版权声明:本文为博主原创文章,未经博主允许不得转载。https://blog.csdn.net/weixin_44474718/article/details/87441549
贝叶斯分类器易于实现、计算高效并且在相对于较小的数据集上表现非常好。(对于特征太多且相关性较大的分类效果不好)
标准的分类器,比如K邻近算法或者决策树,可能会告诉我们一个从没见过的数据点的目标标签。然而,这些算法对于它们的预测是正确还是错误并没有概念。我们把它们叫作判别模型。另一方面,贝叶斯模型,可以理解数据的潜在概率分布。我们把它们叫作生成模型,因为它们不只是给现有的数据点加上标签——它们还可以使用同样的统计来生成新的数据点。
概率分布:在一个实验中不同事件发生的概率的函数。
理解技巧:如果把数据集看成是一个随机变量X,那么一个机器学习模型基本就是在尝试学习把X映射到一组可能目标标签Y上。换句话说,我们尝试学习条件概率p(Y|X),也就是从X中抽取的随机样本的目标标签是Y的概率。
学习p(Y|X)的两种方法:
判别模型:这类模型直接从训练数据集中学习p(Y|X),而不会浪费时间去尝试理解潜在的概率分布(比如p(X)、p(Y)甚至是p(Y|X))。包括:线性回归、k最近邻、决策树等
生成模型:这类模型学习潜在概率分布的所有情况,然后从联合概率分布p(X,Y)中推断p(Y|X)。因为这些模型知道联合分布p(Y|X),所有它们不仅可以告诉我们一个数据点有一个特定的目标标签的可能性,还可以生成全新的数据点。贝叶斯就是如此。
OpenCv不能提供一个真正的朴素贝叶斯分类器。它提供的贝叶斯分类器并不需要让特征相互独立,而是希望数据已经被聚类成高斯分布。
正态贝叶斯和朴素贝叶斯的区别:朴素贝叶斯的特征是相互独立的。
一、简单贝叶斯分类器实现
from sklearn import datasets
import matplotlib.pyplot as plt
import numpy as np
from sklearn import model_selection as ms
import cv2
from sklearn import metrics
from sklearn import naive_bayes
# 创建练习数据集
X, y = datasets.make_blobs(100, 2, centers=2, random_state=1701, cluster_std=2) # 100个样本,每个样本2个特征,2个中心位置
plt.figure(figsize=(10, 6))
plt.scatter(X[:, 0], X[:, 1], c=y, s=50)
plt.show()
X_train, X_test, y_train, y_test = ms.train_test_split(X.astype(np.float32), y, test_size=0.1)
# 使用正态贝叶斯分类器进行分类
model_norm = cv2.ml.NormalBayesClassifier_create() # 创建分类器
model_norm.train(X_train,cv2.ml.ROW_SAMPLE,y_train) # 训练
_ , y_pred = model_norm.predict(X_test) # 预测
print('正态贝叶斯分类器进行分类:', metrics.accuracy_score(y_test, y_pred))
# 决策边界可视化
def plot_decision_boundary(model, X_test, y_test): # 创建一个可以覆盖所有数据点的网格
h = 0.02 # 网格步长
x_min, x_max = X_test[:, 0].min() - 1, X_test[:, 0].max() + 1
y_min, y_max = X_test[:, 1].min() - 1, X_test[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),np.arange(y_min, y_max, h)) # 返回所有坐标点的x和Y坐标
X_hypo = np.column_stack((xx.ravel().astype(np.float32),yy.ravel().astype(np.float32))) # 最终数据为n行2列,[x,y]
ret = model.predict(X_hypo)
if isinstance(ret, tuple): # OpenCv返回的是多个变量(一个布尔型的true或者false,还有一个预测的目标标签)
zz = ret[1]
else:
zz = ret # sklearn 返回的只有预测的目标标签
zz = zz.reshape(xx.shape) # 表示的是网格中每个点的色彩
plt.contourf(xx, yy, zz, cmap=plt.cm.coolwarm, alpha=0.8)
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_test, s=200)
plt.figure(figsize=(10, 6))
plot_decision_boundary(model_norm, X, y) # 画出决策边界
plt.show()
"""
这个函数返回ret(bool型标志,成功为true,失败表示false),y_pred(预测的目标标签), y_proba(条件概率)
其中,y_proba是一个N*2的矩阵,表示的是对于N个数据点中的每一个数据点,都有一个它被分为类0或者类1的概率
"""
ret, y_pred, y_proba = model_norm.predictProb(X_test)
print(y_proba.round(2)) # 若第一列的值大于第二列的值,说明这个数据点更可能属于第一列。
# 使用朴素贝叶斯分类器进行分类 scikit-learn中提供
model_naive = naive_bayes.GaussianNB() # 创建分类器
model_naive.fit(X_train,y_train) # 训练分类器
print('朴素贝叶斯分类器进行分类:', model_naive.score(X_test,y_test)) # 评分
yprob = model_naive.predict_proba(X_test) # 这个分类器返回的是真正的概率值
print(yprob.round(2)) # 每一行加起来等于1
plt.figure(figsize=(10, 6))
plot_decision_boundary(model_naive, X, y)
plt.show()
# 条件概率可视化
def plot_proba(model, X_test, y_test): # 创建网格
h = 0.02 # 设置步长
x_min, x_max = X_test[:, 0].min() - 1, X_test[:, 0].max() + 1
y_min, y_max = X_test[:, 1].min() - 1, X_test[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),np.arange(y_min, y_max, h))
X_hypo = np.column_stack((xx.ravel().astype(np.float32),yy.ravel().astype(np.float32))) # 把xxyy展平,按列的方法添加到X_hypo
if hasattr(model, 'predictProb'):
_, _, y_proba = model.predictProb(X_hypo) # OpenCv处理
else:
y_proba = model.predict_proba(X_hypo) # sk-learn处理
zz = y_proba[:, 1] - y_proba[:, 0] # 轮廓函数可以简单的理解为是取两个概率值的差值。
zz = zz.reshape(xx.shape)
plt.contourf(xx, yy, zz, cmap=plt.cm.coolwarm, alpha=0.8)
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_test, s=200)
plt.show()
plt.figure(figsize=(10, 6))
plot_proba(model_naive, X, y)
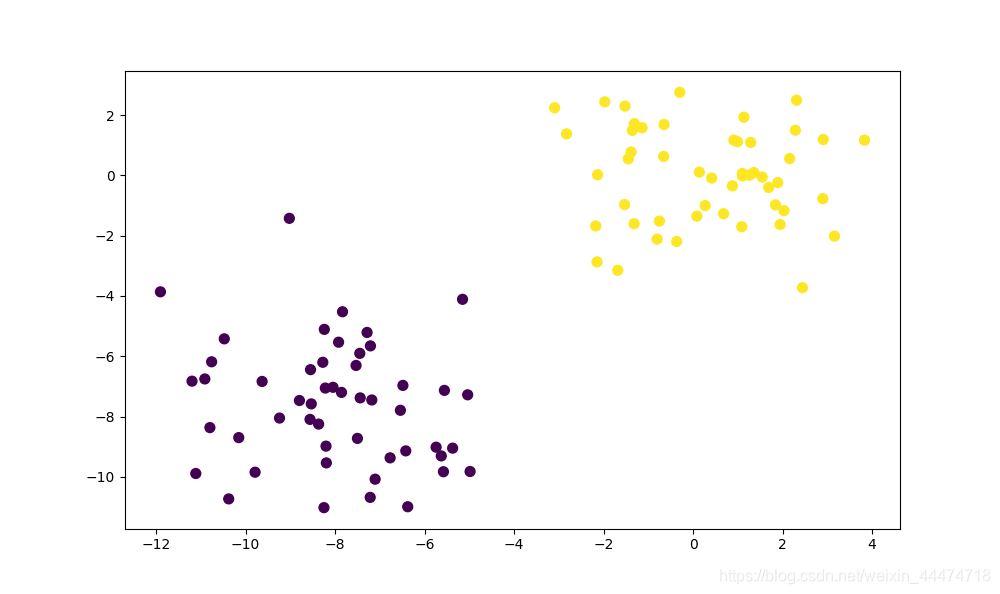
数据集散点图:
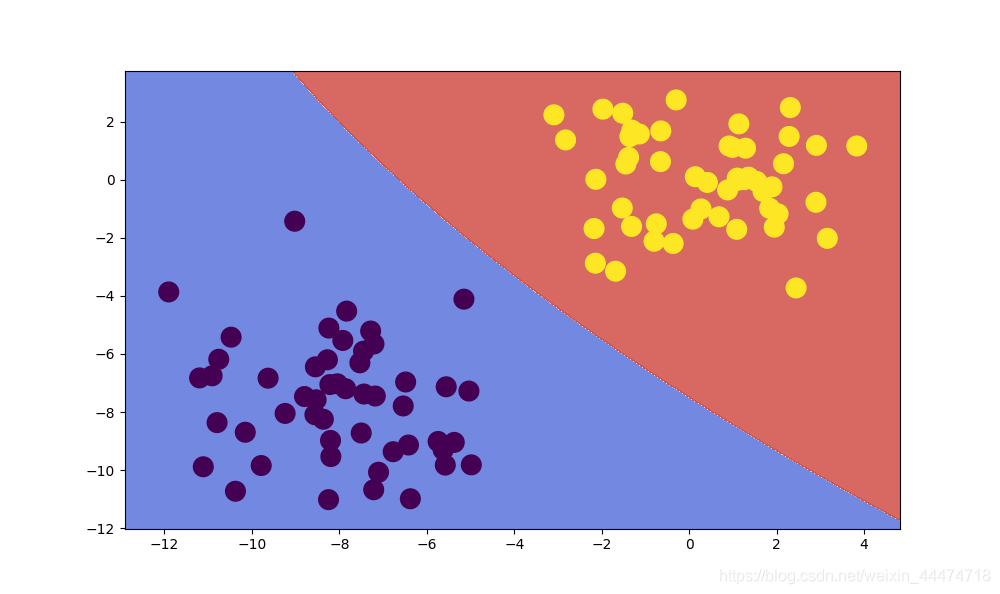
正态贝叶斯分类器决策边界:
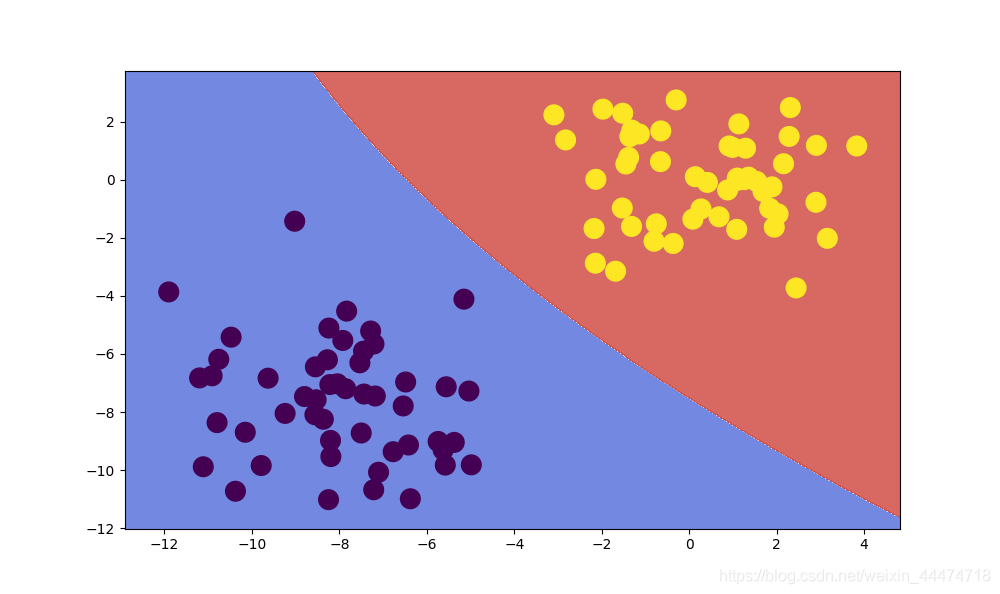
朴素贝叶斯分类器:
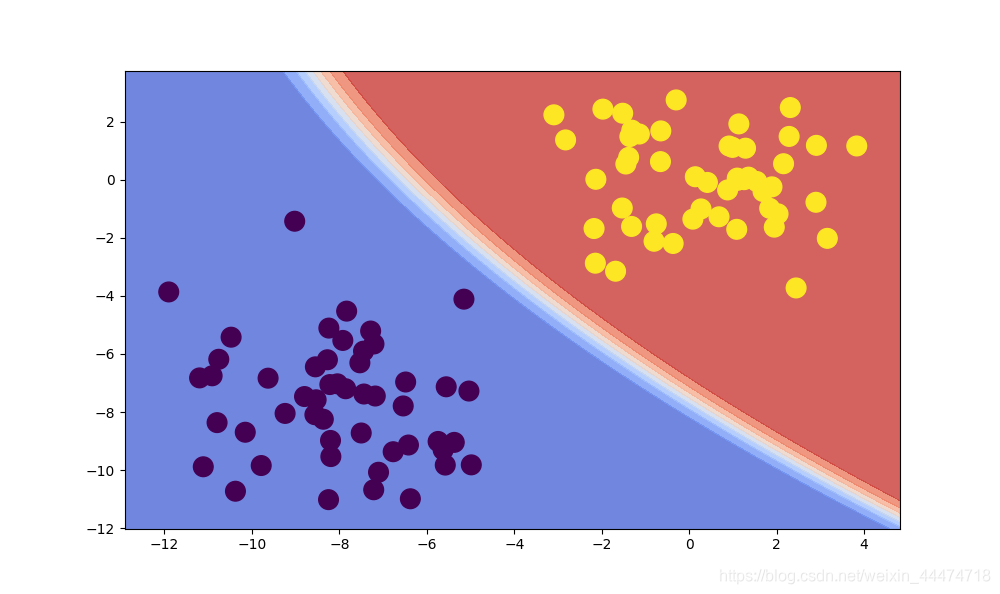
朴素贝叶斯分类器的条件概率:
二、朴素贝叶斯对邮件进行分类
OpenCV不能处理稀疏矩阵(至少与python的接口无法处理),如果把稀疏矩阵转换为一个正常的NumPy数组很可能会消耗完内存。因此,一个可能的方法是仅使用数据的一个子集和特征的一个子集来训练OpenCV分类器。
2.1、使用n-gram提升结果:
朴素贝叶斯的局限性来源于其条件独立假设,它将文本看成是词袋子模型,不考虑词语之间的顺序信息,就会把“武松打死了老虎”与“老虎打死了武松”认作是一个意思。因此,采用N-gram来提升结果。例如1-gram,就是:武、松、打、死、了、老、虎6个词条;6-gram,就是:武松打死了老、松打死了老虎两个词条。
如何选择依赖词的个数n呢?从前人的经验来看:
-
经验上,trigram用的最多。尽管如此,原则上,能用bigram解决,绝不使用trigram。n取≥4的情况较少。
-
当n更大时:对下一个词出现的约束信息更多,具有更大的辨别力;
-
当n更小时:在训练语料库中出现的次数更多,具有更可靠的统计信息,具有更高的可靠性、实用性。
2.2、使用TD-IDF 提升结果
TD-IDF是通过计算单词在整个数据集中出现的频率来对单词计算分配权重。整个方法的一个有用的副效用是IDF部分-单词的逆文档频率。这个部分确保了那些出现频率较高的单词,比如and,the,和but,在分类中仅占很小的权重。
import os
import pandas as pd
from sklearn import feature_extraction
import cv2
import numpy as np
from sklearn import naive_bayes
from sklearn import model_selection as ms
from sklearn import metrics
# 载入数据集
HAM = 0 # 非垃圾邮件
SPAM = 1 # 垃圾邮件
datadir = 'data-new/chapter7'
sources = [('beck-s.tar.gz', HAM), ('farmer-d.tar.gz', HAM),('kaminski-v.tar.gz', HAM),
('kitchen-l.tar.gz', HAM), ('lokay-m.tar.gz', HAM), ('williams-w3.tar.gz', HAM),
('BG.tar.gz', SPAM),('GP.tar.gz', SPAM),('SH.tar.gz', SPAM)]
# 创建解压函数
def extract_tar(datafile, extractdir):
try: # 尝试执行 try 子句, 如果没有错误, 忽略所有的 except 从句继续执行,
import tarfile
except ImportError: # 如果发生异常, 解释器将在这一串处理器(except 子句)中查找匹配的异常。
raise ImportError("You do not have tarfile installed. "
"Try unzipping the file outside of Python.")
tar = tarfile.open(datafile)
tar.extractall(path=extractdir)
tar.close()
print("%s successfully extracted to %s" % (datafile, extractdir))
# 创建for循环解压文件
for source, _ in sources:
datafile = '%s/%s' % (datadir, source)
extract_tar(datafile, datadir)
def read_single_file(filename): # 从一个叫作filename的单个文件中提取相关内容
past_header, lines = False, [] # 定义past_header 为布尔型变量,
if os.path.isfile(filename): # 检测filename这个文件是否存在
f = open(filename, encoding="latin-1") # 存在则一行一行的在这个文件上循环解码(latin-1)
for line in f:
if past_header: # 保存正文部分的数据
lines.append(line)
elif line == '\n': # 经过标题进入正文后
past_header = True
f.close()
content = '\n'.join(lines) # 把所有行连接成一行字符串,使用新的换行符分割
return filename, content # 返回文件的完整路径和实际内容
def read_files(path): # 从一个叫作path的目录中的所有文件中提取相关内容
for root, dirnames, filenames in os.walk(path): # 对一个文件夹中的所有文件进行循环
for filename in filenames:
filepath = os.path.join(root, filename) #
yield read_single_file(filepath) # yield与return类似,yield返回的是一个生成器,
pd.DataFrame({
'model': ['Normal Bayes', 'Multinomial Bayes', 'Bernoulli Bayes'],
'class': ['cv2.ml.NormalBayesClassifier_create()',
'sklearn.naive_bayes.MultinomialNB()',
'sklearn.naive_bayes.BernoulliNB()' ]
} ) # 二维numpy数组的泛化
# print(pd.DataFrame) # 怎么输出表格????
def build_data_frame(extractdir, classification): # 合并前面的函数,在提取的数据中构建一个pd.DataFrame
rows = []
index = []
for file_name, text in read_files(extractdir):
rows.append({'text': text, 'class': classification})
index.append(file_name)
data_frame = pd.DataFrame(rows, index=index)
return data_frame
data = pd.DataFrame({'text': [], 'class': []}) # 调用构建的函数
for source, classification in sources:
extractdir = '%s/%s' % (datadir, source[:-7])
data = data.append(build_data_frame(extractdir, classification))
# 数据预处理
counts = feature_extraction.text.CountVectorizer() # 统计各个单词出现的次数
X = counts.fit_transform(data['text'].values)
print(X.shape) # (52076, 643270) (邮件,单词)
print(X) # X为稀疏矩阵
y = data['class'].values # 这里的value标记可以让我们访问底层的NumPy数组
# 训练正态贝叶斯分类器
X_train, X_test, y_train, y_test = ms.train_test_split(X, y, test_size=0.2, random_state=42)
model_norm = cv2.ml.NormalBayesClassifier_create() # 使用OpenCV建立训练器
# OpenCV无法处理稀疏矩阵,因此使用样本数据的子集来训练
X_train_small = X_train[:1000, :300].toarray().astype(np.float32) # 1000个数据点,300个特征
y_train_small = y_train[:1000]
# model_norm.train(X_train_small, cv2.ml.ROW_SAMPLE, y_train_small) # 使用OpenCV分类器来训练
# 使用完整的数据集进行训练 采用sklearn中的朴素贝叶斯分类器,因为它可以处理稀疏矩阵
X_train, X_test1, y_train, y_test1 = ms.train_test_split(X, y, test_size=0.2, random_state=42)
model_naive = naive_bayes.MultinomialNB() # 最适合处理分类数据,比如单词计数
model_naive.fit(X_train, y_train) # 训练
print("sklearn朴素贝叶斯分类器(训练):", model_naive.score(X_train, y_train)) # 评分
print("sklearn朴素贝叶斯分类器(测试):", model_naive.score(X_test1, y_test1))
# 使用 n-gram 提升结果
counts = feature_extraction.text.CountVectorizer(ngram_range=(1, 2)) # 通过指定 n 的范围,得到指定范围的N-gram特征矩阵
X = counts.fit_transform(data['text'].values)
X_train, X_test2, y_train, y_test2 = ms.train_test_split(X, y, test_size=0.2, random_state=42)
model_naive = naive_bayes.MultinomialNB()
model_naive.fit( X_train, y_train)
print("使用 n-gram 提升结果(测试):", model_naive.score( X_test2, y_test2))
# 使用 词频-逆文档(TD-IDF) 提升结果
tfidf = feature_extraction.text.TfidfTransformer() # 调用TD-IDF
X_new = tfidf.fit_transform(X) # 在特征X矩阵上调用fit_transform
X_train, X_test3, y_train, y_test3 = ms.train_test_split(X_new, y, test_size=0.2, random_state=42)
model_naive = naive_bayes.MultinomialNB()
model_naive.fit(X_train, y_train)
print("使用 TD-IDF 提升结果(测试):", model_naive.score(X_test3, y_test3))
print(metrics.confusion_matrix(y_test3, model_naive.predict(X_test3))) # 对角线表示正确分类,反对角线表示错误分类