在机器学习中,有很多的问题并没有解析形式的解,或者有解析形式的解但是计算量很大(譬如,超定问题的最小二乘解),对于此类问题,通常我们会选择采用一种迭代的优化方式进行求解。
这些常用的优化算法包括:梯度下降法(Gradient Descent),共轭梯度法(Conjugate Gradient),Momentum算法及其变体,牛顿法和拟牛顿法(包括L-BFGS),AdaGrad,Adadelta,RMSprop,Adam及其变体,Nadam。
1.梯度下降法
梯度下降法的核心思想就是:通过每次在当前梯度方向(最陡的方向)向前前进一步,来逐渐逼近函数的最小值。类似于你站在山峰上,怎样才能最快的下到山脚呢?当然是选择坡度最陡的方向下山最快,这个坡度最陡正是数学上的“导数”概念,但导数没有方向,对此出来了“梯度”z,所以才叫做“梯度下降法”
首先对于机器学习而言,存在模型函数h(θ),以及损失函数J(θ)
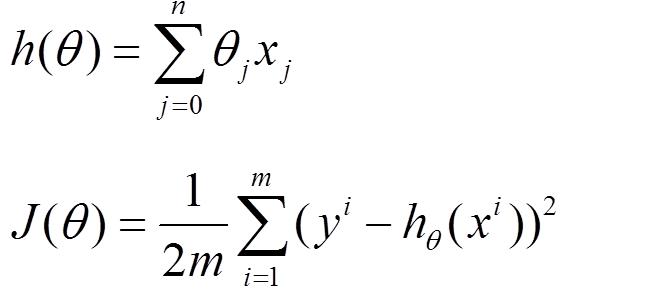
我们将损失函数在θi进行一阶泰勒展开:
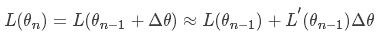
对于大多数博文而言,对应的梯度下降函数会是
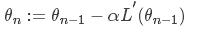
可能大家没有注意到,这里为什么后面变成了负的导数,不应该是正的嘛,这是为什么呢?????其实这里存在的负号很重要
首先,对于损失函数而言,我们的目标是减小损失函数的值,上式中,前面一项不需要解释,后面一项是梯度下降的系数*导数。
损失函数是关于θ的函数,当导数大于0时,损失函数随着θ的减小而减小。对上式而言,此时θ在减小(后面一项小于0),那么相应的损失函数也会相应的减小。
当导数小于0时,损失函数随着θ的增大而减小。对上式而言,此时的θ是在增大的(后面一项大于0),那么相应的损失函数也会相应的减小。
所以这就是为什么这个地方一定是负号,看似简单的数学推到,实则里面蕴藏着数学家很多的心血。