数据分析之过滤垃圾邮件
前沿
之前也学了一些数据分析的案例从http://cuijiahua.com/。一直没有记录,所有准备从现在开始把所学的都记录在CSDN中。如果大家看到我的博文有什么不理解或者还想学习更深入的可以去上面的网站。
朴素贝叶斯之过滤垃圾邮件
使用朴素贝叶斯解决一些生活中的问题。先从文本内容得到字符串列表,然后生成词向量。我们看一下使用朴素贝叶斯对电子邮件进行分类的步骤:
- 收集数据:提供文本文件
- 准备数据:将文本文件解析成词条向量
- 分析数据:检查词条却保解析的正确性
- 训练算法:使用我们自己简历的trainNB0()函数
- 测试算法:使用classifyNB0(),并构建一个新的测试函数来计算文档集的错误率。
- 使用算法:构建一个完整的程序对一组文档进行分类,讲错分的文档输出到屏幕上。
1、收集数据
数据已经上传到我的Github:
其中有两个文件夹ham和spam,spam下的txt文件为垃圾邮件
2、准备数据
对于英文文本,我们可以以非字母,非数字作为符号进行切分,使用split函数。代码如下。
import re
"""
函数说明:接收一个大字符串并将其解析为字符串列表
Parameters:
无
Returns:
无
"""
def textParse(bigString): #将字符串转换为字符列表
listOfTokens = re.split(r'\W*', bigString) #将特殊字符作为切分标志进行切分,即非字母,非数字
return [tok.lower() for tok in listOfTokens if len(tok) > 2] #除了单个字母,其他的单词转换为小写
"""
函数说明:将切分的实验样本词条整理成不重复的词条列表,也就是词汇表
Parameters:
dataSet - 整理的样本数据集
Returns:
vocabSet - 返回不重复的词条列表,也就是词汇表
"""
def createVocabList(dataSet):
vocabSet = set([]) #创建一个空的不重复列表
for document in dataSet:
vocabSet = vocabSet | set(document) #取并集
return list(vocabSet)
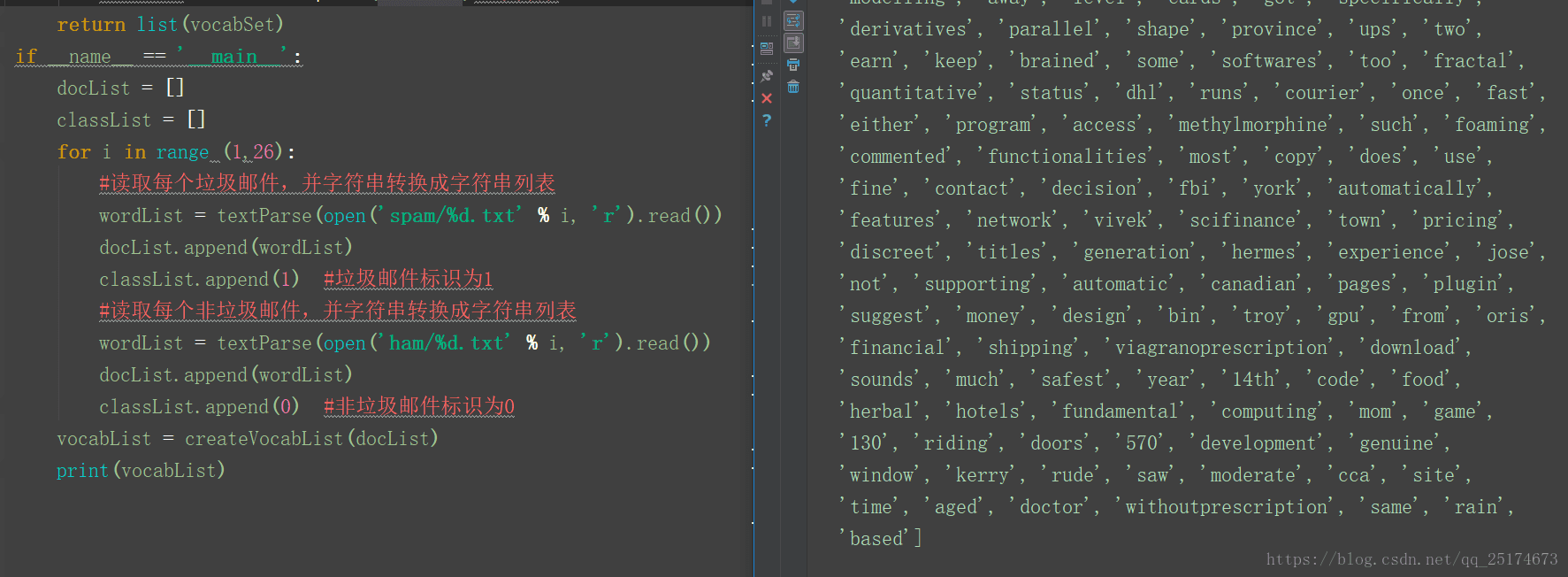
if __name__ == '__main__':
docList = []
classList = []
for i in range (1,26):
#读取每个垃圾邮件,并字符串转换成字符串列表
wordList = textParse(open('spam/%d.txt' % i, 'r').read())
docList.append(wordList)
classList.append(1) #垃圾邮件标识为1
#读取每个非垃圾邮件,并字符串转换成字符串列表
wordList = textParse(open('ham/%d.txt' % i, 'r').read())
docList.append(wordList)
classList.append(0) #非垃圾邮件标识为0
vocabList = createVocabList(docList)
print(vocabList)
运行结果如下图所示:
根据词汇表,我们可以将每个文本向量化。我们将数据集分为训练集和测试集,使用交叉验证的方式测试朴素贝叶斯分类器的准确性。代码如下。