知识图谱(Knowledge Graph)是当前互联网最炙手可热的技术之一,它的典型应用场景就是搜索引擎,比如Google搜索,百度搜索。我们在百度搜索中输入问题“中国银行的总部在哪”,搜索的结果如下:

这便是知识图谱的典型应用,能够直接输出问题的答案。借助知识图谱,能够让搜索引擎更加高效,搜索结果更加精准,给用户带来更好的搜索体验和乐趣。
关于知识图谱的知识点和工具数不胜数,我们在学习时常常会感到无从下手,一片茫然。本文将尝试着介绍知识图谱的几个知识点——RDF、URI、URL和SPARQL,希望能以此为切入点,让读者对SPARQL有些感性的认识,至于知识图谱,则是更大更深的范围了,不是本文所能概括的。
什么是SPARQL?

SPARQL的英文全称为SPARQL Protocol and RDF Query Language,是为RDF开发的一种查询语言和数据获取协议,它是为W3C所开发的RDF数据模型所定义,但是可以用于任何可以用RDF来表示的信息资源。它于2008年1月15日正式成为一项W3C推荐标准,于2013年3月发布SPARQL1.1。
既然SPARQL是为是为RDF开发的一种查询语言,那么什么是RDF呢?
什么是RDF?
首先,RDF不是一种数据格式。
RDF的英语全称为Resource Description Framework,中文名称为资源描述框架。RDF是一种描述数据文件储存的数据模型,该数据模型通常描述由三个部分组成的事实,被称为三元组(triples)。三元组由主语(subject)、谓语(predicate)和宾语(object)组成,看上去很像一个简单的句子。比如:
| subject | predicate | object |
|---|---|---|
| richard | homeTel | (229)276-5135 |
| cindy | [email protected] |
以下为Turtle RDF格式的RDF文件,文件名为ex002.ttl,
# filename: ex002.ttl
@prefix ab: <http://learningsparql.com/ns/addressbook#> .
ab:richard ab:homeTel "(229) 276-5135" .
ab:richard ab:email "[email protected]" .
ab:cindy ab:homeTel "(245) 646-5488" .
ab:cindy ab:email "[email protected]" .
ab:craig ab:homeTel "(194) 966-1505" .
ab:craig ab:email "[email protected]" .
ab:craig ab:email "[email protected]" .#表示注释,@prefix行为前缀行,即为<http://learningsparql.com/ns/addressbook#>取一个前缀ab:,也就是别名,避免每次命名时都要写这个长长的字符,句子最后的.可写可不写,写上后便于阅读。另外,<http://learningsparql.com/ns/addressbook#>是URI,这个后面会介绍。
之后的每一行,都是一个三元组,分别是主语、谓语和宾语,带有前缀ab:。
URI和URL
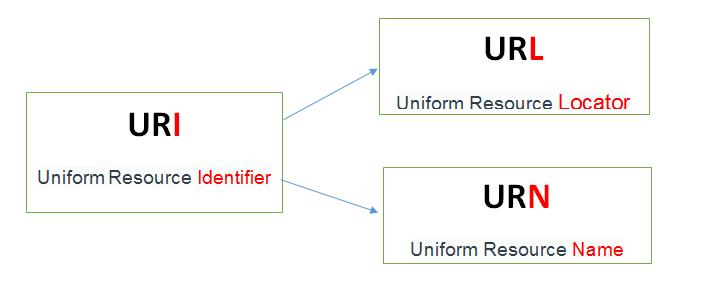
URI和URL是两个相近的概念,但URL只是URI的一种。
URL就是我们常说的网址,英文全称为Uniform Resource Locators,是统一资源定位符,对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。
URI的英语全称为Uniform Resource Identifier,是统一资源标识符。在RDF三元组中,主语、谓语必须属于某个特定的命名空间,避免相似的名字发生混淆,因此需要使用URI。
如何使用ARQ?
好了,在了解了上述的基本概念之后,我们需要实践一把,在这里,我们使用ARQ。
ARQ是SPARQL处理器。它是Apache Jena框架的一部分,是一个基于java的免费软件,其下载地址为:http://jena.apache.org/download/index.cgi。以Linux系统为例,我们下载文件apache-jena-3.11.0.zip,并将解压后的zip文件中的bin目录添加到环境变量中。添加方式如下:
- vim /etc/profile
- 在文件末尾添加命令:
export JENA_HOME=你的apache-jena-3.11.0路径
export PATH=$JENA_HOME/bin:$PATH- source /etc/porfile
- 运行命令
echo $JENA_HOME,如果能输出你的JENA路径,则表明添加该环境变量成功。
接着我们写好SPARQL查询语句(关于查询语句,会在后面的文章中介绍),文件名为ex003.rq,内容如下:
# filename: ex003.rq
PREFIX ab: <http://learningsparql.com/ns/addressbook#>
SELECT ?craig_email
WHERE
{ ab:craig ab:email ?craig_email . }简单对该查询语句做个说明:PREFIX ab: http://learningsparql.com/ns/addressbook# 表示使用哪个URI,并取别名。后续的查询语句类似于SQL,是对三元组做查询,?craig_email为变量,查询三元组中的宾语,用通俗的话来理解,就是查询craig的电子邮箱是什么?
运行命令:
arq --data ex002.ttl --query ex003.rq输出结果如下:(ex002.ttl文件见之前的描述)
--------------------------------
| craig_email |
================================
| "[email protected]" |
| "[email protected]" |
--------------------------------还可以查询三元组中的其他部分,这里不再讲述,后续会专门讲SPARQL查询语句的。
总结
在知识图谱的工具箱中,有很多图数据库,它们提供了很好的查询语句功能和可视化效果,比如Neo4j, Cayley,这次,我们可以学习下RDF和SPARQL,毕竟,SPARQL的查询能力和推理能力也是很强的哦~
期待下次关于SPARQL的分享~
注意:不妨了解下笔者的微信公众号: Python爬虫与算法(微信号为:easy_web_scrape), 欢迎大家关注~
参考文献
SPARQL百度百科:https://baike.baidu.com/item/SparQL/10956405?fr=aladdin
URL百度百科:https://baike.baidu.com/item/url
SPARQL维基百科:https://en.wikipedia.org/wiki/SPARQL
Apache Jena下载页面:http://jena.apache.org/download/index.cgi
书籍: Learning SPARQL,Bob DuCharme,Publisher: O'Reilly Media, Inc.
Learning SPARQL学习网址:http://www.learningsparql.com/