泛化能力
机器学习模型在训练数据集上表现出的误差叫做训练误差
在任意一个测试数据样本上表现出的误差的期望值叫做泛化误差
机器学习既需要降低训练误差,又需要降低泛化误差。
泛化是机器学习本身的核心。简单说,泛化就是在训练数据集上训练好的模型,在测试数据集上表现如何。
泛化误差就是所学习到的模型的风险函数或期望损失
正则化是我们用来防止过拟合的技术。由于我们没有任何关于测试扰动的先验信息,所以通常我们所能做的最好的事情就是尝试训练训练分布的随机扰动,希望这些扰动覆盖测试分布。随机梯度下降,dropout,权重噪音,激活噪音,数据增强,这些都是深度学习中常用的正则化算子
防止过拟合
Early Stopping提前终止
每迭代一定步数之后,我们便计算一些验证集上的存在的误差,当验证集的误差不再降低时,便停止训练。
数据集扩增
扩数据集
正则化
L1正则化和L2正则化都会使得权重矩阵变小,即权重w变小,因此都具有防止过拟合的能力,但不同是L1正则化更易产生系数的权重矩阵,即权重w变小为0;L2正则化只会是w变小但不会出现大量为0现象
偏差、方差、噪声
偏差:度量了模型的期望预测和真实结果的偏离程度,刻画了模型本身的拟合能力。
方差:度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响。
噪声:表达了当前任务上任何模型所能达到的期望泛化误差的下界,刻画了学习问题本身的难度。
核函数
它是针对线性可分情况进行分析,对于线性不可分的情况,通过使用非线性映射算法将低维输入空间线性不可分的样本转化为高维特征空间使其线性可分,从而使得高维特征空间采用线性算法对样本的非线性特征进行线性分析成为可能。
计算样本在高维空间的内积。

核函数必须是连续的,对称的,并且最优选地应该具有正(半)定Gram矩阵

如果特征的数量大到和样本数量差不多,则选用LR或者线性核的SVM;
如果特征的数量小,样本的数量正常,则选用SVM+高斯核函数;
如果特征的数量小,而样本的数量很大,则需要手工添加一些特征从而变成第一种情况。
最小二乘
最小二乘法跟梯度下降法都是通过求导来求损失函数的最小值
实现方法和结果不同:最小二乘法是直接对\Delta求导找出全局最小,是非迭代法。而梯度下降法是一种迭代法,先给定一个,然后向\Delta下降最快的方向调整,在若干次迭代之后找到局部最小。梯度下降法的缺点是到最小点的时候收敛速度变慢,并且对初始点的选择极为敏感,其改进大多是在这两方面下功夫。
梯度下降
梯度即函数在某一点最大的方向导数,函数沿梯度方向函数有最大的变化率。

α在梯度下降算法中被称作为学习率或者步长,意味着我们可以通过α来控制每一步走的距离
梯度前加一个负号
批量梯度下降算法(Batch Gradient Descent)
每次使用全量的训练集样本来更新模型参数。具体做法是:每次使用全部训练集样本计算损失函数loss_function的梯度params_grad,然后使用学习速率learning_rate朝着梯度相反方向去更新模型的每个参数params。
优点:
每次更新都会朝着正确的方向进行,最后能够保证收敛于极值点(凸函数收敛于全局极值点,非凸函数可能会收敛于局部极值点)
缺点:
每次学习时间过长,并且如果训练集很大以至于需要消耗大量的内存,并且全量梯度下降不能进行在线模型参数更新。
随机梯度下降算法(Stochastic Gradient Descent)
随机梯度下降算法每次从训练集中随机选择一个样本来进行学习
优点:
每次只随机选择一个样本来更新模型参数,因此每次的学习是非常快速的,并且可以进行在线更新(得到了一个样本,就可以执行一次参数更新)。

缺点:
每次更新可能并不会按照正确的方向进行,因此可以带来优化波动(扰动)。由于波动,因此会使得迭代次数(学习次数)增多,即收敛速度变慢。不过最终其会和全量梯度下降算法一样,具有相同的收敛性,即凸函数收敛于全局极值点,非凸损失函数收敛于局部极值点(随机梯度下降所带来的波动有个好处就是,对于类似盆地区域(即很多局部极小值点)那么这个波动的特点可能会使得优化的方向从当前的局部极小值点跳到另一个更好的局部极小值点,这样便可能对于非凸函数,最终收敛于一个较好的局部极值点,甚至全局极值点。 )。
小批量梯度下降算法(Mini-batch Gradient Descent)
小批量选择了折中的办法,每次选择m个样本进行学习
相对于随机梯度下降,Mini-batch梯度下降降低了收敛波动性,即降低了参数更新的方差,使得更新更加稳定。相对于全量梯度下降,其提高了每次学习的速度。并且其不用担心内存瓶颈从而可以利用矩阵运算进行高效计算。
梯度下降算法的问题
不能保证全局收敛
梯度下降算法针对凸优化问题原则上是可以收敛到全局最优的,因为此时只有唯一的局部最优点。而实际上深度学习模型是一个复杂的非线性结构,一般属于非凸问题,这意味着存在很多局部最优点(鞍点),采用梯度下降算法可能会陷入局部最优。
学习率问题
选择一个合适的学习率很难
如果学习速率过小,则会导致收敛速度很慢。如果学习速率过大,那么其会阻碍收敛,即在极值点附近会振荡。
学习速率调整无法自适应
学习速率调整(又称学习速率调度,Learning rate schedules)试图在每次更新过程中,改变学习速率,如退火。一般使用某种事先设定的策略或者在每次迭代中衰减一个较小的阈值。无论哪种调整方法,都需要事先进行固定设置,这边便无法自适应每次学习的数据集特点。
模型所有的参数每次更新都是使用相同的学习速率
模型所有的参数每次更新都是使用相同的学习速率。如果数据特征是稀疏的或者每个特征有着不同的取值统计特征与空间,那么便不能在每次更新中每个参数使用相同的学习速率,那些很少出现的特征应该使用一个相对较大的学习速率
原文:https://blog.csdn.net/zxfhahaha/article/details/81385130
岭回归
在处理复杂的数据的回归问题时,普通的线性回归会遇到一些问题,主要表现在:
预测精度:这里要处理好这样一对为题,即样本的数量和特征的数量
 时,最小二乘回归会有较小的方差
时,最小二乘回归会有较小的方差
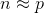 时,容易产生过拟合
时,容易产生过拟合
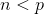 时,最小二乘回归得不到有意义的结果
时,最小二乘回归得不到有意义的结果

感知器
感知器是一种研究单个训练样本的二元分类器,训练较大的数据集很有用



逻辑回归 线性回归
回归算法是一种通过最小化预测值与实际结果值之间的差距,而得到输入特征之间的最佳组合方式的一类算法。对于连续值预测有线性回归等,而对于离散值/类别预测,我们也可以把逻辑回归等也视作回归算法的一种。
线性回归与逻辑回归是机器学习中比较基础又很常用的内容。线性回归主要用来解决连续值预测的问题,逻辑回归用来解决分类的问题,输出的属于某个类别的概率,工业界经常会用逻辑回归来做排序。在SVM、GBDT、AdaBoost算法中都有涉及逻辑回归,


激活函数
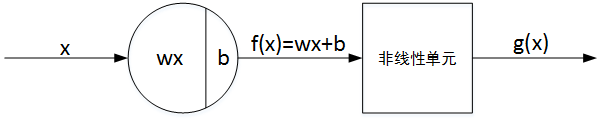
f(x) 即为线性输出 Z,g(x) 即为非线性输出,g() 表示激活函数。通俗来说,激活函数一般是非线性函数,其作用是能够给神经网络加入一些非线性因素,使得神经网络可以更好地解决较为复杂的问题
https://blog.csdn.net/weixin_38997425/article/details/82906942

损失函数
通常机器学习每一个算法中都会有一个目标函数,算法的求解过程是通过对这个目标函数优化的过程。在分类或者回归问题中,通常使用损失函数(代价函数)作为其目标函数。损失函数用来评价模型的预测值和真实值不一样的程度,损失函数越好,通常模型的性能越好
https://blog.csdn.net/qq_24753293/article/details/81016389
https://blog.csdn.net/leo_xu06/article/details/79010218