连接数据库
准备工作
楼主这里用的一个轻量级关系型数据库,MySQL (这里楼主安装MySQL的时候遇到了一个小问题,没有兼容服务器,根据这个帖子可以解决这个问题 分享 | 安装 mysql 报错 no compatible servers),操作界面使用的 HeidiSQL。

这里需要注意,我们这次连接数据库时需要安装 PyMySQL 的包进行连接,在下载之前可以先观看下 官方文档 中的介绍和使用方法,这里文档就说明兼容版本。

这里楼主用的是 iris 的数据集,记录了 150 朵花的数据。
链接: https://pan.baidu.com/s/1fVaNHMhygMvfTYGQLXqkrQ 密码: wqh9
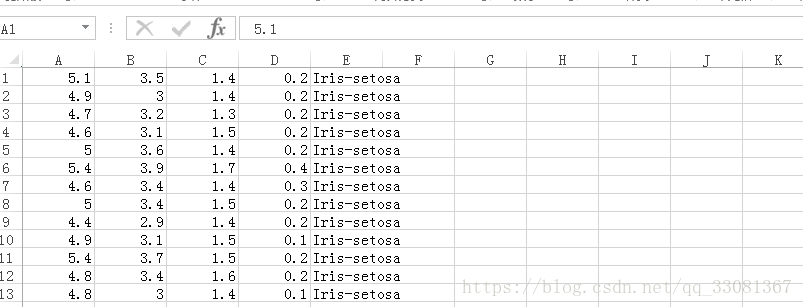
利用 heidiSQL 工具,把 csv 文件数据导入数据库
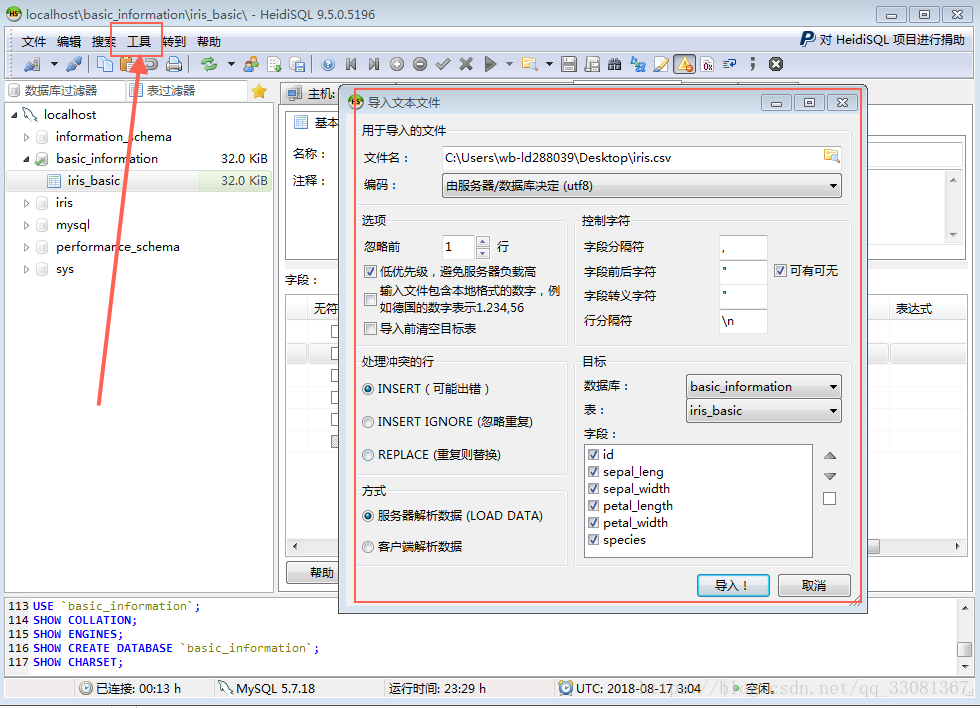
数据集中数据依次代表
Python 连接数据库
安装 PyMySQL
pip install PyMySQL
#推荐使用conda 来安装
conda install PyMySQL打开 Jupyter notebook 编写 Python 代码 :
import pymysql.cursors
# 连接数据库
# host:要连接的数据库的IP地址
# user:登录的账户名,如果登录的是最高权限账户则为root
# password:对应的密码
# db:要连接的数据库,如需要访问上节课存储的IRIS数据库,则输入'IRIS'
# charset:设置编码格式,如utf8mb4就是一个编码格式
# cursorclass:返回到Python的结果,以什么方式存储,如Dict.Cursor是以字典的方式存储
connection = pymysql.connect(host = '127.0.0.1', user = 'root',password = 'root',db = 'basic_information',cursorclass = pymysql.cursors.DictCursor)
try :
# 从数据库链接中得到cursor的数据结构
with connection.cursor() as cursor :
# 查询sql语句
sql= " SELECT * FROM `iris_basic` WHERE `id`= %s"
# 查询条件
cursor.execute(sql,('256',))
# 返回一条数据
result=cursor.fetchone()
# 返回多条数据
# result=cursor.fetchall()
print(result)
print(result['id'])
finally :
# 记得关闭连接
connection.close()
# 在之前建立的user表格基础上,插入新数据,这里使用了一个预编译的小技巧,避免每次都要重复写sql的句
# sql="INSERT INTO `USERS`(`email`,`password`) VALUES (%s,%s)"
# cursor.execute(sql,('[email protected]','very_secret'))
# 执行到这一行指令时才是真正改变了数据库,之前只是缓存在内存中
# connection.commit()
COMMIT:
1.注意过于频繁的commit会降低数据插入的效率,可以在多行insert之后一次性commit;2.autocommit选项:默认每一个insert操作都会触发commit操作方式,是在pymysql.connect的db参数后面,加一个autocommit=True参数
简单介绍两种不同的数据库
SQLite SQLite官方文档
- 文件型数据库
- 常用于应用程序存取数据
- GUI : DB Browser for SQLite
- Python :import sqlite3 ( Python 自带 )
相关准备
1.访问DB Browser for SQLite,在界面右端选择合适的安装程序
2.访问Kaggle-iris,下载整理好的iris的SQLite的数据集
3.在DB Browser中打开iris sqllite格式的数据库
Mongo DB
- NoSQL数据库
- Json格式
- GUI:Robo 3T
- Python: import PyMongo
随着数据存储需求的发展,非关系型数据库NoSQL拥有了越来越多的使用者,NoSQL并不是No-SQL,而是指Not Only SQL。
非关系型数据库的特点
- 没有固定的表结构
- 避免使用join操作
- NoSQL是基于键值对的,不需要经过SQL层的解析,性能较高
请阅读从关系型数据库到非关系型数据库,了解关系型数据库的瓶颈,以及非关系型数据库的发展历程
请阅读现在市场上的主流NoSQL数据库,扩展你对于数据库的了解
数据清理
- 格式转换
- 缺失数据
- 异常数据
- 数据标准化
格式转换
数据的原始储存形式未必适合Python数据处理
例:原始数据中在时间的一列储存了字符串,如20090609231247,代表2009年6月9日23点12分47秒。在代码需要将字符串转换为相应的Python中用于表示时间的数据结构,就能够直接实现减运算。
缺失数据
每条记录都可能在某些属性上缺失
例:在社交网络上爬取用户信息,有些用户并没有公开诸如他的性别或者年龄等信息,那我们收集过来的这些数据就是缺失的。
怎样应对缺失数据?
- 忽略有缺失数据的记录
- 直接把这个值标记为“未知”进行后续分析
- 利用平均值,最常出现的值等去填充
- (当然还有很多复杂的方法)
异常数据
出现不符合常识的数值列如
性别出现数值
住址GPS位于海上
处理方式可类比却还是数据
数据标准化
用户可自主输入的一些属性,可能出现实际是相同值,但输入不同,比如出生国家都是美国,可能US、USA、United States等各种写法。住址城市,一个城市可能有多个GPS地址对应,可根据城市范围统一。
数据清理实践:Airbnb
Pandas:它作为一种数据结构,它比较方便的读取一个数据库或者是一个CSB之类的数据文件的数据,然后形成它自带的一些数据结构,他核心的结构名字叫DataFrome。
Seaborn:主要是提供一些可视化功能
下载准备使用的数据集 Airbnb Dataset
Tips:养成处理数据集前,先看数据描述的习惯,会为你省下不少时间
# 并安装 Pandas & Seaborn 库
conda install Pandas
conda install seaborn
# 读取数据
import pandas
userse = pandas.read_csv('D:\countries_of_the_world.csv')
#首先需要进行的是对数据的基本查看
#第一行是属性的名称,index从0开始,NaN代表missing value
# 取数据前几条
userse.head()
# 取数据前3条
userse.head(3)
# 取数据尾部条
userse.tail()
# 解释成数字的属性
userse.describe()
# 可以告诉我们整个数据长得样子
userse.shape
# 从第 1 条数据到第 3 条数据的GDP
userse.loc[1:3,'GDP ($ per capita)']
# 取一个值的全部数据
userse['GDP ($ per capita)']
# 格式转换:转变为日期格式,可以实现时间的加减
# userse["date_account_created"] = pandas.to_datetime(users["date_account_created"])
# userse.loc[0,"date_account_created"]-users.loc[1,"date_account_created"]
#定义到时分秒的关系,设置format函数参数,针对一些非常规的数据
# userse["timestamp_first_active"] = pandas.to_datetime(users["timestamp_first_active"],format="%Y%m%d%H%M%S")
#缺失数据处理:查看去掉缺失值的数据
userse["GDP ($ per capita)"].dropna()
#画图,可以很直观的观察数据的异常值
import seaborn
%matplotlip inline
seaborn.distplot(userse["GDP ($ per capita)"].dropna())
seaborn.boxplot(userse["GDP ($ per capita)"].dropna())
#异常数据处理:筛选age<90以及>10
users_with_true_age=users[users["age"]<90]
users_with_true_age=users_with_true_age[users_with_true_age["age"]>10]补充知识
Pandas & Seaborn 库的补充
Pandas
Pandas逐渐成为了一个非常大的库,在数据处理问题方面表现优秀,是一个不可或缺的工具,Pandas中包含两个主要的数据结构:Series & DataFrame
请阅读:官方文档,官方文档永远是最好的学习材料,重点阅读:
- 10 Minutes to pandas,建议跟着学习手册操作一遍。重点阅读Pandas的不同数据结构 、 head,describe,index等函数来查看DataFrame 、 Merge DataFrame(Concat & Join & Append) 、Grouping 、 Reshaping,如果学有余力的话建议自学一下Time Series 的内容
- Working with Missing Data
- Computational tools中Statistical Functions 部分,掌握基本的统计功能的实现
- IO Tools (Text, CSV, HDF5, …),重点掌握如何读取CSV,JSON,以及如何应用参数实现数据的读取
- 请阅读VisualizationMatplotlib库是如何实现可视化,学会不同类型图对应的函数
最后可以通过查询Pandas速查手册中文版,在有需要的时候,迅速解决疑问
Seaborn
Seaborn是基于matplotlib的绘图库,可以制作更多更美观的图形,如Example gallery中也可以看到很多关于图像的示例。这个绘图库可以很好地辅助我们对数据进行第一步的观察
请阅读:Seaborn tutorial,阅读Style management & Plotting functions & Structured grids 这三块内容,重点掌握画图的函数,以实现画出不同类型的图像
数据预处理
请阅读:
- 数据挖掘中的数据预处理,本链接详细提供了关于数据清洗(值缺失、噪声) & 数据融合(实体识别,冗余和相关性分析)的方法,值得仔细阅读
- 数据预处理,了解更多关于数据预处理的方法,和背后的数学原理