论文阅读CTD+TLOC_Detecting Curve Text in the Wild_New Dataset and New Solution
这是一篇曲文检测的论文。场景文本的形状是多种多样的,要对任意形状的文本进行检测是费城重要的。因此曲文检测是场景文本检测的研究热点之一。
创新点
- 第一篇做曲文检测的论文,提出了一个数据集CTW-1500
- 使用14个点来表示曲文
- 结合CNN-RPN+RNN的检测方法做曲文检测,提出了一种基于多边形的曲线文本检测器(CTD)
CTW1500 数据集和注释
图像描述

CTW1500数据集包含1500个图像,10,751个边界框(3,530个是曲线边界框),每个图像至少有一个曲线文本。
此外,我们的数据集是多语言的,主要是中文和英文文本。
图像标记

我们单击标记为1,2,3,4的四个顶点,连接1和2、3和4,并创建十条等距参考线,帮助标记额外的10个点。使用等距线可以一定程度简化标记工作,减少主观干扰。
网络架构
本文方法基于RPN进行修改,除了学习text/non-text分类,多边形的bounding box回归(x1,y1,x2,y2),增加了14个点的回归,最后再进行后处理(去噪+nms)得到最终输出。

本文骨干网络采用ResNet-50,区域提议网络(RPN)和回归模块分别连接到骨干网络;RPN阶段,我们使用默认的矩形锚来粗略调用文本,而后者则精心调整提案以使其更加准确,回归网络总分三个分支
- 第一个text/non-text分支,普通的分类任务
- 第二个分支是整个曲文(多边形)的最外接正矩形bounding box的x1,y1,x2,y2回归任务
- 第三个分支是14个点的点坐标的回归任务。包括采用类似R-FCN方式进行PSAoIpooling、以及用RNN来增加上下文信息做平滑
regression输出
与Faster r-cnn类似,本文也回归了每个点的相对位置,使用外接矩形的最小x和最小y作为基准点。 因此,每个点的相对长度wi和hi(i∈1,2,…,14)大于零。 回归总数为32; 28是14点的偏移量,4是外接矩形的x,y最小值和最大值。 下面列出了14个偏移(dwi和dhi)的参数化:
使用32个值 = 14*2=28个坐标偏移量 + 多边形的boundingbox的4个值(x1, y1, x2, y2)

p∗ 和 p分别是真实和预测的偏移量,Wchr和Hchr分别是外接矩形的宽和高,
基本上,PSROIPooling(position-sensitive RoI Pooling)(检测框架R-FCN的主要创新点)用于预先判断和投票类概率和定位偏移,其将每个RoI均匀地划分为p×p个箱以估计位置信息。输入卷积层的维度应为(1类)p2,因此PSROIPooling可以为每个类别生成p2分数图。对于横向和纵向偏移预测,我们删除背景类定位分数图并使用7×7 bin,因此输入卷积尺寸为14×7×7。 (i; j)-th bin(0 <i; j <p-1)的每个值通过使用平均池化从第(i; j)个得分图中的对应位置计算:
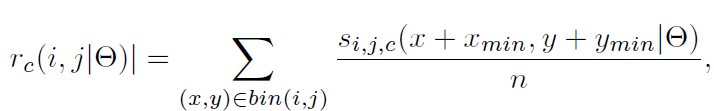
循环横向和纵向偏移连接(TLOC)
为了提高检测性能,我们将横向和纵向分支分开以预测用于定位文本区域的偏移。直观地,每个点由上一个和下一个点以及文本区域重新限制。例如,在图3的情况下,第六标记点的偏移宽度应该大于第五点并且小于第七点。
独立地预测每个偏移可能导致文本区域不平滑,以及它可能带来更多错误检测。因此,我们认为每个点的宽度/高度都有相关的上下文信息,故使用RNN来学习它们潜在的特征。我们将此方法命名为循环横向和纵向偏移连接(TLOC)。

为了采用TLOC,把PSROIPooling的输出来编码偏移的上下文信息。**以宽度偏移分支为例:**首先,PSROIPooling为每个rpoposal的w1,…,w14输出14个p2得分图,并且第i个得分图的p2个bin具有来自各个位置的p^2值,其可被编码为wi的特征;然后RNN将每个点的宽度偏移特征作为顺序输入,并且反复更新隐藏层内的固有状态Lt,即

其中Ot∈P2是相应的PSRoIPooling输出通道的第t个预测偏移量。 Lt是从当前输入(Ot)和以Lt-1编码的上一个状态计算的循环内部状态。 通过使用非线性函数φ计算递归,其中我们采用双向长短期记忆(BLSTM)架构作为我们的RNN。 我们凭经验使用256D BLSTM隐藏层,因此Lt是256的矢量。 BLSTM的输出是14维1×256矢量,然后由(1×256)的核进行全局池化,最后输出最终预测。
损失函数
在训练阶段,多任务损失函数如下:

其中N是与特定重叠范围匹配的正负proposal的数量,Np是正proposal的数量。 此外,λ和μ是衡量分类和检测损失之间重要性的平衡因子(Lcls代表分类损失函数; Lloc是定位损失函数,可以是平滑的L1损失或平滑Ln损失)。 实际上,我们将λ设置为3甚至更多以平衡具有更多目标的定位损失。 此外,(c,b,w,h)分别代表预测的类,估计的边界框,宽度和高度偏移,(c *,b *,w *,h *)表示相应的真实状况。
长边插值
对于非曲面文本,本文提出了一种简单但有效的长边插值技术,它使CTD成为一种通用方法。

在现有的数据集中,多为有四个顶点的边界框,在长边均匀的插入10个等分点。
Polygonal Post Processing多边形后处理
非多边形抑制(NPS)
误报检测结果是限制文本检测性能的重要原因之一。 但是,在CTD中,一些差异误报将出现无效形状(对于有效多边形,没有任何交叉边)。 另外,几乎没有任何场景文本与交叉侧出现,这些无效多边形几乎无法识别。 因此,我们简单地抑制所有这些无效多边形,并将其命名为非多边形抑制(NPS),这可以略微提高准确性而不会影响召回率。
多边形非最大抑制(PNMS)
在本文中,我们还通过计算多边形之间的重叠区域来改进NMS,称为多边形非最大抑制(PNMS),这在以下实验中被证明是有效的。
实验结果
CTW1500

不同的TLOC和PNMS设置

实验结果图例

第四列列出了一些较差的结果,最后一列的图像来自其他数据集,用于进一步测试泛化能力
总结
本文提出了一种新的数据集CTW1500,它是一种新的数据集,主要由曲线文本构成。
提出了一种新的CTD方法。通过设计横向和纵向偏移连接**(TLOC)方法**,CTD可以与RNN无缝连接,从而显着提高了检测性能。
兼容性:提出了一种简单但有效的长边插值技术,它使CTD成为一种通用方法,也可以用矩形或四边形边界框进行训练而无需额外的手动操作。
最后,我们设计了两种后处理方法,这些方法也证明是有效的。