True)
每日订单量趋势
df_line = data.groupby(['start_day','start_weekday'])['start_day'].agg({'count'})
x_data = df_line.index
y_data = df_line['count']
day_line = (
Line()
.set_global_opts(
tooltip_opts=opts.TooltipOpts(is_show=False),
xaxis_opts=opts.AxisOpts(type_="category",axislabel_opts=opts.LabelOpts(rotate=45, font_size=8)),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
)
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
series_name="订单数",
y_axis=y_data,
symbol="emptyCircle",
is_symbol_show=True,
label_opts=opts.LabelOpts(is_show=False),
)
.set_global_opts(
# title_opts=opts.TitleOpts(title="每日订单量", pos_left="center"),
# legend_opts=opts.LegendOpts(pos_left="right")
# xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-45))
)
)
day_line.render_notebook()

1.8月份,订单持续增长
2.在第二和第三周,周末的订单量相对于工作日略有下降
订单星期分布,日均订单量对比
# 统计星期一至六的日均订单数
df1 = data.groupby(['start_weekday','start_day'],as_index=False)['orderid'].count()
i = pd.to_datetime(df1.start_day).dt.weekday.argsort() #返回按一个值排序后,这些值对应的索引,series
df1 = df1.iloc[i] #将其按argsort返回的值进行索引排序
weekday_mean = df1.groupby(['start_weekday'],sort=False)['orderid'].mean().reset_index() #sort=False取消自动排序
画图
weekday_mean_plt = (
Bar()
.add_xaxis(weekday_mean.start_weekday.values.tolist())
.add_yaxis("日均订单数", weekday_mean.orderid.values.tolist())
.set_global_opts(
title_opts=opts.TitleOpts(title="订单星期分布"),
# visualmap_opts=opts.VisualMapOpts(is_show=True,
# min_=weekday_mean.orderid.min(),
# max_=weekday_mean.orderid.max(),range_color=['blue','green','red'])
)
# .set_colors([ 'black'])
)
weekday_mean_plt.render_notebook()

从日均订单来看,工作日与周末的差距不明显。然而,需要注意的是,由于订单数量持续上升,这一数据并不能作为定论
订单量小时分布,星期对比
df2 = data.groupby(['start_weekday','start_hour'])['orderid'].count().reset_index()
y_data = [[row['orderid'] for index, row in df2[df2['start_weekday'] == i].iterrows()] for i in df2.start_weekday.drop_duplicates()]
# 创建Line对象
line = Line()
# 添加x轴数据
line.add_xaxis(list(range(24)))
a = ['日','一','二','三','四','五','六']
b = range(0,7)
# 添加y轴数据
for i,t in zip(b,a):
line.add_yaxis(f'星期{t}', y_data[i],label_opts=opts.LabelOpts(is_show=False))
# 设置全局配置项
line.set_global_opts(
title_opts=opts.TitleOpts(title='订单量时间分布'),
xaxis_opts=opts.AxisOpts(name='小时',type_="category"),
yaxis_opts=opts.AxisOpts(name='订单量',type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
tooltip_opts=opts.TooltipOpts(is_show=False),
)
line.render_notebook(
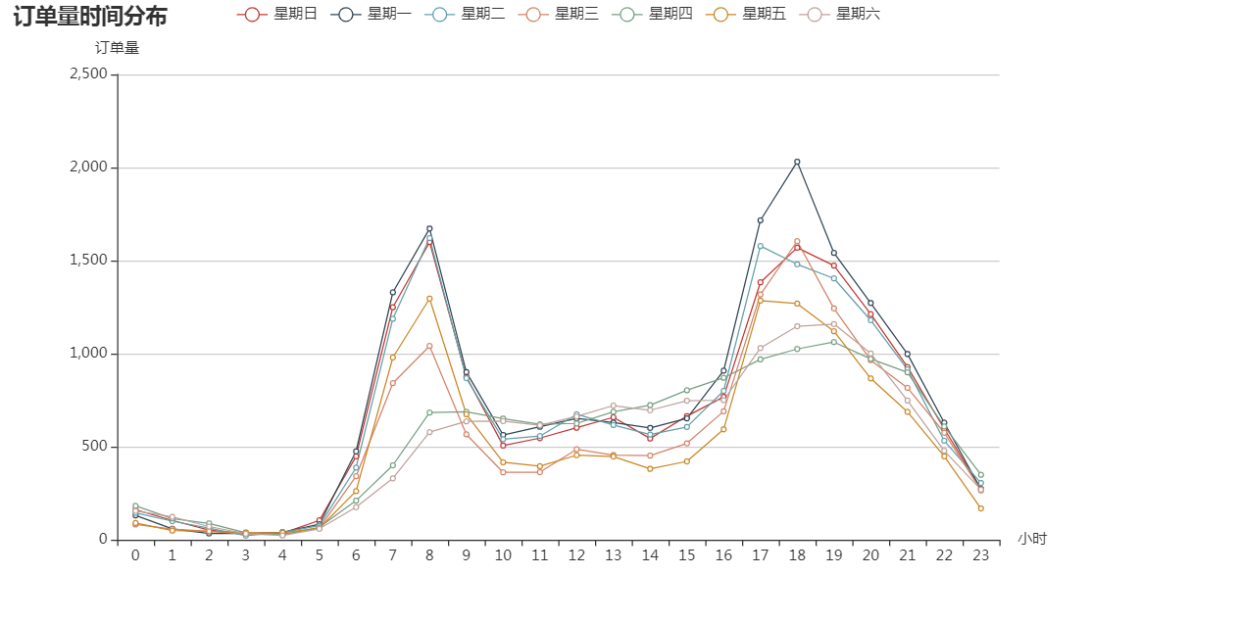
工作日与周末时间订单量趋势差异明显
订单量小时分布,工作日与周末对比
df3 = data.groupby(['work_day','start_hour'])['orderid'].count().reset_index()
x_data = [i for i in range(1,24)]
y_data1 = df3[df3.work_day=='工作日'].orderid
y_data2 = df3[df3.work_day=='周末'].orderid
day_line = (
Line()
.set_global_opts(
tooltip_opts=opts.TooltipOpts(is_show=False),
xaxis_opts=opts.AxisOpts(type_="category"),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
)
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
series_name="工作日",
y_axis=y_data1,
symbol="emptyCircle",
is_symbol_show=True,
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="周末",
y_axis=y_data2,
symbol="emptyCircle",
is_symbol_show=True,
label_opts=opts.LabelOpts(is_show=False),
)
.set_global_opts(
# title_opts=opts.TitleOpts(title="每日订单量"),
# xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-45))
)
)
day_line.render_notebook()
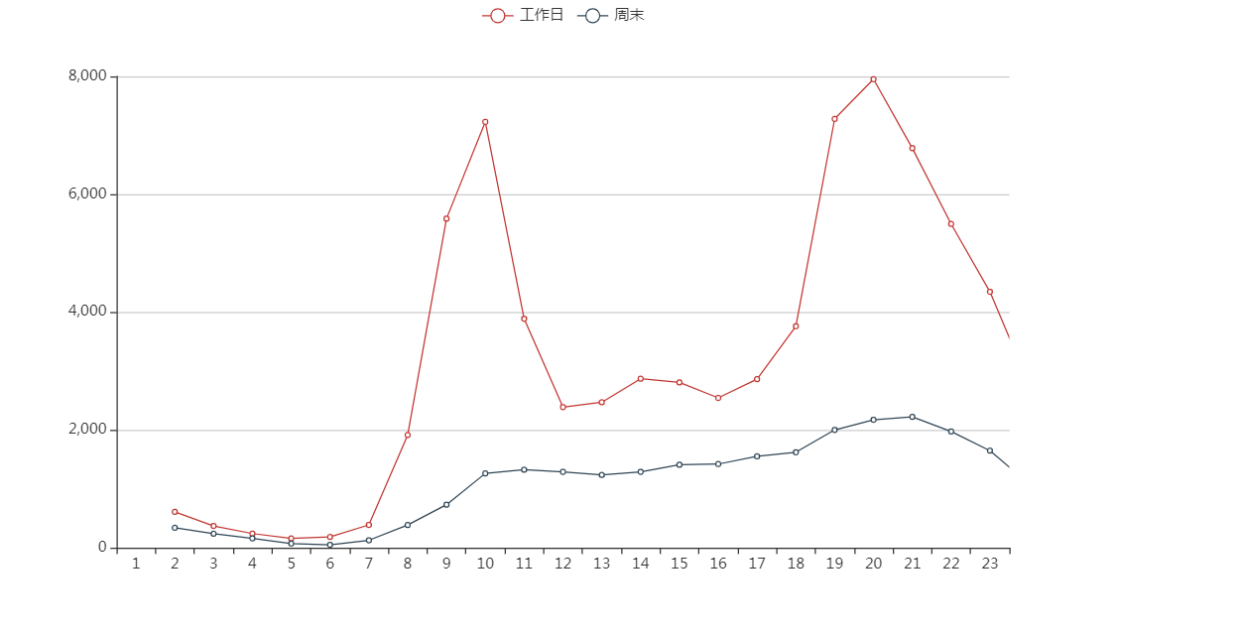
- 工作日订单高峰期在7-9点,16-20点,跟上下班高峰期一致,周末则无明显波动
2.周末白天无明显峰值的外出需求
起始点距离分布占比
数据字段处理
def distance_lan(tup):
x,y,z,p = tup
result = distance.distance((x,y),(z,p)).km
return result
data['起始点距离_2'] = data[['start_location_y','start_location_x',
'end_location_y','end_location_x']].apply(distance_lan,axis=1)
bins = [0,1,3,5,10,np.inf]
labels = ['0-1km','1-3km','3-5km','5-10km','10km以上']
data['cut_km'] = pd.cut(data['起始点距离_2'],bins=bins,labels=labels)
统计与画图
df_pie = data.groupby(['cut_km'],as_index=False)['起始点距离_2'].agg({'起始点距离_2':'count'})
df_pie['占比'] = df_pie['起始点距离_2']/df_pie['起始点距离_2'].sum()
df3 = [ i for i in zip(df_pie['cut_km'],df_pie['占比'])]
pie_dis=(Pie()
.add("起始点距离",df3)
.set_global_opts(title_opts=opts.TitleOpts(title="起始点距离比例分布"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: ({d}%)"))
)
pie_dis.render_notebook()
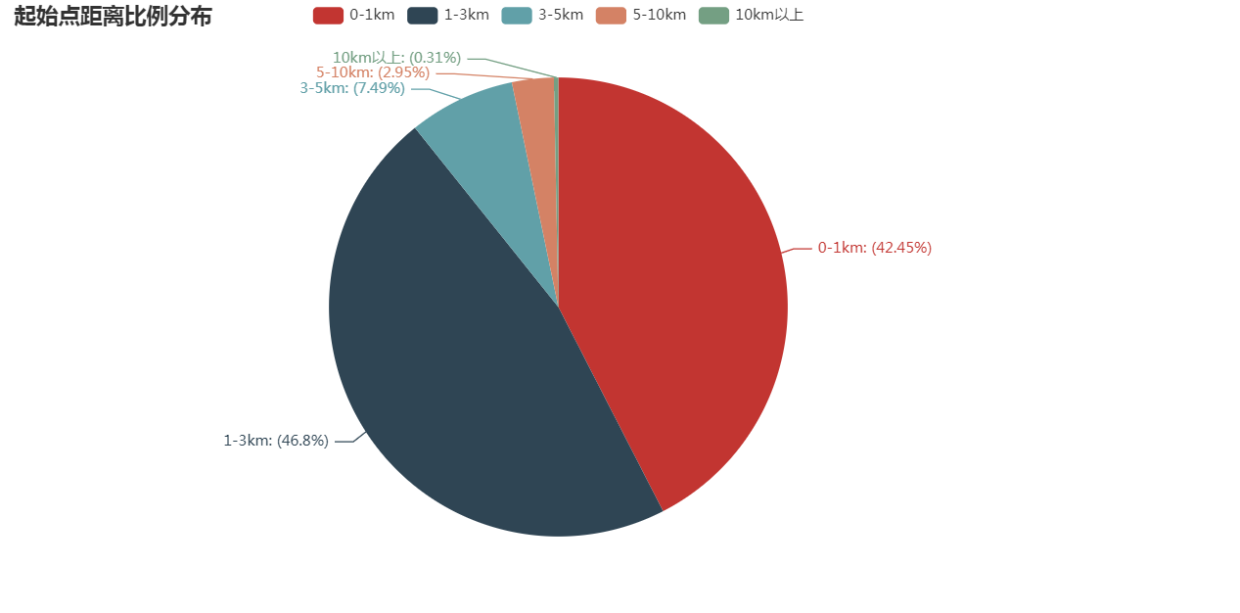
89%的订单都在3km以内
8-9点早高峰单车起点位置分布
df_=data.loc[data.start_hour==18,:].groupby(["start_location_x","start_location_y"])["orderid"].count().reset_index()
df18=list(list(z) for z in zip(df_["start_location_x"],df_["start_location_y"],df_["orderid"]))
bar3D = (
Bar3D()
.add(
"",
df18,
shading='realistic',
grid3d_opts=opts.Grid3DOpts(width="200",depth="200",is_rotate=True),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="8-9点早高峰单车起点位置分布",subtitle="8-9点早高峰单车起点位置分布"),
visualmap_opts=opts.VisualMapOpts(is_show=True, max_=25,
is_piecewise=False,
range_color=Faker.visual_color,
))
)
bar3D.render_notebook()
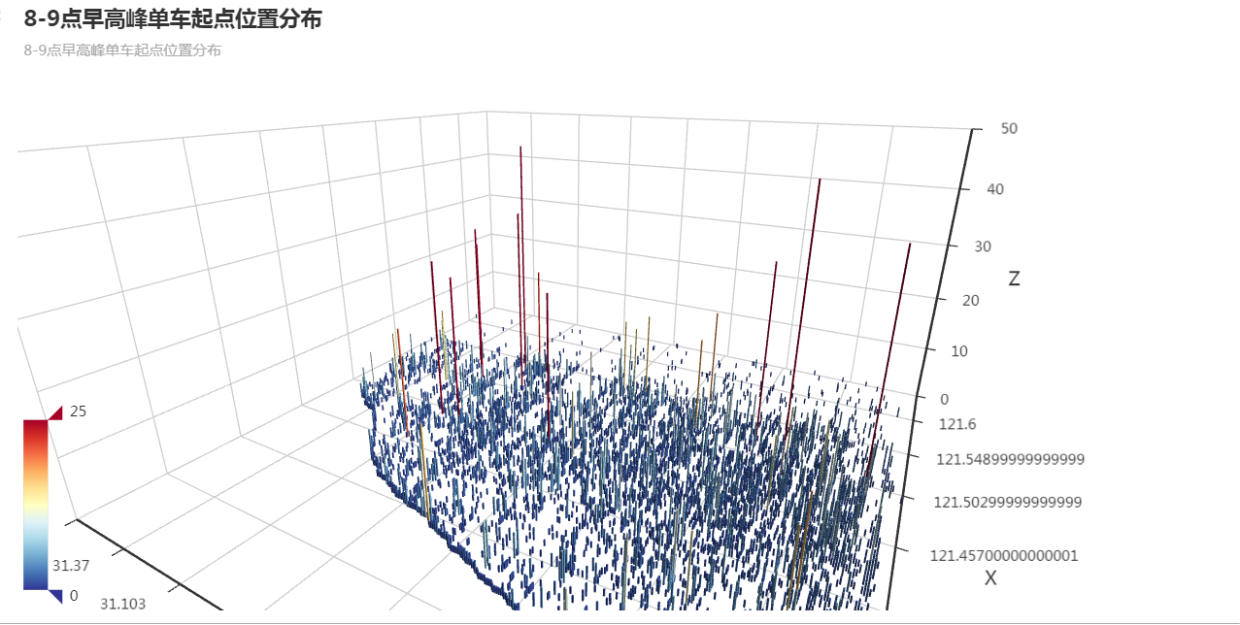
可以针对早晚高峰,提前从需求较少的区域投放车辆至高峰期高需求区域
用户月频次
数据处理
# 用户频次-月
user_df = data.groupby(['userid'],as_index=False)['orderid'].count()
user_df = user_df.groupby(['orderid'],as_index=False)['userid'].count()
bins = [0,3,5,10,np.inf]
user_df['user_cut'] = pd.cut(user_df['orderid'],bins=bins,right=True)
re_user = user_df.groupby(['user_cut'])['userid'].sum().reset_index()
re_user['占比'] = re_user['userid']/re_user['userid'].sum()
re_user['占比'] = re_user['占比'].apply(lambda x:format(x,'.0%'))
# re_user['占比'] = format(float(re_user['占比']),'.0%')
re_user['次数'] =pd.Series(['1-3次','4-5次','6-10次','10次以上'])
画图
# 准备数据
data_x = user_df.orderid.values.tolist()
data_y = user_df.userid.values.tolist()
# 绘制直方图
bar = (
Bar()
.add_xaxis(data_x)
.add_yaxis("用户数", data_y)
.set_global_opts(
xaxis_opts=opts.AxisOpts(name="月频次"),
yaxis_opts=opts.AxisOpts(name="用户数"),
title_opts=opts.TitleOpts(title="用户频次分布直方图-月"),
)
)
bar.render_notebook()
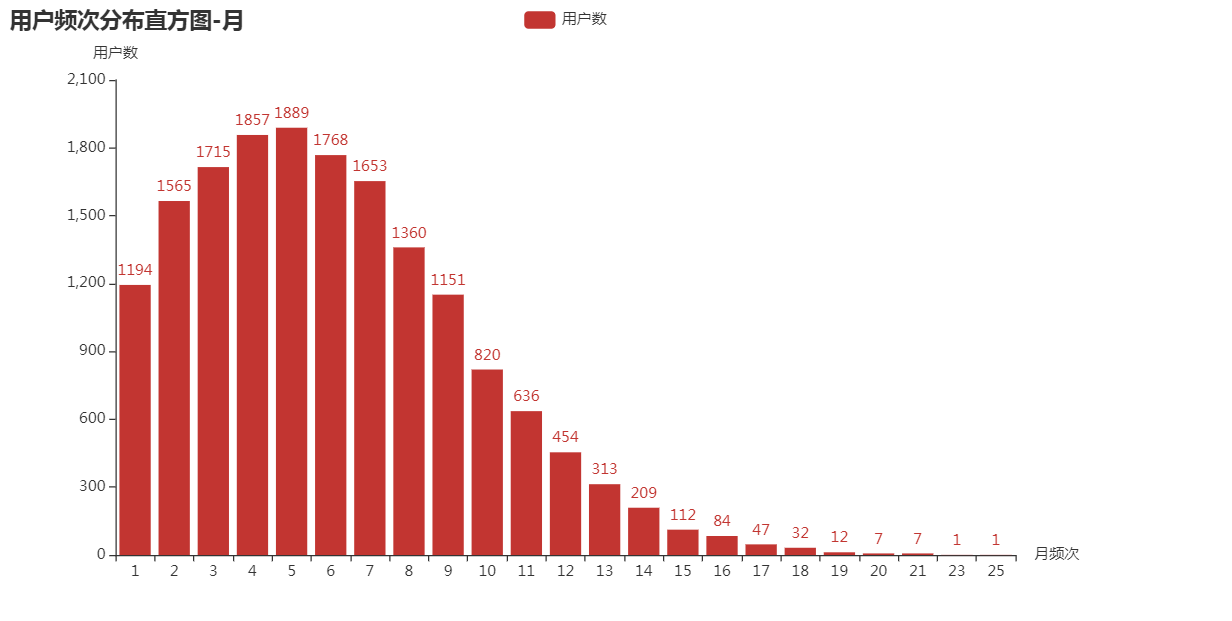
月频分布在2-8次,属于正偏态分布
月频次占比
df5 = [ i for i in zip(re_user['次数'],df_minute_pie['占比'])]
pie_dis=(Pie()
.add("频次占比",df5)
.set_global_opts(title_opts=opts.TitleOpts(title="频次占比"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: ({d}%)"))
)
pie_dis.render_notebook()

周频
# 周频
df7 = data.groupby([ 'week_number','userid'])['orderid'].agg({'count'}).reset_index()
df7 = df7.groupby(['count'])['userid'].agg({'userid':'count'})
画图
# 准备数据
data_x = df7.index.tolist()
data_y = df7.userid.values.tolist()
# 绘制直方图
bar = (
Bar()
.add_xaxis(data_x)
.add_yaxis("用户数", data_y)
.set_global_opts(
xaxis_opts=opts.AxisOpts(name="周频次"),
yaxis_opts=opts.AxisOpts(name="用户数"),
title_opts=opts.TitleOpts(title="用户频次分布直方图-周"),
)
)
bar.render_notebook()

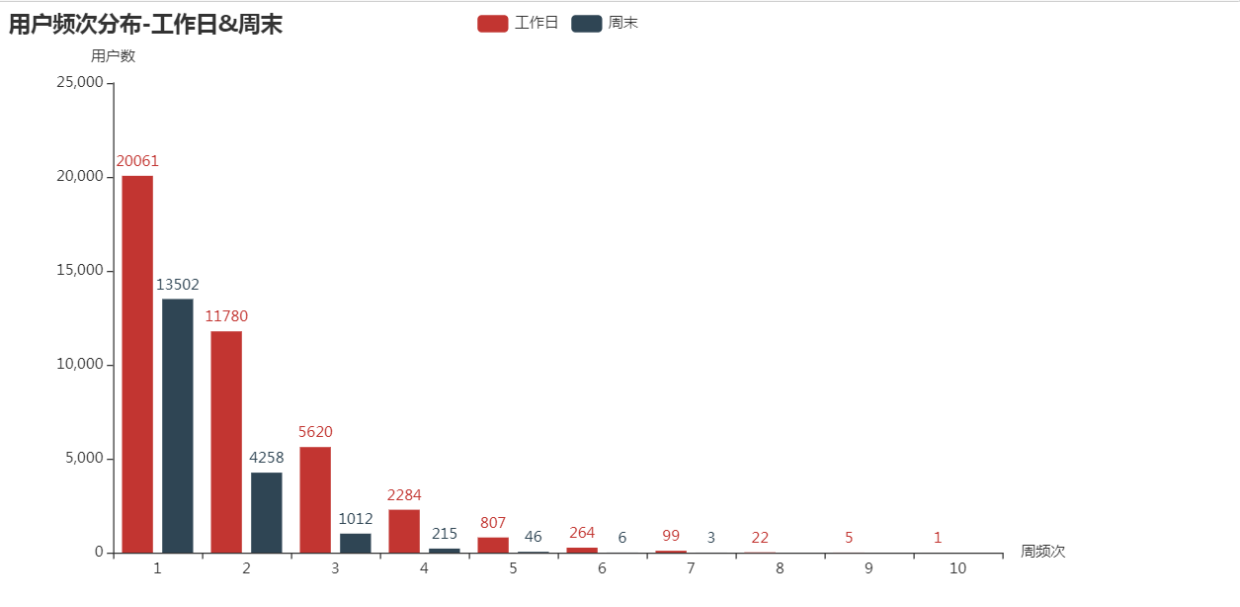
主要为使用1次
# 准备数据
data_x = df8['count'].drop_duplicates().values.tolist()
data_y_1 = df8[df8.work_day=='工作日'].userid.values.tolist()
data_y_2 = df8[df8.work_day=='周末'].userid.values.tolist()
# 绘制直方图
bar = (
Bar()
.add_xaxis(data_x)
.add_yaxis("工作日", data_y_1)
.add_yaxis("周末", data_y_2)
.set_global_opts(
xaxis_opts=opts.AxisOpts(name="周频次"),
yaxis_opts=opts.AxisOpts(name="用户数"),
title_opts=opts.TitleOpts(title="用户频次分布-工作日&周末"),
)
)
bar.render_notebook()
骑行时间
df_minute_pie = data.groupby(['cut_minute'],as_index=False)['minute_bakes'].count()
df_minute_pie['占比'] = df_minute_pie['minute_bakes']/df_minute_pie['minute_bakes'].sum()
df4 = [ i for i in zip(df_minute_pie['cut_minute'],df_minute_pie['占比'])]
pie_dis=(Pie()
.add("骑行时间占比",df4)
.set_global_opts(title_opts=opts.TitleOpts(title="骑行时间分布"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: ({d}%)"))
)
pie_dis.render_notebook()
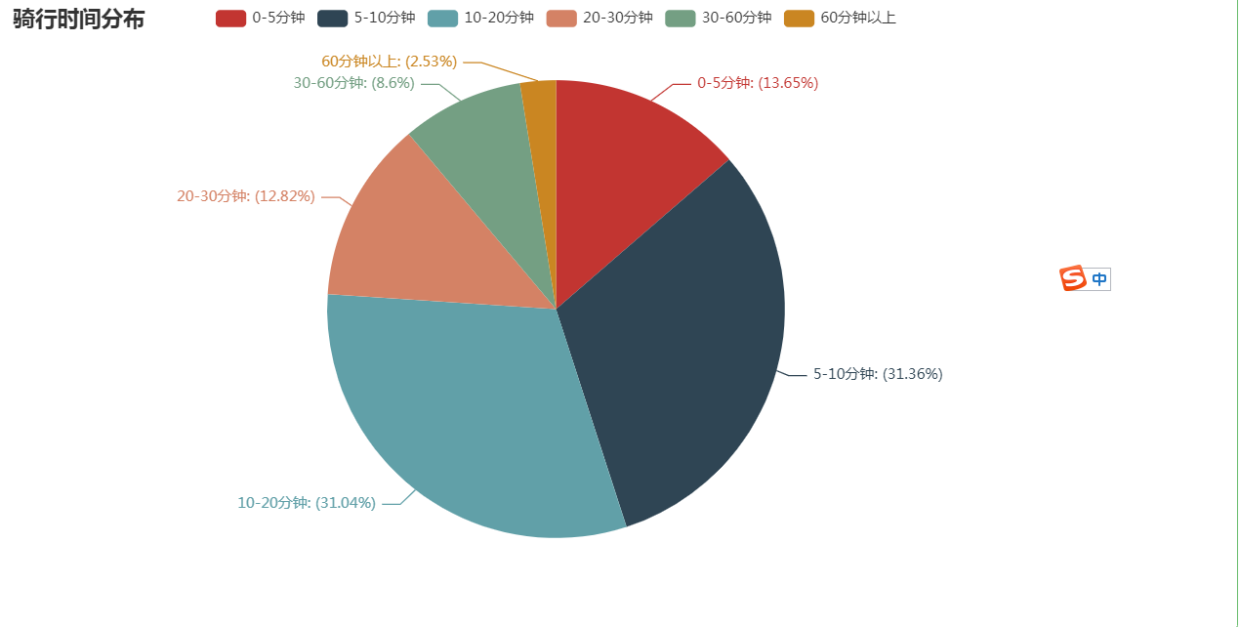
订单主要分布在30分钟以内,占比89%