这次我们介绍利用D2RQ开启SPARQL endpoint服务和两种交互方式:在浏览器中进行查询或者编写python脚本进行交互。跳过之前实践篇练习的读者,需要做的准备有:导入数据到Mysql,下载mapping文件(项目地址)。
一、SPARQL endpoint
前一篇介绍SPARQL的文章中提到,SPARQL endpoint是SPARQL协议的一部分,用于处理客户端的请求,可以类比web server提供用户浏览网页的服务。通过endpoint,我们可以把数据发布在网上,供用户查询。
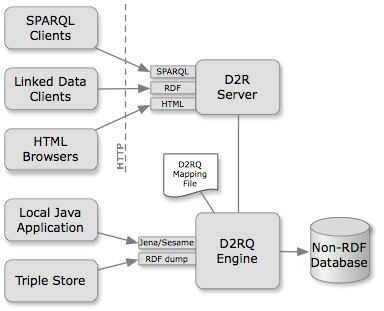
D2RQ,是以虚拟RDF的方式来访问关系数据库中的数据,即我们不需要显式地把数据转为RDF形式。通过默认,或者自己定义的mapping文件,我们可以用查询RDF数据的方式来查询关系数据库中的数据。换个说法,D2RQ把SPARQL查询,按照mapping文件,翻译成SQL语句完成最终的查询,然后把结果返回给用户。下面是D2R Server的架构图:
进入d2rq目录,使用下面的命令启动D2R Server:
d2r-server.bat kg_demo_movie_mapping.ttl“kg_demo_movie_mapping.ttl”是我们定义的mapping文件。其他参数和配置请参考官方文档。默认端口是2020,在浏览器输入“http://localhost:2020/”,可以看到如下界面:

红色方框1是我们定义的类别,点击某个类别,我们可以看到其对应的所有实例(默认显示50个,可以在mapping文件中修改服务器配置)。选中某个实例,可以看到其包含的所有属性,如下图:

点击红色方框2中的链接,进入endpoint,如下图:

二、浏览器中查询
输入框默认的SPARQL查询是获取所有的RDF三元组,“LIMIT”关键词指定返回结果数量的上限。点击下图红框中的“Go!”,执行查询:

读者可以自行尝试上篇文章中的例子:
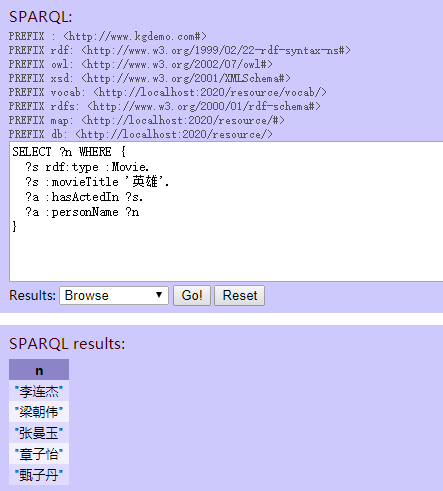
“周星驰出演了哪些电影?”
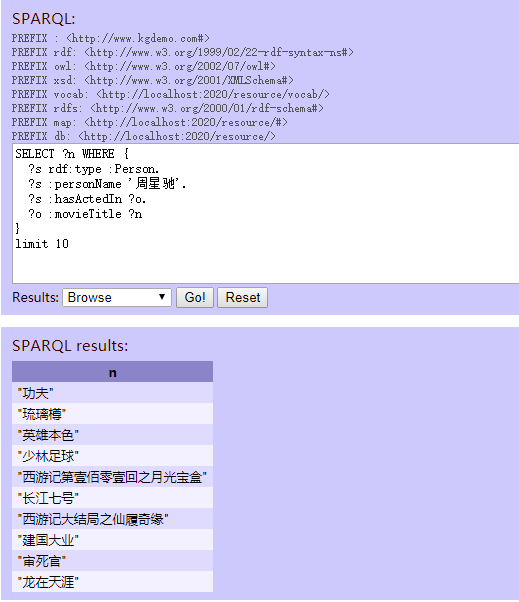
“英雄这部电影有哪些演员参演?”
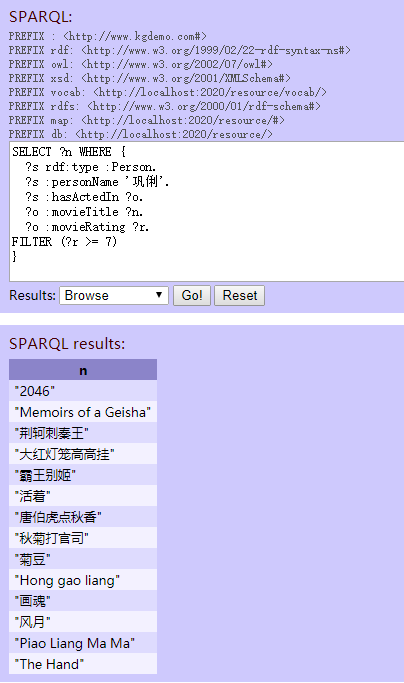
“巩俐参演的评分大于7的电影有哪些?”
读者也可以通过命令行的方式进行查询,具体方法请参考官方的文档。
三、编写Python脚本进行交互
构建基于知识图谱的应用,我们希望将SPARQL查询集成在代码当中,对其进行包装便于后续开发。这里介绍一个Python第三方库:SPARQLWrapper。如其名,这是一个Python下的包装器,可以让我们十分方便地和endpoint进行交互。下面是通过SPARQLWrapper,向D2RQ endpoint发送查询“巩俐参演的评分大于7的电影有哪些”,得到结果的代码。
from SPARQLWrapper import SPARQLWrapper, JSON
sparql = SPARQLWrapper("http://localhost:2020/sparql")
sparql.setQuery("""
PREFIX : <http://www.kgdemo.com#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
SELECT ?n WHERE {
?s rdf:type :Person.
?s :personName '巩俐'.
?s :hasActedIn ?o.
?o :movieTitle ?n.
?o :movieRating ?r.
FILTER (?r >= 7)
}
""")
sparql.setReturnFormat(JSON)
results = sparql.query().convert()
for result in results["results"]["bindings"]:
print(result["n"]["value"])运行结果:
2046
Memoirs of a Geisha
荆轲刺秦王
大红灯笼高高挂
霸王别姬
活着
唐伯虎点秋香
秋菊打官司
菊豆
Hong gao liang
画魂
风月
Piao Liang Ma Ma
The Hand初始化Wrapper需要的参数是endpoint对外提供服务的链接,D2RQ默认的链接是“http://localhost:2020/sparql”。
总结
这篇文章简单地介绍了如何利用D2RQ开启SPARQL endpoint服务和两种进行交互的方式。D2RQ是以虚拟RDF图的方式来访问关系数据库,在访问频率不高,数据变动频繁的场景下,这种方式比较合适。对于访问频率比较高的场景(比如KBQA),将数据转为RDF再提供服务更为合适。接下来的实践篇我们将介绍如何利用Apache Jena,创建基于显式RDF数据的SPARQL endpoint;并展示,在加入推理机后,对数据进行本体推理我们可以得到额外的信息。