文章目录
摘要:面试题目中经常会出现判断一个元素是否在一个集合中,以垃圾邮件过滤器来说,如果要判断一封邮件是不是垃圾邮件,就要在存储的垃圾邮件地址集合中进行比对,判断该邮件地址在不在集合里。这里就涉及到快速查找,高效存储的问题,从这个问题出发,总结了以下相关的理论名词,便于自己记忆。
在介绍各项内容之前,首先以下图串联所要复习的概念。
- 首先给定要存储的网址,是一个字符串,通过伪随机数产生算法生成信息指纹,这个指纹就可以用来识别这个网址,比直接识别很长的字符串更简洁。
- 根据信息指纹想到了散列表的概念,伪随机数算法产生信息指纹实际上是一种哈希映射的实现方法,使用哈希表的主要原因有两个,1)如果要存储的集合元素是文件或者字符串,不便于用数组存储。2) 能够为集合元素与存储的内容(如信息指纹)建立快速的映射关系,提高查找效率。
- 但是如果垃圾邮件特别多的话,仍然需要很多存储空间,并且散列表的存储效率只有50%,需要的内存空间加倍
- 这时为了进一步节省空间,就有了布隆过滤器,布隆过滤器的实质是,很长的二进制向量和一系列的哈希函数,看完解释会对这个实质有更好的认识。
- 二进制向量也就是位数组,是一种数据存储的方式,效率很高,。

1 . 信息指纹
1.1 信息指纹引入与理解
如果要查找垃圾邮件地址,或者爬虫网络地址,都需要将已知的垃圾邮件地址或者爬到的网址进行存储,然后将新的邮件或者网址与存储的内容进行比对。这样的操作需要特别的大的内存空间。
举例来说,在抓取阶段,爬虫程序为了避免重复抓取,会建立起一张哈希表,将抓取的链接存储。互联网上有5000亿个网页,假定要存储4000亿个网址,如果直接存储网址,一个网址需要(100字符)这需要40TB的空间大小,还有另一个不得不考虑的问题,就是哈希表的存储效率只有50%,这需要80TB,假定一个服务器有100G,这需要800台服务器来存储这个哈希表。
仅仅是存储网址就需要这么多的内存,代价非常大,有咩有什么办法降低数据存储空间呢?这个问题从信息熵开始谈起。
一段文字所包含的信息就是它信息熵,如果对这段信息进行无损压缩编码,理论上编码后的最短长度就是它的信息熵。实际上,编码长度总是略长于信息熵的比特数。但是如果仅仅区分两段文字或者图片【如仅仅需要知道网址是不是存储在集合中】,则不需要很长的编码。任何一段信息(包括文字,语音,视频,图片等),都可以对应一个不太长的随机数,作为区别这段信息和其他信息的指纹。只要算法设计的好,就会如同人类的指纹一样独一无二。信息指纹在加密,信息压缩和处理中有着广泛的应用。【注:信息指纹的理解,还是觉得吴军博士《数学之美》讲的通俗易懂,完整参照第十六章信息指纹。】
总结来说,信息指纹就是:通过提取一个信息的特征,通常是一组词或者一组词+权重,然后根据这组词调用特别的算法(例如MD5算法),将之转化为一组代码,这组代码就是标识这段信息的指纹。
那么信息指纹具体是怎么实现的呢?关键算法是伪随机数产生器算法(prng),比较经典的哈希算法有 MD5 和 SHA1 等,它们可以将不定长的信息变成定长的 128 二进位或者 160 二进位随机数。
在垃圾邮件过滤或者爬取网页的任务中,针对邮件地址或者URL是如何应用信息指纹的呢?因为URL本身就是以整数的方式存储在电脑上的,所以只要设定一个随机函数
,通过这个函数,就可以将这串数字转化为一个独特的且占位要比100个字符少很多的
。如果函数给力,则可以保证每个URL只对应一个唯一的
。这时的这个
,就是这串URL的信息指纹。从这个随机函数或者更好的算法函数可以看到,这其实就是一个哈希映射过程。哈希映射在第二节再多介绍一下。
1.2 信息指纹的用途
《数学之美》关于信息指纹的介绍中,讲解了一些集合判定问题,很有意思,顺便也总结了一下。
1.2.1 集合相同的判定
要判断两个集合是否相同有很多方法,但是效率是不一样的。
方法1:
最直接的方法,就是对两个集合中的元素一一作比较,这时时间复杂度是
。
方法2:
将两个集合的元素分别排序,然后顺序比较,时间复杂度
。
方法3:
将一个集合放在一张散列表中,然后把第二个集合的元素一一和散列表中的元素作对比,时间复杂度为
,达到了最佳,
的时间复杂度是不可能突破的,因为毕竟要扫描一边所有的N个元素。但是该方法额外使用了
的空间,而且代码复杂。
方法4:
完美的方法,计算这两个集合的指纹,集合的指纹可以定义为结合中每个元素指纹的和,加法的交换律保证了集合指纹不会因为元素顺序改变而发生改变,然后直接比较两个集合的信息指纹是否相同,如果两个集合的元素相同,那么他们的指纹一定相同,不需要额外的空间。
1.2.2 判定集合基本相同
发垃圾邮件的人不一定那么傻,每次设置邮件的收信人都是一样的,稍微改变一两个收件人,邮件收信人的集合就不同了,用上述方法判定收信人集合是否相同来判定是否为垃圾邮件就不管用了。这时就需要算法有一定的容错能力,只判断集合基本相同,可以采用相似哈希。相似哈希有很多应用,比如判断文章抄袭,网页抄袭,还有视频反盗版等等。
2. 散列表(哈希表)
为什么要用散列表(哈希表,hashtable)
Hash表不是直接直接把关键字作为数组下标,而是根据关键字计算出下标。-------算法导论
数组是一种支持直接访问的数据结构,使用确定的位置来存储和检索数据,十分高效。对数组操作时,隐含的一个动作是通过特定的规律来确定下标。例如一张图片像素所组成的二维数组中,通过行数
和列数
可以得到二维下标
。
大家对于数列都很熟悉,等比数列,等差数列等都是常用到的数列形式。数组下标本身就是一种数列,只不过这是最简单的顺序递增:“1,2,3,4…”。有一类智力题,是看序列找规律,预测下一个,从逻辑的角度来讲,只要你能自圆其说下一个是什么都有可能(有兴趣可以去看看-电影-牛津大学谋杀案)。而一组随机给出的数列起始位,也是可以预测之后数列的发展,只不过其中的规律特别复杂罢了。实际上寻找的是特征到位置的映射关系。
如果给出一个输入值的集合,包含很多元素,能否按照各个元素的特征找到映射规律使其存放到顺序(存储位置顺序)的数组中呢?Hashtable就是用来解决这个问题的。
对于集合Arr = {23,7,9,1,10},如何才能建立一个快速的映射关系呢?最简单的方式就是取大小为
一个数组,将其存储到对应的位置上,隐含的操作是
,为了存储五个元素,花费了23个存储位置,这显然有些浪费。可不可以让它们的存储得更紧凑一些呢,可以使用
运算很方便的达到这一点:使用
,将得到
,这样我们就可以使用5个位置来存储了。当然数组是我特意挑选的,
也不是唯一的映射方法,这里我们可以看到散列的一个优点将一个大的输入值域,映射到小的输出值域上来,节省空间。
另外一种适用Hashmap的场景是,不能直接获得下标值的情况。例如集合中的元素是文件或者字符串,通过映射,获取hash值确定存储位置(同时达到映射到小集合的目的)。
Hash映射的关系如图所示,
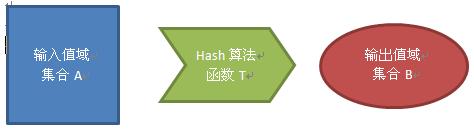
注意以下几点:
- 在完成hash映射之前的集合A的值域一般大于和等于集合B的值域的,但是并不强制。
- 集合A本身的元素个数并不等于其值域,一般要进行预去重处理。
- 集合A的值域有可能是有限的也有可能是无限的,例如正有理数->向下取整->整数。
- 集合B必定有有限的。
- Hashmap一般只支持Insert,Search,Delete这三种操作,因此十分高效,操作的时间复杂度为O(1)。
- 哈希函数具有离散性,能够保证输入域在输出域基本均匀分散
实际的场景要复杂一点,大集合到小集合的映射是有碰撞的风险的。怎样降低这样的风险?碰撞发生了怎样处理?)
数据的题目::【很大一部分都是哈希处理,将大任务分成小任务,然后分成更小的任务】
3 布隆过滤器
如果判断一个单词是否拼写正确(是否在已知的字典中);在FBI,需要核实一个嫌疑人的的名字是否已经在嫌疑人名单上;在爬虫中,需要判断一个网址是否已经访问过,等等。一般来讲,计算机中的集合是使用散列表来存储的,优点是快速准确,缺点是耗费存储空间。
回到原来的问题,像是公众电子邮件提供商,必须设法过滤来自发送垃圾邮件的人的垃圾邮件,一种做法是,记录下那些发送垃圾邮件的Email地址,由于发送者会不断注册新的地址,全世界少说也有几十亿个发送垃圾邮件的地址,将这些都存储起来,需要大量的网络服务器。
即使采用上述提到的信息指纹,散列表进行处理,也是这样。首先将一个电子邮件地址对应成一个8字节的信息指纹,然后将这些信息指纹存入散列表,由于散列表的存储效率一般只有50%,因此一个电子邮件地址需要占用16个字节,那么存储1亿个地址大约需要1.6GB,即16亿字节的内存空间,这对于普通的服务器依然是存储困难的。
布隆过滤器,实质上是一个很长的二进制向量,和一系列随机映射函数。这个实质是重点,具体的实现可能是不一样的,以垃圾邮件地址为例,介绍其工作原理。
假设存储1亿个电子邮件地址,先建立一个16亿个比特位即两亿字节的向量【也就是位数组】,然后将这16亿个比特位全部清零【初始化】。对于每一个电子邮件地址X,用8个不同的随机数产生器
产生8个信息指纹
。再用一个随机数产生器G把这8个信息指纹映射到1-16亿中的8个自然数
。现在把这8个位置的比特位全部设置为1.对这一亿个电子邮件地址都进行这样的处理后,一个针对这些电子邮件地址的布隆过滤器就建成了。

使用布隆过滤器检测可疑的电子邮件地址Y。用相同的8个随机数产生器
对这个地址产生8个信息指纹
,将这8个指纹对应到布隆过滤器的8个比特位,分别是
。如果Y在黑名单中,显然,
对应的8个比特值一定是1。
布隆过滤器不会漏掉黑名单中的任何一个可以地址,但是有极小的可能将一个不在黑名单的电子邮件地址误判,因为可能会被其他的电子邮件地址恰好将这8个位置设置为1。常见的解决方法是再建立一个小的白名单,存储那些可能会被误判的邮件地址。
但是白名单的设置个数也是有多有少的,这和布隆过滤器会造成多大的误差有关。二进制向量的长度
,例子中是16亿,哈希函数个数的选择
,例子中是8,也是根据期望误差P来设置的,同时根据期望误差设置参数的时候会向上取整,实际误差实际上会减小,这些计算都有公式推导。
4. 位数组
布隆过滤器中存储的实际上不是存储整数,而是存储1,0位数据,也就是位数组存储,效率很高。[注:整个部分来自链接]
笔试题:一个 4096位的bit数组,要找出前10个二进制的1 所在的位置,麻烦写一个函数来实现
4.1 位数组的概念
所谓的位数组,主要是为了有效地利用内存空间而设计的一种存储数据的方式。在这种结构中一个整数在内存中用一位(1 bit)表示。这里所谓的表示就是如果整数存在,相应的二进制位就为1,否则为0。
主要思想:我们知道一个 char 类型的数据在内存中占用 1Byte(即 8 bit),如果我们用二进制位在内存中的顺序来代表整数则可以存储更多的信息。这样的话,一个 char 类型可以存储 8个整数。假设 a是一个 char 数组的话,整数8就可以用 a[1] 的第一个二进制位表示了。那么512字节就是4096位,第一位代表0,第二位代表1,第三位代表2,第4096位代表4095,这样我们就可以用512字节存储4096个数了,大大的节省了内存空间。这里的关键就是 一个char型能表示8个整数。[正常存储一个整数需要2个或者4个字节,一个char类型是一个字节,也就是说可以用一个字节存储8个整数,这8个整数本会占用32个字节。可以大大节省存储空间]。
下面实现一种利用 char 数组构造一个二进制数组。主要包括以下三个方面::
将一个整数添加到二进制数组中 :
void add_to_bitarray(char *bitarr, int num){ /* num代表要插进数组中的数 */
bitarr[num >> SHIFT] |= (1 << (num & MASK)); /* MASK 为 0x7 */
}
该方法的主要作用是将二进制数组中表示该整数的位置为1。首先我们得找到该整数位于 char 数组的第几个元组中,这里利用该整数除以8即可(代码中除以8用右移三位实现),例如整数25位于25/8 = 3 余 1,表明该整数是用char 数组的第四个元素的第二位表示。那么在该元素的第几位可以利用该整数的后三位表示(0~7刚好可以表示8个位置),即 25 & 0x7 = 1,则代表25在该元素的第二位。将相应位置1,可以先将整数1左移相应位数,然后与二进制数组进行或操作即可。
判断一个整数是否在二进制数组中
int is_in_bitarray(char *bitarr, int num){
return bitarr[num >> SHIFT] & (1 << (num & MASK));
}
先找到该整数在二进制数组中的位置,然后判断该位是否为1,若是则表示该整数位于二进制数组中,反之不在数组中。
删除二进制数组中的一个整数
void clear_bitarray(char *bitarr, int num){
bitarr[num >> SHIFT] &= ~(1 << (num & MASK));
}
思路相同,先找到该整数在二进制数组中的位置,然后将该位置为0即可。
完整代码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define SHIFT 3
#define MASK 0x7
char *init_bitarray(int);
void add_to_bitarray(char *, int);
int is_in_bitarray(char *, int);
void clear_bitarray(char *, int);
void test(char *);
int main(){
char *arr;
arr = init_bitarray(100);
add_to_bitarray(arr, 25);
test(arr);
clear_bitarray(arr, 25);
test(arr);
getchar();
return 0;
}
char *init_bitarray(int size){
char *tmp;
tmp = (char*)malloc(size / 8 + 1);
memset(tmp, 0, (size / 8 + 1)); //initial to 0
return tmp;
}
void add_to_bitarray(char *bitarr, int num){ /* num代表要插进数组中的数 */
bitarr[num >> SHIFT] |= (1 << (num & MASK));
}
int is_in_bitarray(char *bitarr, int num){
return bitarr[num >> SHIFT] & (1 << (num & MASK));
}
void clear_bitarray(char *bitarr, int num){
bitarr[num >> SHIFT] &= ~(1 << (num & MASK));
}
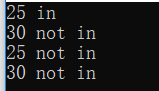
void test(char *bitarr){
if (is_in_bitarray(bitarr, 25) != 0)
printf("25 in\n");
else
printf("25 not in\n");
if (is_in_bitarray(bitarr, 30) != 0)
printf("30 in\n");
else
printf("30 not in\n");
}
以上是对位数组概念的理解,以及如何创建位数组!
在codeblocks 中运行结果如下:
笔试题:一个 4096位的bit数组,要找出前10个二进制的1 所在的位置,麻烦写一个函数来实现。
假设我们这个数组存储的是char类型的512字节,我们利用上面的函数,来构造bit数组,可以往特定的位填1,然后写出函数来查找前10个1所在的位置,并返回位置:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define N_bit 4096
#define SHIFT 3
#define MASK 0x7
char *init_bitarray(int);
void add_to_bitarray(char *, int);
char *init_bitarray(int size){
char *tmp;
tmp = (char*)malloc(size / 8 + 1);
memset(tmp, 0, (size / 8 + 1)); //initial to 0
return tmp;
}
void add_to_bitarray(char *bitarr, int num){ /* num代表要插进数组中的数 */
bitarr[num >> SHIFT] |= (1 << (8 - (num & MASK)));
}
void add_1_to_bitarr(char *bit_arr)
{
add_to_bitarray(bit_arr, 25);
add_to_bitarray(bit_arr, 28);
add_to_bitarray(bit_arr, 23);
add_to_bitarray(bit_arr, 67);
add_to_bitarray(bit_arr, 35);
add_to_bitarray(bit_arr, 36);
add_to_bitarray(bit_arr, 55);
add_to_bitarray(bit_arr, 69);
add_to_bitarray(bit_arr, 44);
add_to_bitarray(bit_arr, 97);
add_to_bitarray(bit_arr, 421);
add_to_bitarray(bit_arr, 564);
add_to_bitarray(bit_arr, 987);
add_to_bitarray(bit_arr, 684);
add_to_bitarray(bit_arr, 986);
add_to_bitarray(bit_arr, 658);
add_to_bitarray(bit_arr, 354);
add_to_bitarray(bit_arr, 764);
add_to_bitarray(bit_arr, 691);
add_to_bitarray(bit_arr, 36);
add_to_bitarray(bit_arr, 345);
}
int main()
{
char *bit_arr;
bit_arr = init_bitarray(4096);
add_1_to_bitarr(bit_arr);
int num[10];
int k = 1;
for (int i = 0; i < N_bit / 8 + 1; i++)
{
for (int j = 1; j < 8 && k <= 10; j++)
{
if ((bit_arr[i] & 128) == 128)
{
num[k] = i * 8 + j + 1;
k++;
}
bit_arr[i] <<= 1;
}
}
for (int n = 1; n <= 10; n++)
{
printf("第%d个1位置为:%d位\n", n, num[n]);
}
//getchar();
return 0;
}
运行结果为:

我们看到前10 个1 的位置都比我们填入到数组中的位置大1,是因为我们认为4096位是从第一个1开始,而数组是从第0号开始,所以产生了偏移!!!