这篇文章是在自然场景文本处理中针对弯曲问题做的非常好的一篇文章。后面打算先用这篇论文来做实验。
paper:https://arxiv.org/abs/1712.02170
github:https://github.com/Yuliang-Liu/Curve-Text-Detector
一、摘要
场景文本检测近年来取得了很大进展。 检测方式从轴对齐矩形演变为旋转矩形,进一步演变为四边形。 但是,当前数据集包含非常少的曲线文本,这种现象可以在场景图像(如招牌,产品名称等)中广泛观察到。 为了提出在广泛的阅读曲线文本的问题,在本文中,我们构建了一个名为CTW1500的曲线文本数据集,其中包括1,500个图像中的超过10k文本注释(1000个用于训练,500个用于测试)。 基于该数据集,我们开创性地提出了一种基于多边形的曲线文本检测器(CTD),它可以直接检测曲线文本而无需经验组合。此外,通过无缝地集成循环横向和纵向偏移连接(TLOC),所提出的方法可以是端对端可训练的,以学习位置偏移之间的固有连接。这允许CTD探索上下文信息而不是独立地预测点,从而导致更平滑和准确的检测。我们还提出了两种简单但有效的后处理方法,即非多边抑制(NPS)和多边形非最大抑制(PNMS),以进一步提高检测精度。此外,本文提出的方法是以通用的方式设计的,也可以用矩形或四边形边界框进行训练而无需额外的努力。 CTW-1500的实验结果表明,我们只使用轻骨架的方法可以大大优于最先进的方法。 通过仅在曲线或非曲线子集中进行评估,CTD + TLOC仍然可以获得最佳结果。 代码可在https://github.com/Yuliang-Liu/Curve-Text-Detector获得。
二、介绍
据观察,来自新兴数据集的文本边界框的标签也从矩形到柔性四边形发展。场景文本检测方法的进步也从基于轴对齐的矩形到基于旋转的矩形和基于四边形而变化。 一旦边界框变得更紧凑和灵活,它可以提高检测置信度,降低被后处理抑制的风险,并有利于后续的文本识别。
为了识别场景文本,强烈要求文本可以提前紧密且稳健地进行本地化。然而,当前数据集具有非常少的曲线文本,并且用四边形单独的矩形标记这样的文本是有缺陷的。 例如,如图1所示,使用曲线边界框有三个显着的优点:
•避免不必要的重叠
•减少背景噪音。
•避免多个文本行
根据我们的观察,对于所有类型的曲线文本区域,14点多边形足以定位它们,如图1和图2所示。通过使用引用的等分线,它不需要太多的人力来标记。
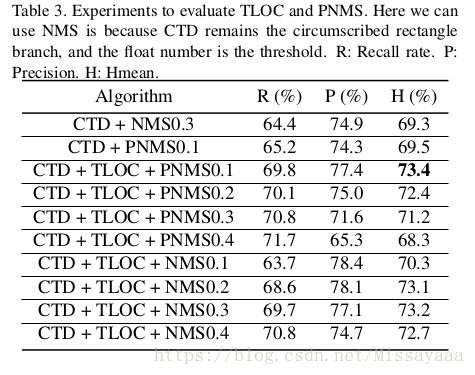
与传统的检测方法不同,CTD将分支的宽度/高度偏移预测分开,可以在速度为13 FPS的情况下以低于4GB的视频内存运行。 此外,网络架构可以与我们提出的巧妙方法无缝集成,即横向和纵向偏移连接(TLOC),它使用RNN来学习定位点之间的固有连接,使检测更加准确和平滑。 CTD也被设计为通用方法,可以使用矩形和四边形边界框进行训练,无需额外的手动标签。 提出了两种简单但有效的后处理方法,即非多边形抑制(NPS)和多边形非最大抑制(PNMS),以进一步加强CTD的泛化能力。
本文提供标签工具手动标记文本,以及标注曲线文本的方法。
3、CTW1500 Dataset and Annotation
数据描述。 CTW1500数据集包含1500个图像,10,751个边界框(3,530个是曲线边界框),每个图像至少有一个曲线文本。 这些图像是从互联网手动收集的,图像库如谷歌Open-Image [18]和我们自己的手机摄像头收集的数据,其中还包含大量水平和多向文本。 图像的分布是多种多样的,包括室内,室外,天生数字,模糊,透视畸变文本等。 此外,我们的数据集是多语言的,主要是中文和英文文本。
我们使用我们的标签工具手动标记文本。对于标记水平或四边形的文本,只需要两次或四次点击。为了包围曲线文本,我们创建十条等距参考线以帮助标记额外的10个点(我们实际上发现额外的10个点足以标记所有类型的 曲线文字如图2所示。 我们使用等距线的原因是为了简化标记工作,减少主观干扰。 为了评估定位性能,我们只需遵循PASCAL VOC协议[7],该协议使用0.5 IoU阈值来确定真或假阳性。 唯一的区别是我们计算多边形之间的精确交叉(IoU)而不是轴对齐的矩形。
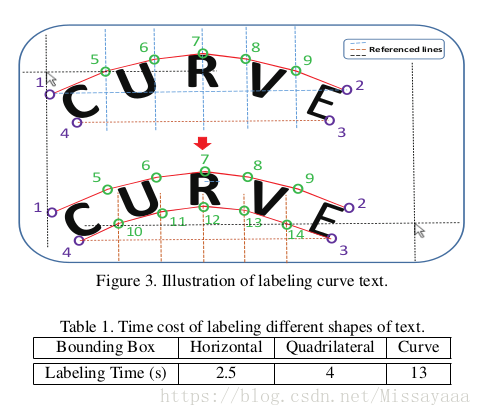
标记过程如图3所示。首先,我们单击标记为1,2,3,4的四个顶点,并自动创建引用的虚线(蓝色)。 将鼠标的一条参考线(水平和垂直黑色虚线)移动到适当的位置(两条参考线的交点),然后单击以确定下一个点,依此类推剩余点。 我们粗略计算表1中三种形状文本的标记时间,其中显示标记一条曲线文本比使用四边形标记消耗大约三倍的时间。 可以从https://github.com/Yuliang-Liu/Curve-Text-Detector下载CTW1500数据集。
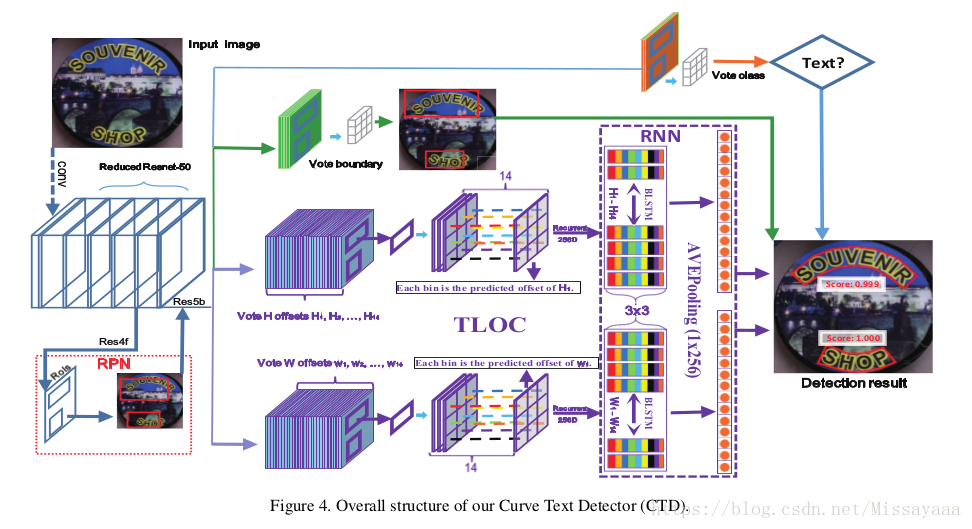
4、网络框架:
我们CTD的整体架构如图4所示,它可以分为三个部分:骨骼,RPN和回归模块。 Backbone通常采用流行的ImageNet [5]预训练模型,然后使用相应的模型进行微调,如VGG-16,ResNet 等。 区域提议网络(RPN)和回归模块分别连接到骨干网; 前者产生粗略回忆文本的提议,而后者则精心调整提案以使其更加严格。
在本文中,我们使用简化的ResNet-50(简单地删除最后一个残余块)作为我们的主干,这需要更少的内存并且可以更快。 在RPN阶段,我们使用默认的矩形锚来粗略调用文本,但我们设置了一个非常宽松的RPN-NMS阈值以避免过早抑制。 为了检测具有多边形的曲线文本,CTD只需要通过添加曲线定位点来修改回归模块,这受到DMPNet [21]和East [38]的启发,采用四边形回归分支与外接矩形回归分离。 矩形分支可以很容易地通过网络学习并让它快速转换,这也可以粗略地检测高级文本区域并减轻后续行为回归。 相反,四边形分支提供更强的监督,以指导网络更准确。
与[25,21]类似,我们也回归每个点的相对位置。 与[21]不同,我们使用外接矩形的最小x和最小y作为基准点。 因此,每个点的相对长度w i和h i(i∈1,2,…,14)大于零,这在实践中更容易训练。 此外,我们分别预测偏移w和h,这不仅可以减少参数,而且可以更加合理地进行顺序学习,如以下小节所述。 回归项目总数为32; 28是14点的偏移量,4是外接矩形的x,y最小值和最大值。 下面列出了14个偏移(d w i和d h i)的参数化:
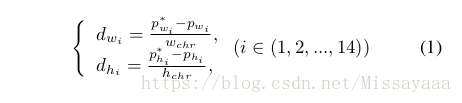
其中,p *和p分别是基础事实和预测偏移。 此外,w chr和h chr是外接矩形的宽度和高度。 对于边界回归,我们遵循与更快的R-CNN相同[25]。 值得注意的是,28个值足以确定14个点的位置,但在相对回归模式中,32个值可以更容易地检索剩余的14个点并提供更强的监督。
由于篇幅原因,剩下推理部分这里就不阐述了。

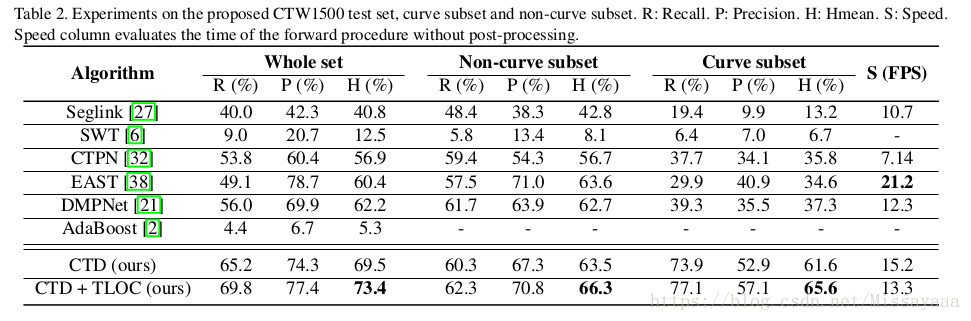
4、实验结果