
有读者在 mysql索引为啥要选择B+树 (上) 上篇文章中留言总结了选择 B+ 树的原因,大体上说对了,今天我们再一起来看看具体的原因。
-
索引为什么要保存在硬盘中
首先要明白几个概念,服务器存储一般分内存和硬盘,内存的大小相对于硬盘来说是很小的。内存的访问速度是纳秒级别的,非常快,而硬盘的访问速度相对内存来说就比较慢了。
不管是访问内存还是硬盘数据,操作系统都是按数据页来读取数据的,即每访问一次硬盘或内存,只读取一页大小的数据,一页的大小约等于 4 kb,向硬盘读取数据的操作叫做磁盘 IO。
看到这里你或许会知道了 mysql 索引为啥不保存在内存中了吧,一方面是虽然内存访问速度快但容量一般都比较小,存不了多少数据,再一个 mysql 需要让数据持久化,如果服务器断电或异常重启会导致数据丢失。
-
怎么让二叉搜索树支持区间查询
上篇文章中提到过二叉搜索树,为了让二叉搜索树也支持区间查询,我们把二叉树的叶子节点通过一个双向链表来连接,并且这个链表是有序的,注意叶子节点和普通节点是不一样的,注意看下面的图。
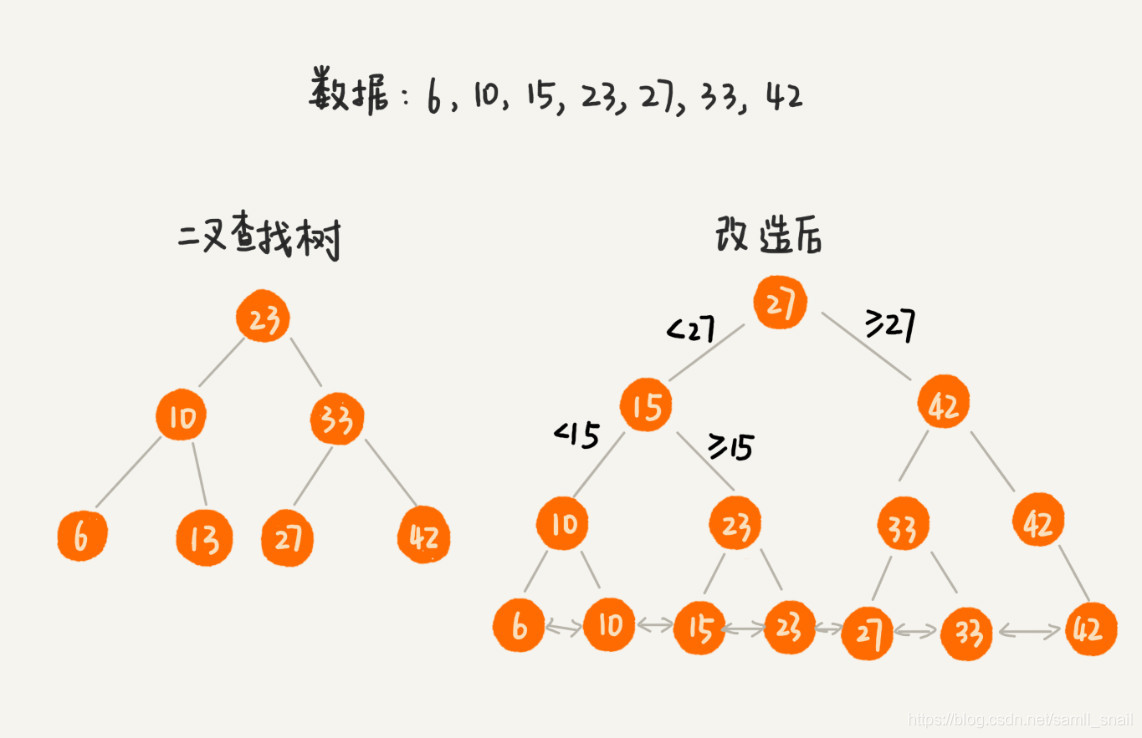
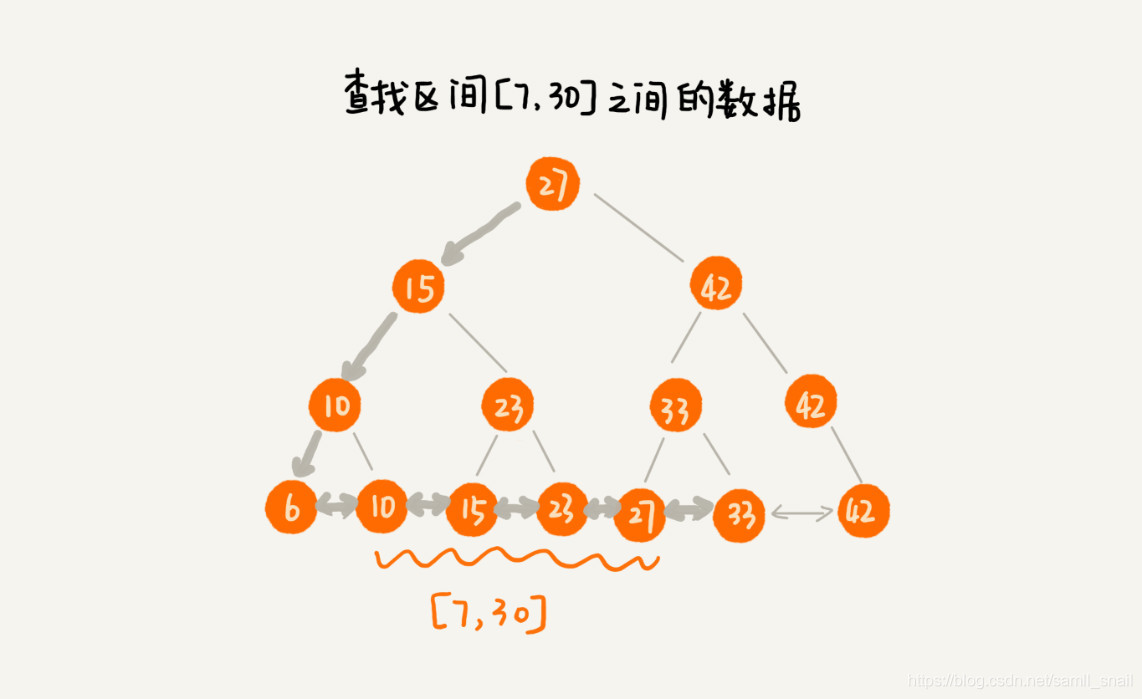
因此只需要先找到区间的起始值在链表中的位置,然后再往后遍历,直到遍历到区间的终止值,即可完成区间查询。如下图查找 7-30 这个区间的数据。
-
如何提升查询速度
因为二叉搜索树保存在硬盘中,我们每访问一个节点,就对应着一次硬盘 IO 操作,上面有说过向硬盘读取数据速度比较慢。因此树的高度就代表硬盘 IO 操作的次数,所以我们要想办法让树的高度变矮,来减少硬盘 IO。
要想树变矮一些,那就把树多分一些叉来吧,变成一颗多叉树。下面分别用二叉树和五叉树来存储 16 条数据,看下树的高度又怎样的变化。
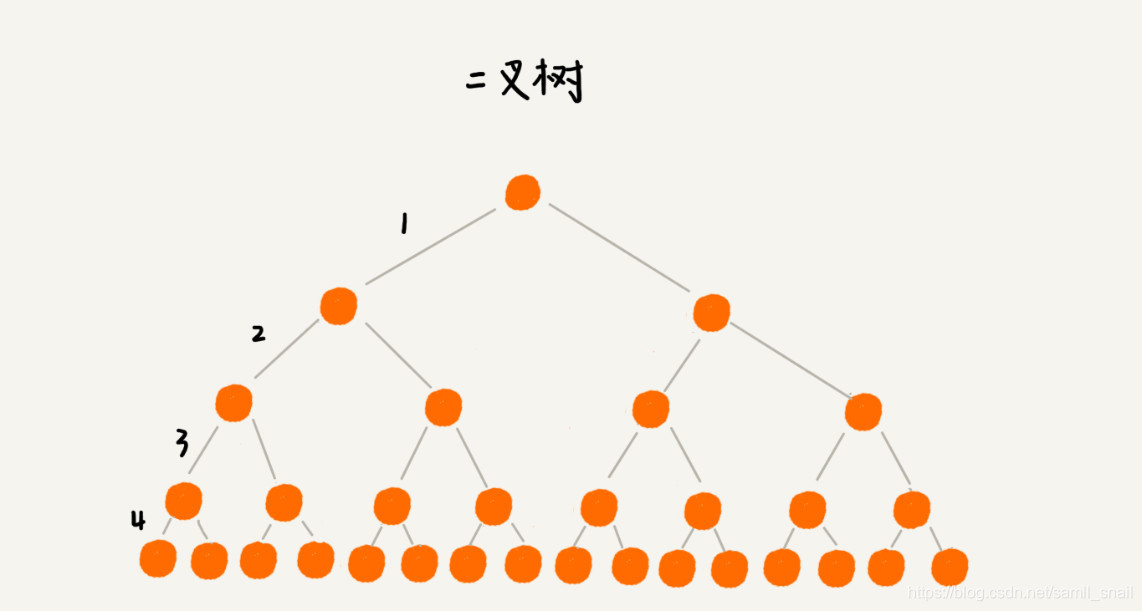
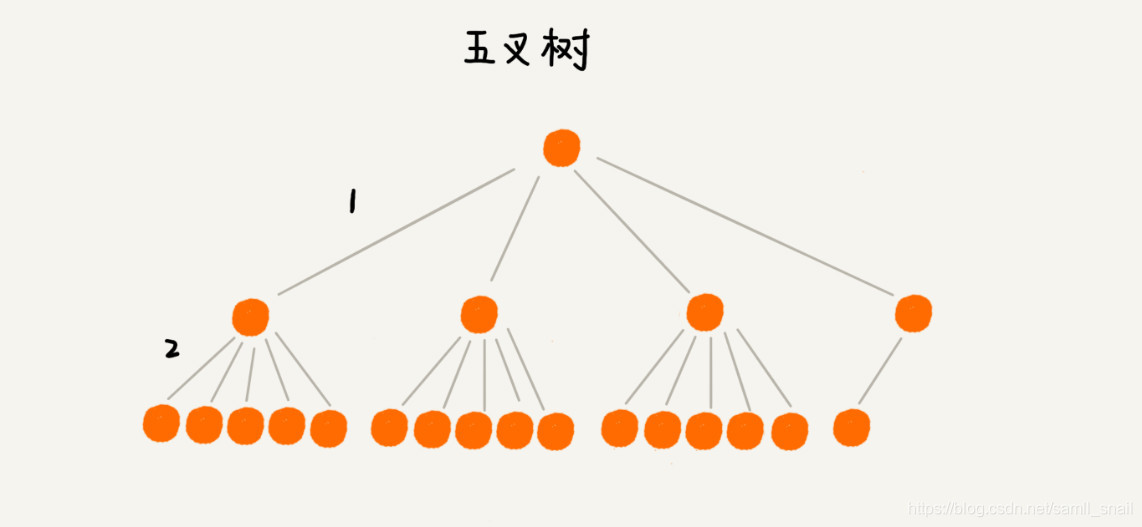
根节点一般存储在内存中,普通节点和叶子结点保存在硬盘中,因此显然二叉树的高度为 5,需要 5 次硬盘 IO,而五叉树的高度为 2,查询一个数据只需要 2 次硬盘 IO。
当然这仅仅是一个小数据的例子,如果有一亿条数据,我们构建一个 100 叉树,这棵树的高度也只有 3,因此多叉树能大大降低硬盘 IO,提升查询速度。
那么问题又来了,对于相同的数据量,是不是构建的多叉树的叉越多越好呢,因为叉越多树的高度就会越矮。
上面有说过操作系是按数据页大小来访问硬盘的,每次 IO 只读取一个数据页大小的数据,如果要读取的数据大于一个数据页,则会导致多次 IO。因此我们要尽量让每个节点的数据大小刚好等于一个数据页大小,即每访问一个节点只需一次 IO。
-
插入和删除数据怎么办
上面讲的其实都是为了提高查询性能的,mysql 通常还有插入和删除操作的,这里我们再简单说一下 B+ 树如何处理插入和删除节点的操作。
这里我们把多叉树称作 m 叉树,这个 m 值是通过数据页大小和节点数计算出来的,尽量保证每访问一个节点就是一个数据页的大小,而且每个节点最多只有 m 个子节点。
现在我们要往数据库中插入新的数据,即要往 m 叉树中插入新的节点,这可能就会导致某些节点的子节点个数大于 m,也就会导致该节点大小大于一个数据页,访问该节点就需要多次 IO。
为了解决这个问题,m 叉树会把该节点分裂成两个节点,然后改分裂操作又会导致其父节点的子节点数可能超过 m,我们再用同样的方法分裂节点,一直影响到根节点。
删除操作也是类似的思想,如果有频繁的删除节点,就会导致某些节点的子节点过少,就会浪费存储空间并降低查询效率。所以就要想办法让这些节点合并起来,合并的话就有可能会导致其子节点数超过 m,超过的话就再用上面的分裂方法分裂子节点。
关于节点分裂和合并操作就简单说这些了,也不画图了,知道这个处理思想就好了。
下面再总结一下 B+ 树:
B+ 树就是一种多叉树,是由二叉搜索树不断演变过来的,为了满足区间快速查询,B+ 树的叶子节点通过双向链表串联起来。
这里使用双向链表是为了支持顺序和倒序查询,虽然双向链表相对于单向链表虽然会浪费一倍的指针空间,但是在硬盘中这点空间几乎微乎其微,用这点空间换时间是一件很值得的事情。
B+ 树的子节点数不超过 m 个,同时也不能少于 m/2 个,一旦超过就需要分裂,一旦少于就需要合并。
关于 mysql InnoDB 引擎为啥要选择 B+ 树就写到这了,文中图片来源于极客时间《数据结构与算法之美》专栏。对文章如有疑问,欢迎留言交流,如文章有描述不当之处,也希望大家批评指出。如文章对你有帮助,点个赞再走哈,感谢支持。